爬取小说的二级页面和三级页面
从小说中调取连接然后用python在进行爬取运行
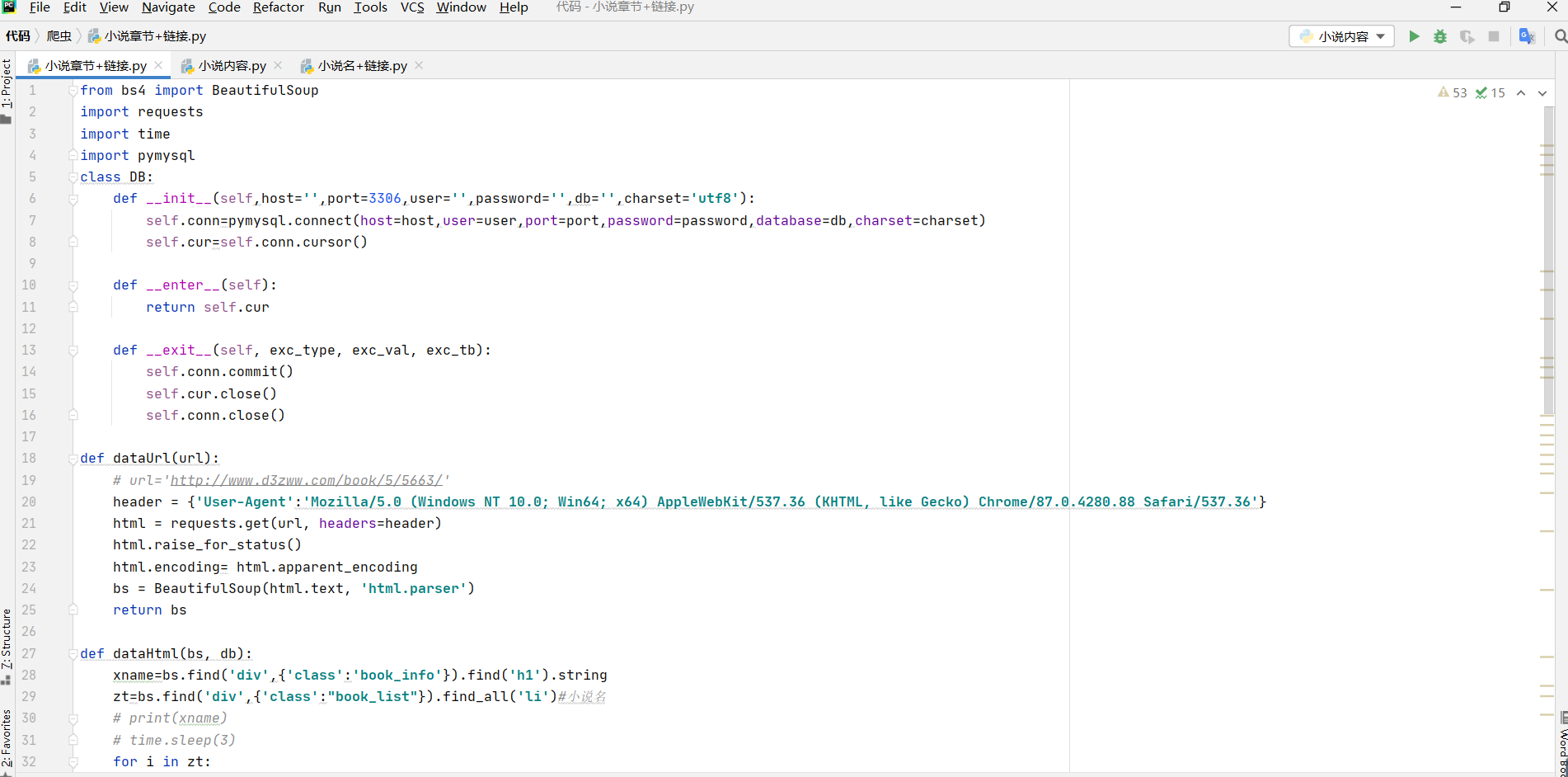
上面的是为装头找到要爬取的标签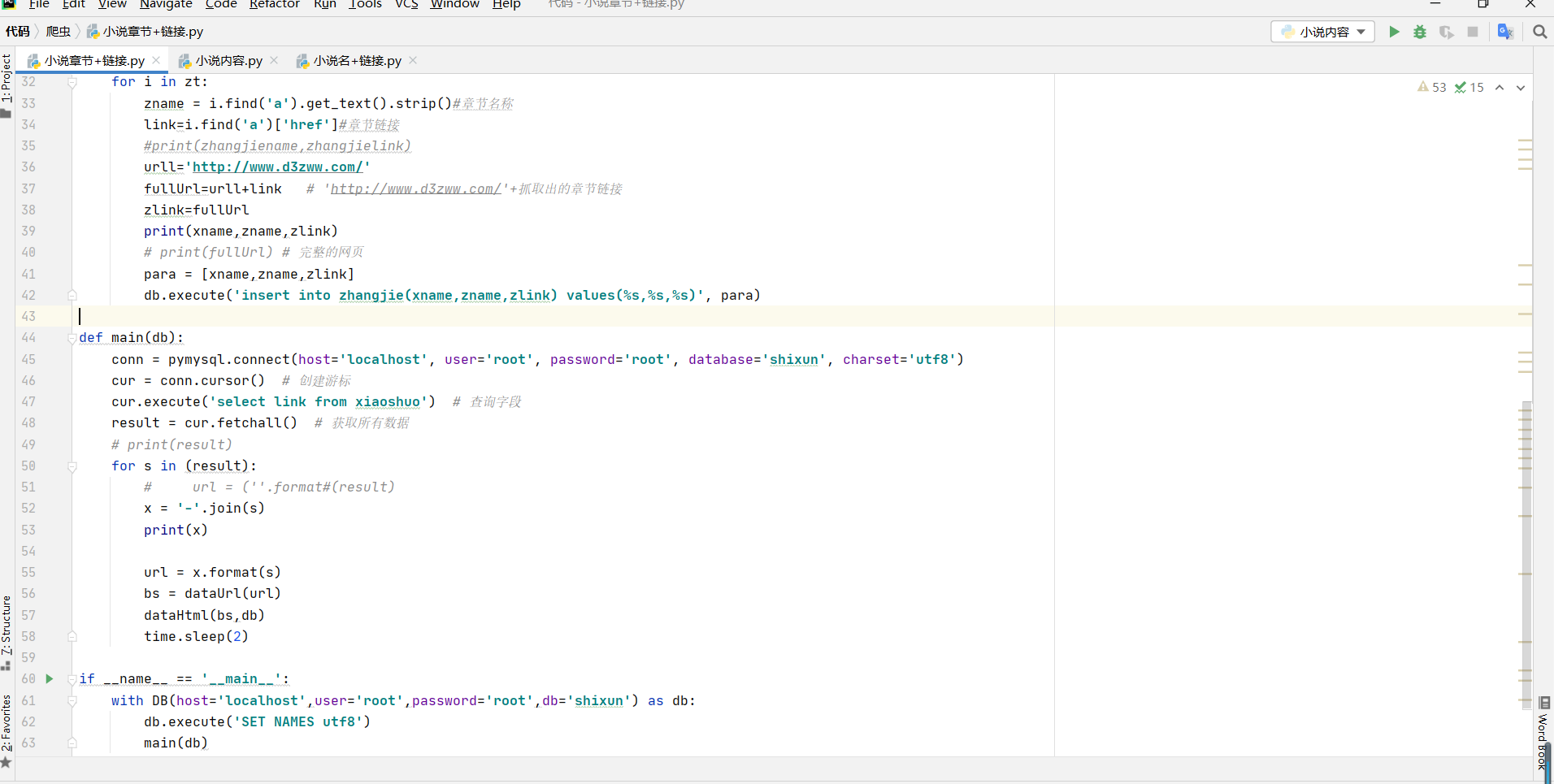
这个是从数据库中调取连接并去掉数据库中的来链接上的括号的和逗号
conn = pymysql.connect(host='localhost', user='root', password='root', database='shixun', charset='utf8')
cur = conn.cursor() # 创建游标
cur.execute('select zlink from zhangjie ') # 查询字段
result = cur.fetchall() # 获取所有数据
# print(result)
for s in (result):
# url = (''.format#(result)
x = '-'.join(s)
# print(x)
url = x.format(s)
bs = dataUrl(url)
dataHtml(bs,db)
这是一个重要的部分不能省略
这是三级标签,也是从数据库中的调取来链接在进行爬取的同上
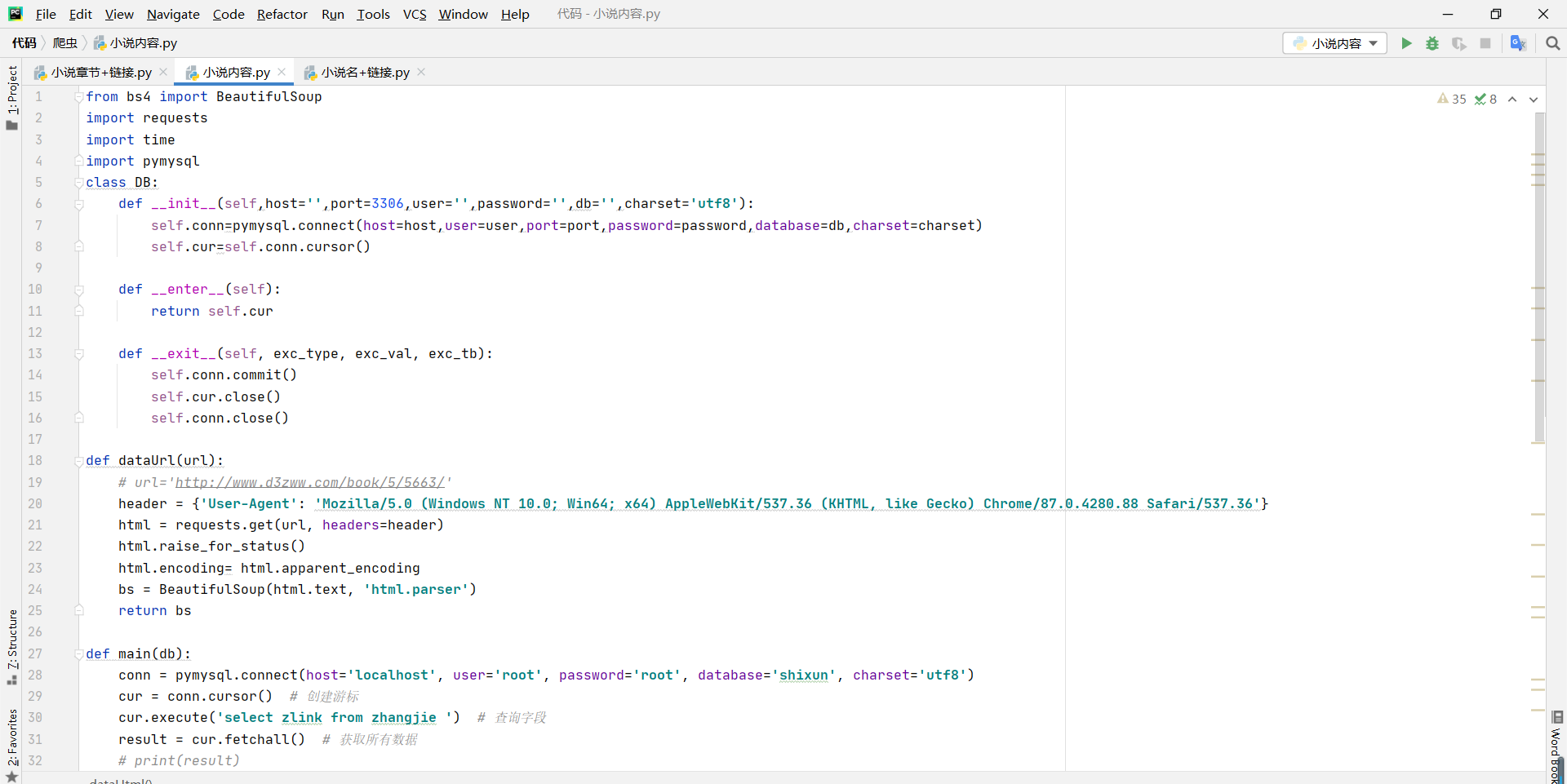
