

4.实验设置&数据集
4.1数据集设置
该研究使用了三个公开EEG情绪识别数据集:DEAP、SEED、SEED-IV
DEAP数据集
| 字段 | 内容 | 说明 |
|---|---|---|
| Dataset | DEAP | 一个经典的情绪识别EEG数据集(Database for Emotion Analysis using Physiological signals)。 |
| No. of Patients | 32 | 共32位被试参与。 |
| Fs (Hz) | 128 | EEG信号的采样率为128 Hz(说明该表采用的是降采样版本,原始DEAP为512 Hz)。 |
| Data shape | 40 × 32 × 8064 | 数据结构为:40个试次(trials)× 32个通道(channels)× 每段信号8064个采样点。 |
| Cat. No. | 4 | 情绪类别共4类(通常基于“愉悦–唤醒”二维情绪空间划分:高/低唤醒、高/低愉悦)。 |
SEED数据集
| 字段 | 内容 | 说明 |
|---|---|---|
| Dataset | SEED | 上海交通大学(SJTU)Brain-Like Computing 实验室采集的情绪 EEG 数据集。 |
| No. of Patients | 15 | 共15名受试者。 |
| Fs (Hz) | 200 | EEG采样频率为200 Hz。 |
| Data shape | 3 × 15 × 62 × N | 数据结构为:3个实验会话(sessions)× 15个试次(trials)× 62个通道 × N个时间采样点(长度可变)。 |
| Cat. No. | 3 | 情绪分为3类:积极、消极、中性(positive / negative / neutral)。 |
SEED-IV数据集
| 字段 | 内容 | 说明 |
|---|---|---|
| Dataset | SEED-IV | 同样由SJTU采集,是SEED的扩展版。 |
| No. of Patients | 15 | 15位被试。 |
| Fs (Hz) | 200 | 采样率同样为200 Hz。 |
| Data shape | 3 × 24 × 62 × N | 数据结构为:3个实验会话 × 24个试次 × 62通道 × N采样点。 |
| Cat. No. | 4 | 情绪分为4类:快乐、悲伤、恐惧、中性(happy / sad / fear / neutral)。 |
知识补充:情绪二维模型(Valence–Arousal Model)
心理学家 Russell(1980)提出了一个二维情绪环模型(Circumplex Model of Affect),认为情绪可以用两个连续变量来表示
| 维度 | 中文名 | 含义 | 范围 | 举例 |
|---|---|---|---|---|
| Valence(效价) | 情绪愉悦度 / 情绪正负性 | 表示情绪的“正面”或“负面”程度。 | 低(负面)→ 高(正面) | 悲伤(低效价) 😢 → 快乐(高效价) 😄 |
| Arousal(唤醒度) | 情绪激活度 / 兴奋水平 | 表示个体在情绪状态下的生理激活程度或紧张程度。 | 低(平静)→ 高(兴奋) | 困倦(低唤醒) 😴 → 激动(高唤醒) 😃 |
论文中提出根据效价(valence)和唤醒度(arousal)的取值,将样本标签分为四组:
- I(arousal > 4.5 且 valence > 4.5)
- II(arousal ≤ 4.5 且 valence > 4.5)
- III(valence ≤ 4.5 且 arousal ≤ 4.5)
- IV(arousal > 4.5 且 valence ≤ 4.5)
这就是 DEAP 数据集将情绪分成四类的依据:
| 类别 | 条件 | 对应情绪倾向 |
|---|---|---|
| I | 高唤醒 + 高效价 | 兴奋、快乐 |
| II | 低唤醒 + 高效价 | 平静、满意 |
| III | 低唤醒 + 低效价 | 悲伤、抑郁 |
| IV | 高唤醒 + 低效价 | 愤怒、紧张 |
4.2模型分类预处理
论文的整个实验由以下三个部分组成:
