

前言:写博客记录我的学习过程,该笔记代码来源:【注意力机制与输出预测(LLM:从零到一)【5】】 https://www.bilibili.com/video/BV1fr421s7Kp/?share_source=copy_web&vd_source=223740e4230bb50e6f2bd500f9c443f1
跟大家推荐b站up主:LLM张老师,适合新手入门学习大模型知识
本节知识点——多头注意力机制(Multi-Head Attention)
多头注意力机制通过多个"头"并行计算注意力,能够让模型同时从不同的表示子空间中去学习到文本中丰富的语义信息和依赖关系,从而增强模型表达能力和理解能力。
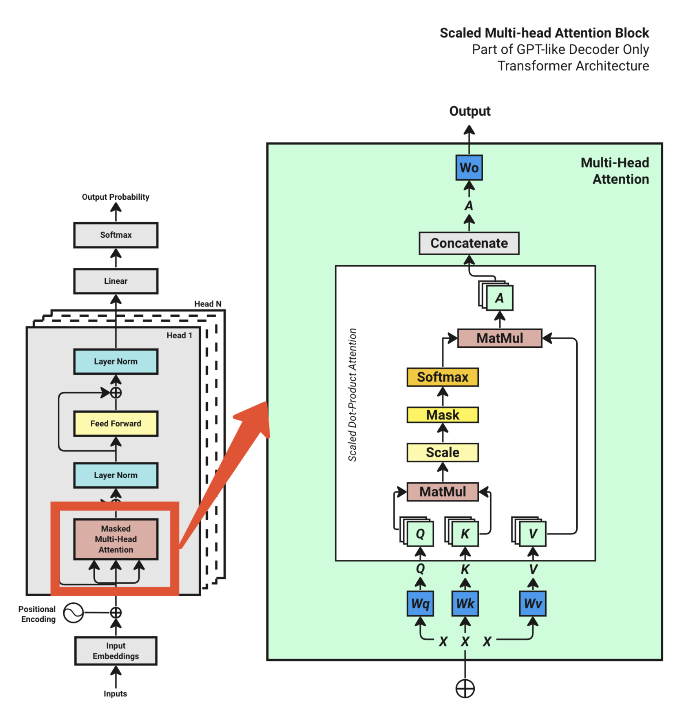
在Multi-Head Attention中首先只考虑单个批次,输入矩阵X的维度为[句子的长度x词嵌入向量维度],即输入序列的词嵌入向量(已经经过位置编码和输入嵌入,该内容以后会补充),然后根据矩阵X创建另外三个权重矩阵,分别为Wq、Wk、Wv.用矩阵X分别乘以Wq、Wk、Wv就可以依次创建出查询矩阵Q、键矩阵K和值矩阵V。其中权重矩阵Wq、Wk、Wv的初始值是完全随机的,最优值是通过模型训练获得的。
-
Query-查询:Q矩阵表示了当前的关注点,在模型中,序列的每一个值都会生成一个Query,用来表示该词在上下文中,应该重点关注哪些其他词。
-
Key-键:K矩阵表示了该词的信息标签,用来被其他的Query检索和匹配
-
Value-值:当有词被另外一个词检索时,实际上根据Key去访问该词真正的语义信息
在图中的Q,K,V为多层,实际上是"头的数量",多头注意力实际上是多个单头注意力机制在并行工作。
首先,超参数定义(后续的代码会用):
# Hyperparameters
context_length = 128 # Length of the token chunk each batch
d_model = 512 # The size of our model token embeddings
num_blocks = 12 # Number of transformer blocks
num_heads = 8 # Number of heads in Multi-head attention
dropout = 0.1 # Dropout rate
单层注意力机制分析,定义Attention类:
def __init__(self):
super().__init__()
# 定义Wq、Wk、Wv,维度为[d_model, d_model // num_heads]
self.Wq = nn.Linear(d_model, d_model // num_heads, bias=False)
self.Wk = nn.Linear(d_model, d_model // num_heads, bias=False)
self.Wv = nn.Linear(d_model, d_model // num_heads, bias=False)
# 定义张量缓存区,不参与梯度更新
self.register_buffer('mask', torch.tril(torch.ones(context_length, context_length)))
self.dropout = nn.Dropout(dropout)
多个注意力头将原始的输入矩阵X的d_model维空间特征均匀拆分,让每个头处理不同的空间特征。该模型的主要任务是文本生成,因此利用的是Transformer的解码器(Decoder)的因果掩码(Causal Mask)机制,调用register_buffer函数生成一个下三角矩阵,上三角部分全部为0,即对文本进行了掩码操作,让模型在训练的过程中只能关注当前位置和它之前的位置的文本内容。
def forward(self, x):
# 获取输入矩阵X的三个维度:[批次,token长度,嵌入维度d_model]
B, T, C = x.shape
# Q、K、V矩阵的计算
q = self.Wq(x)
k = self.Wk(x)
v = self.Wv(x)
# 计算查询和键的点积 并进行缩放:MatMul and Scale
weights = (q @ k.transpose(-2, -1)) / math.sqrt(d_model // num_heads)
# Mask
weights = weights.masked_fill(self.mask[:T, :T] == 0, float('-inf'))
#Softmax dim=-1,对行进行处理,得到每个位置的注意力分数
weights = F.softmax(weights, dim=-1)
#Dropout
weights = self.dropout(weights)
#MatMul
output = weights @ v
return output
Q和K矩阵相乘得到注意力分数,为了后续的softmax不会出现梯度消失等问题,需要对weights进行缩放。之后对weights进行因果掩码,weights矩阵的维度为[B,T,T],因此对单个批次处理时,掩码维度也为[T,T],并且对上三角掩码的部分设置为-inf,这是因为在后面的softmax部分,矩阵中为-inf的部分经过计算后刚好为0,使模型只能注意到当前的文本。最后weights与V矩阵相乘,返回output值,即图中的A,因此forward前向传播函数完成了图中白色方框内的步骤。
当完成一个Attention类之后,则是通过MultiHeadAttention类完成多个Attention类的组合,即多头注意力机制:
def __init__(self):
super().__init__()
# 通过ModuleList定义num_heads个Attention类在列表中
self.heads = nn.ModuleList([Attention() for _ in range(num_heads)])
#定义投影层
self.projection_layer = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
在MultiHeadAttention类中通过moduleList定义num_heads个Attention类在存储在heads列表中
def forward(self, x):
head_outputs = [head(x) for head in self.heads]
# Concatenate
head_outputs = torch.cat(head_outputs, dim=-1)
# Wo 输出投影矩阵
out=self.projection_layer(head_outputs)
out = self.dropout(out)
return out
head_outputs里面存储num_head个head(Attention类的实例对象)输出的结果,通过torch.cat将这些输出结果拼接为最初的[B,T,d_model]维度,如果在此时直接输出,则每个head计算得到的注意力加权分数之间没有关联性,也就是最简单的拼接,而通过projection_layer(维度为[d_model,d_model])对head_outputs cat之后进行矩阵乘法,让模型对不同注意力头的特征进行学习组合,即让每个头之间产生关联性,而不是普通的拼接,最后输出的矩阵维度保持为[B,T,d_model]
完成Masked Multi-Head Attention之后,tranformer架构中还有Layer Norm和Feed Forward以及Head1 到Head N的实现,这些部分将留到下节

 浙公网安备 33010602011771号
浙公网安备 33010602011771号