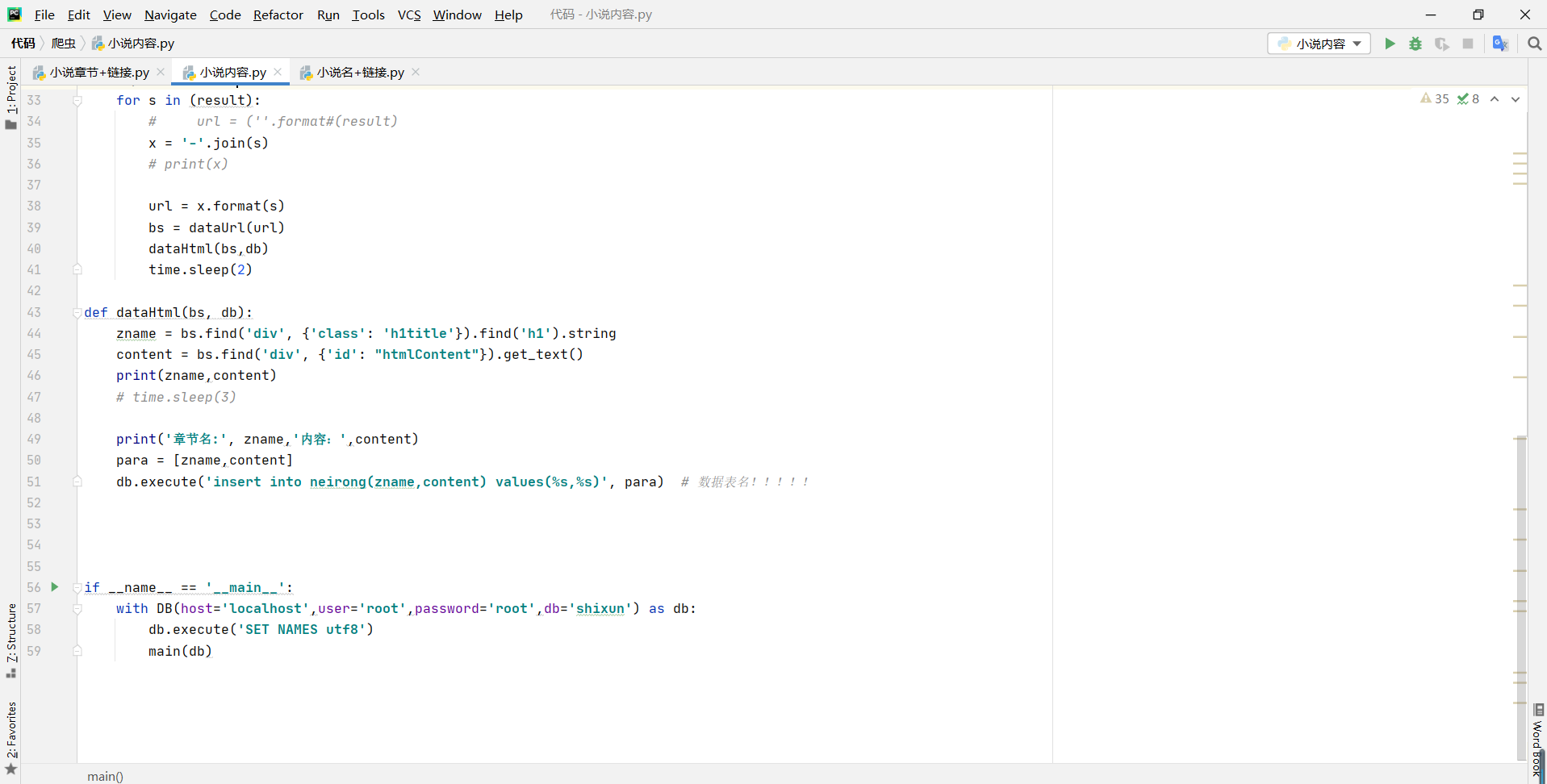
在做这个代码要注意数据库的名密码和等一些东西都要记得写上还有在python中一定要注意大小写的问题还有缩进问题要不是很容易报错
还有就是要注意爬取的标签因为标签的准确度也决定你要爬取的正确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号