模型训练(Model training):包含 sample pairing(样本配对)、data generator(数据生成器)、contrastive loss(对比损失),训练EEGPT以获得time-invariant和time-specific组件。
数据生成(Data Generation):用训练好的EEGPT生成时间不变/时间特异的EEG数据作为数据增强(augmentation)
模型分类(Classification Procedure):将原始EEG+生成的augmented EEG组合输入到多种DL模型(EEGNet、DeepConvNet、ShallowConvNet、EEGConformer、EEGPTclf)执行情绪分类任务(emotion recognition)
因此在模型分类阶段,首先对原始EEG和生成的augmented EEG进行预处理操作:
1.对EEG(原始+augmented)做频域变换:短时傅里叶变换(STFT)
论文中使用:512点的STFT、1秒的Hanning窗、不重叠
目的是将EEG的时域信号变成频谱
2.计算5个频段的Differential Entropy(DE)特征
五个频段分别是:
| 频段 | 含义 |
|---|---|
| delta | 1–4 Hz |
| theta | 4–8 Hz |
| alpha | 8–13 Hz |
| beta | 13–30 Hz |
| gamma | 30–50 Hz |
DE(差分熵)是频域能量的一个稳定统计表示,适合情绪识别
3.每个 1 秒片段 → 每个 channel → 得到 5 个 DE 特征
假设EEG有n个通道:每秒的EEG分成了n条channel,每条channel计算 delta / theta / alpha / beta / gamma 共 5 个值,所以1秒的数据变成了一个n×5的特征矩阵
例如SEED/SEED-IV则是62通道 → 62×5,最后将这些DE特征构成DL模型的输入
| 模型名称 | 模型类型 | 核心结构特点 | 优点 | 在论文中的作用 |
|---|---|---|---|---|
| EEGNet | 轻量级 CNN | Depthwise + Separable Conv;专门针对 EEG 信号设计 | 参数少、速度快、对噪声鲁棒 | 作为轻量级基线模型,用于验证增强数据在小网络上的有效性 |
| DeepConvNet | 深层 CNN | 多层卷积(强调时间与空间特征);强表达能力 | 适合复杂 EEG 模式分类,性能较强 | 用来测试增强数据对深层网络的性能提升 |
| ShallowConvNet | 浅层 CNN | 较少的卷积层;更注重低频节律特征 | 不易过拟合;适合频域(DE)特征 | 检验增强数据在浅层结构下是否稳定提升 |
| EEGConformer | CNN + Transformer(Conformer) | 卷积提取局部特征 + 注意力捕捉时序依赖 | 能处理长程依赖,适合复杂情绪分类 | 代表最新架构,验证增强数据在先进模型上的效果 |
| EEGPTclf | 基于 EEGPT 的分类模型 | 使用 EEGPT 预训练的高维表示 + 分类头 | 跨被试泛化能力强,是论文主力模型 | 证明 TISIG 生成的数据在自家模型中效果最优 |
4.3实验细节设置
论文首先说明了实验是可以不依赖集群复现的,但是没有给复现的代码(?)
给出了CLTISI(EEGPT)训练的超参数(EEGPT预训练阶段)
DEAP、SEED、SEED-IV三个数据集的预处理方式
- 去除无效时间段(如 DEAP前3秒)
- 按固定长度划分非重叠分段
- 将通道映射为8×9的头皮拓扑结构
最后形成了统一的输入结构:\(\mathbb{R}^{(8 \times 9) \times T}\),用于后续深度学习模型训练
所有用于情绪分类的 DL 模型(EEGNet、DeepConvNet、ShallowConvNet、EEGConformer、EEGPTclf)都使用相同的训练设定(例如优化器、Epochs、Learning rate等)
关于batch size:EEGNet/DeepConvNet/ShallowConvNet/EEGConformer使用的batch size为64,而EEGPTclf(分类头)使用的batch size为30
4.4实验评估指标
实验评价的三大方向:数据生成是否能提升模型泛化能力?CLITISI训练策略是否有效?对“新情绪刺激”的适应能力?
1.关于数据生成是否能提升模型泛化能力
(变量)数据输入分为:“不使用生成数据 (原始 EEG)”和“使用生成数据(原始 + augmented)”
使用的若干主流EEG分类模型:EEGNet、DeepConvNet、ShallowConvNet、EEGConformer。在此基础上,作者还把自己预训练的 Backbone 加上分类头构成 EEGPTclf 作为自家分类器进行对比。
评价协议:LOSO(Leave-One-Subject-Out)是一种数据划分方式,用于确保模型在测试时遇到的被试(subject)是训练阶段没有见过的,从而验证模型是否具有跨被试泛化能力
2.CLTISI训练策略的有效性
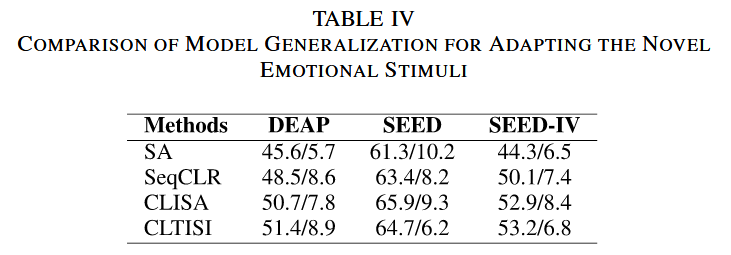
使用CLTISI和其他几种基线训练策略用来预训练EEGPT,基线包括:Subspace Alignment(SA)(以对齐为主)、SeqCLR(另一种序列对比学习)、以及CLISA(论文基于此方法进行改进的CLTISI),不同策略最后导致训练出来的EEGPT模型不一样,因此生成的augmented EEG质量也会不一样,后续会采用下游情绪分类任务的泛化性能(包括LOSO跨被试与跨刺激验证)作为生成数据有效性的核心评估标准
3.对"新情绪刺激(cross-stimuli)"的适应能力
Cross-stimuli 验证要求模型在从未见过的情绪刺激上进行预测,这是比跨被试(LOSO)更严格的泛化测试。若模型仍能维持高性能,则表示其学习到的是与情绪本质相关的、与具体刺激无关的普适特征。
此外,根据 10 折交叉验证的样本选择策略,我们使用训练被试中 9/10 的试次(trials) 来训练 EEGPT 模型,而测试被试中剩余的试次则用于最终的测试过程。
什么是10折交叉验证?
把数据集平均分成10份(称为“折” folds):
每次取其中1份作为测试集,剩下9份作为训练集,这个过程重复10次,每份数据都轮流当一次测试集,最后把这10次的测试结果取平均,作为模型的最终性能
4.5深度学习模型的特征可视化
什么是Grad-CAM?
Grad-CAM 是一种基于梯度的可解释性可视化方法,通过计算不同特征图对目标类别预测的贡献,生成热力图展示模型在分类决策中关注的关键空间位置或通道区域。在 EEG 情绪识别中,它用于揭示模型关注的脑区与频谱特征,从而评估模型学习到的生理合理性和泛化能力。
论文用 Grad-CAM 技术对深度学习模型进行可视化,以进一步理解模型在情绪分类任务中所关注的 EEG 时空特征。具体而言,我们从 EEGPTclf 模型的最后一个 Transformer 块中提取输出特征图,并计算各类别情绪(正向、负向与中性)的类别激活图(Class Activation Maps, CAMs)。这些激活图能够反映模型在做出情绪分类决策时所依赖的关键空间区域。
5.实验结果
1.数据生成在提升模型性能方面的有效性
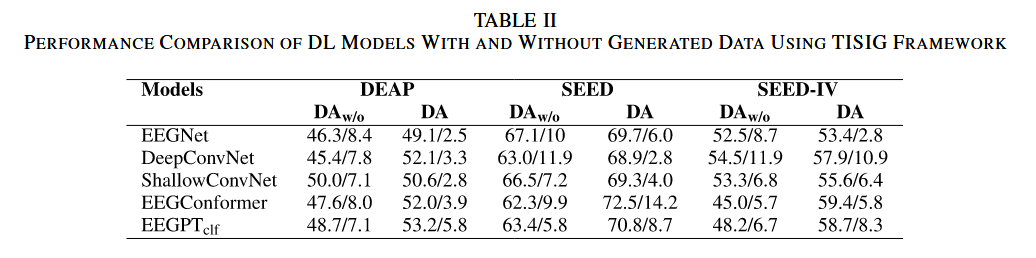
纵坐标:model
横坐标:\(\text{DA}_{\text{w/o}}\)(使用TISIG框架生成数据后的实验状态),DA(无生成数据的原始实验状态)
表格内容:“准确率/标准差”
与纯卷积架构的深度学习模型相比,EEGConformer 和 EEGPTclf 均表现出更显著的提升。这表明,数据生成对增强具有更复杂架构的模型能带来更大收益。此外,考虑 DEAP 和 SEED-IV 数据集涉及四类分类任务的分类性能时,深度学习模型在 SEED 数据集上取得了最高的平均准确率。这表明,在该特定数据集上,模型更能捕捉与正性、负性和中性情绪相关的特征表示。
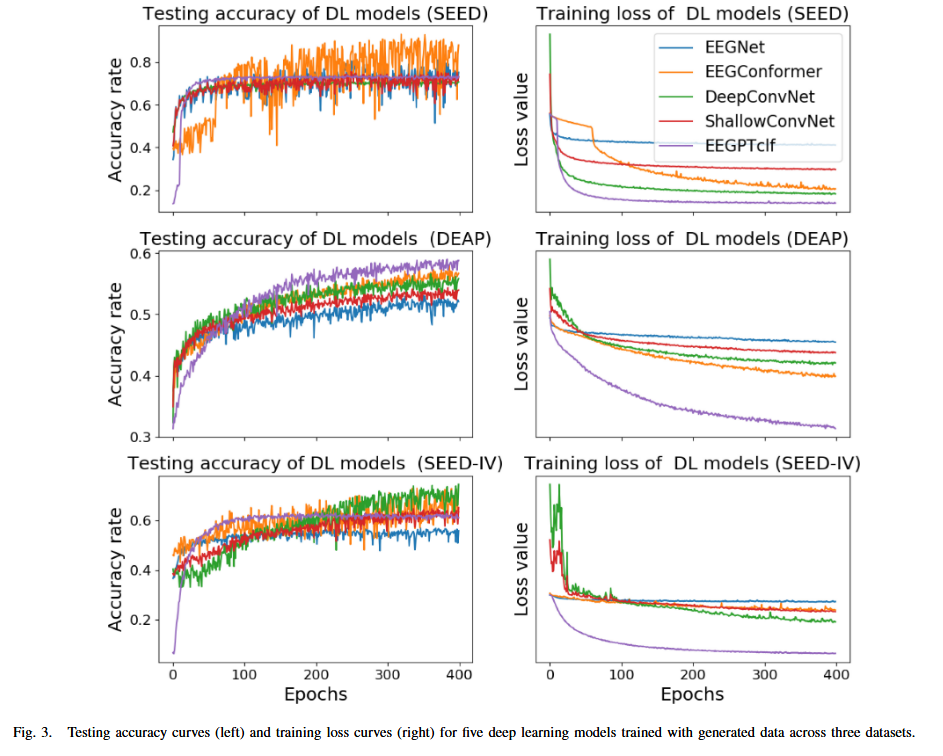
横坐标:Epochs(训练轮次,范围0-400)
纵坐标:左侧子图为Accuracy rate准确率,衡量模型在测试集上的情绪识别准确率;右侧子图为Loss value损失值,反映模型在训练集上的预测误差,损失越低说明模型拟合效果越好。
子图:分组为3组,对应3个数据集
结果分析:与其他模型相比,EEGPTclf的测试准确率曲线展现出快速收敛性,这表明EEGPTclf具备更优的能力,这种加速收敛可归因于其对3D卷积操作的利用,该操作是模型能够处理3D输入。此外EEGPTclf与EEGConformer对比,EEGPTclf的标准差呈现相对一致的趋势。这表明,在不同数据集和条件下,EEGPTclf模型的性能波动相对稳定。
2.基于 CLTISI 的模型训练策略的有效性
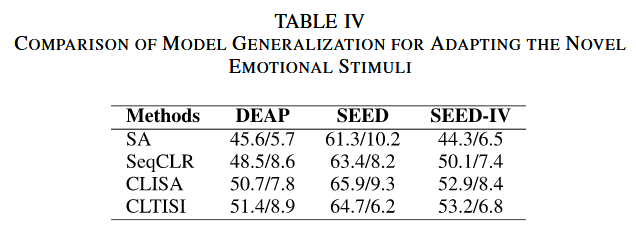
纵坐标:4种不同的模型训练策略,代表不同的训练方法论
横坐标:3 个用于 EEG 情绪识别的公开基准数据集
表格内容:准确率/标准差(如 “50.3/10.1” 表示该策略在对应数据集上的准确率为 50.3%,标准差为 10.1)
分析:不同训练策略去训练得到不同的EEGPT模型,这些模型生成增强数据(augmented EEG),然后统一的情绪分类任务中验证性能。在所有数据集上始终呈现中等性能。实验结果表明,本文提出的对比学习策略(CLTISI、CLISA)性能更优,优于两种跨被试对齐方法(SA 和 SeqCLR)。
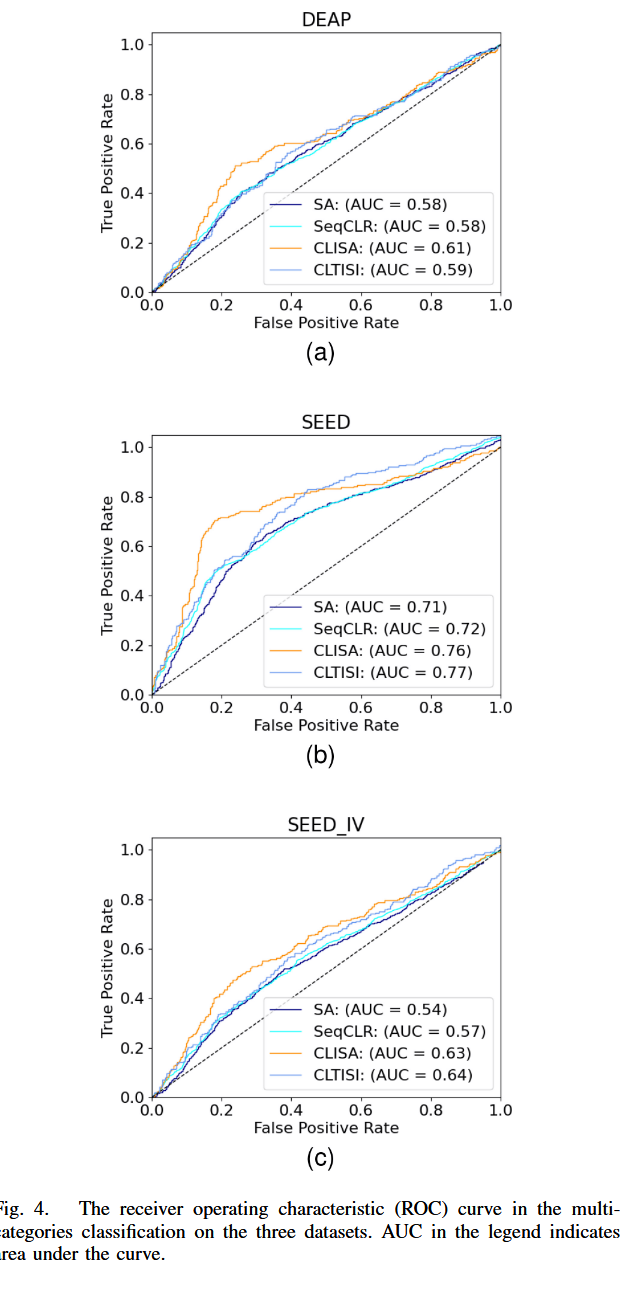
横坐标:False Positive Rate(假阳性率),表示 “被错误分类为正类的负样本比例”,范围 0-1。
纵坐标:True Positive Rate(真阳性率),表示 “被正确分类为正类的正样本比例”,范围 0-1。
图中虚线为 “随机猜测线”(对角线),若模型曲线接近该线,说明性能与随机猜测无异;曲线越远离虚线且向上凸,模型性能越好。
子图分组:数据集维度
图 4 分为3 个子图,分别对应三个 EEG 情绪识别数据集:
- DEAP 数据集:含 4 类情绪(快乐、悲伤、恐惧、中立)
- SEED 数据集:含 3 类情绪(正性、负性、中性)
- SEED-IV 数据集:含 4 类情绪(高兴、悲伤、厌恶、中立)
AUC(曲线下面积,AUC 越接近 1,模型分类性能越好)
各数据集性能对比:
(a) DEAP 数据集
AUC 对比:CLISA(0.61)> CLTISI(0.59)> SA(0.58)= SeqCLR(0.58)。
曲线趋势:CLISA 和 CLTISI 的曲线明显高于随机猜测线,且 CLISA 的曲线更 “陡峭”,说明在 DEAP 数据集上,CLISA 对正类样本的识别能力更优。
(b) SEED 数据集
AUC 对比:CLTISI(0.77)> CLISA(0.76)> SeqCLR(0.72)> SA(0.71)。
曲线趋势:所有策略的曲线均远离随机猜测线,其中 CLTISI 和 CLISA 的曲线几乎重合且处于最上方,说明在 SEED 数据集(3 类情绪,分类难度相对低)上,两种对比学习策略(CLISA、CLTISI)的分类性能显著优于 SA 和 SeqCLR。
(c) SEED-IV 数据集
AUC 对比:CLTISI(0.64)> CLISA(0.63)> SeqCLR(0.57)> SA(0.54)。
曲线趋势:CLTISI 和 CLISA 的曲线明显高于 SeqCLR 和 SA,且 CLTISI 的曲线更贴近 “左上角”(真阳性率高、假阳性率低),说明在标签更细分的 SEED-IV 数据集上,CLTISI 的分类准确性和稳定性更优。
3.模型对新情绪刺激的泛化能力
分析:尽管与使用所有刺激训练的模型相比,性能有所下降,但 CLTISI 在三类数据集上的表现与 CLISA 相当且保持领先。这些结果表明,采用 CLTISI 策略训练的模型不仅避免了对对比学习中遇到的刺激的过拟合或记忆,还展现出了稳健的泛化能力。这说明 CLTISI 使模型能够有效适应新的情绪刺激,体现了其强大的泛化能力。
4.关键区域可视化与特征分析
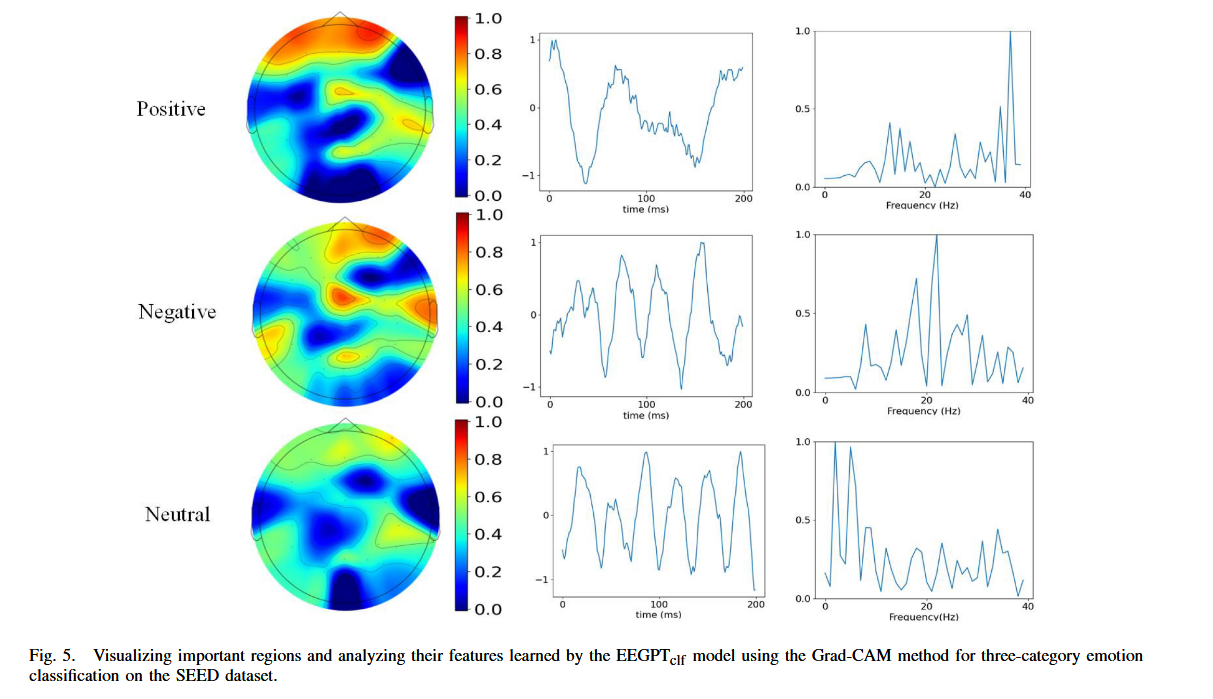
(1). 情绪类别:Positive(正性)、Negative(负性)、Neutral(中性)
图 5 按 SEED 数据集的三类情绪划分,每一行对应一种情绪,分别分析其在脑电信号中的特征表现。
(2). 可视化维度:脑区激活、时域特征、频域特征
每一行包含三个子图,从 “空间 - 时间 - 频率” 三个维度解析情绪相关的脑电特征:
左子图(脑区激活图):这是通过 Grad-CAM 方法生成的脑区重要性热力图(颜色越红,代表该脑区对情绪分类的贡献越大)。
Positive(正性):红色区域集中在左半球,说明左脑区域对识别正性情绪更关键。
Negative(负性):红色区域集中在右半球,体现右脑在负性情绪识别中的主导作用。
Neutral(中性):红色区域主要分布在前额叶和顶叶皮层,但整体激活强度低于正性、负性情绪(颜色更偏蓝绿),说明中性情绪的脑区贡献相对较弱。
中子图(时域特征):横坐标为time (ms)(时间,毫秒级),纵坐标为信号幅度,展示关键脑区电信号的时间域波动规律。
Positive:信号在时间维度上呈现特定的波动模式,可反映正性情绪下脑电的动态变化节奏。
Negative:波动模式与正性有明显差异,体现负性情绪的时域特征独特性。
Neutral:时域波动相对平缓,进一步说明中性情绪的脑电信号 “辨识度” 较低。
右子图(频域特征):横坐标为Frequency (Hz)(频率,赫兹),纵坐标为功率或能量,展示关键脑区电信号的频率域响应特性。
Positive:在35-40Hz频段有显著峰值,说明正性情绪与高频脑电活动(如 γ 波)强相关。
Negative:在约 20Hz频段有明显峰值,体现负性情绪与中频段脑电活动(如 β 波)的关联。
Neutral:频域峰值分布较分散,无明显主导频段,符合其 “情绪中性” 的特征。
结果:图5通过 “空间 - 时间 - 频率” 的多维度可视化,清晰展示了EEGPTclf模型学习到的情绪特异性脑电特征。正性情绪依赖左半球 + 35-40Hz 高频活动;负性情绪依赖右半球 + 20Hz 中频活动;中性情绪依赖前额叶 / 顶叶皮层,但特征辨识度较低。同时解释了为何 SEED 数据集上模型分类性能最优(三类情绪的特征差异更明确)。
6.讨论
关于研究发现:本文提出的 TISIG 数据生成框架和 CLTISI 训练策略,在 DEAP、SEED、SEED-IV 数据集上显著提升了 EEG 情绪识别模型的性能,且复杂架构模型(如 EEGPT、EEGConformer)收益更明显。
关于方法创新:EEGPT 模型的 3D 卷积设计使其在训练收敛速度和特征学习效率上表现突出,Grad-CAM 可视化验证了模型学到的情绪特征具有脑区偏侧化(正左负右)和频率特异性(正 35-40Hz、负 20Hz)的神经学合理性。
关于局限性:研究仅基于三个公开数据集,模型复杂度较高,未来需拓展数据集类型并探索轻量化设计。
关于未来方向:可探索多模态融合、深化自监督学习、推进临床情绪障碍辅助诊断等方向,进一步提升方法的普适性和实用价值。
总结:在本研究中,我们提出了一种适用于脑电(EEG)应用的新型数据生成流程(TISIG)。该流程生成的合成脑电数据被证明可有效提升深度学习(DL)模型在三个开源脑电数据集上的泛化能力。与未使用合成数据训练的深度学习模型相比,EEGPTclf 的平均准确率提升凸显了生成数据的积极影响,在 DEAP、SEED 和 SEED-IV 数据集上分别提升了 4.5%、7.4% 和 10.5%。此外,我们还验证了该模型相较于其他对比方法,具备对未见过的情绪刺激的泛化能力。通过对模型识别出的关键区域进行可视化,我们也展示了其在揭示情绪神经机制方面的潜在价值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号