缓存 | Redis 缓存避坑指南
作者:马功伟 青云科技软件开发工程师
目前从事青云数据库管理平台开发工作,一直从事 Server 端开发工作。
高并发业务场景下,常使用缓存技术缓解数据库压力,可极大的提升用户体验和系统稳定性。由于 Redis 自身的诸多特性,很适合用来做缓存。下面是一个常见的缓存查询流程。
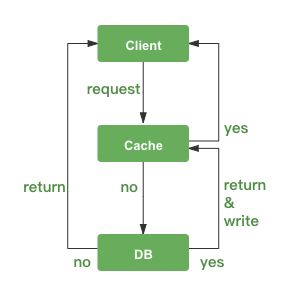
虽然缓存带来了较多数据库使用性能方面的提升,也会带来一些缓存使用问题。
本文将为大家介绍并区分 缓存穿透,缓存击穿,缓存雪崩 三个常见缓存问题,并针对不同问题提供相应解决思路。
| 缓存击穿
查询请求下发后,缓存层中没有查询内容,数据库中有。在高并发场景下,某热点 Key 突然失效,所有请求都打到数据库上,导致数据库压力过大。

解决思路
永不失效
这里分两种情况:
- 对缓存数据的 Redis Key 不设置过期时间,在数据库写入后进行刷新缓存;
- 另起异步任务在 Redis Key 将要过期的时候来更新缓存。
使用互斥锁
业界常使用 mutex 。简单说,就是只允许一个线程重建缓存,其他线程等待重建缓存完成,再从缓存获取数据即可。
| 缓存穿透
查询下发后,缓存层和数据库层都没有数据的情况。由于存储层查不到,导致无数据缓存。不存在的数据请求每次都要到存储层去查询,在高并发场景下,导致数据库压力过大。

解决思路
缓存空值
对于缓存中没有并在数据库中查询不到的数据,可以缓存空值,并设置较短的有效期。
接口层进行校验
类似 ID=-1 这样的请求,可以在接口层增加参数和发性校验,对于校验不通过的请求直接 Return。
通过 IP 限流
对单一 IP 进行限流,比如 10 次/ 2 秒。虚拟货币交易所使用该解决方案。
布隆过滤器
当要查询一个数据时,使用 K 个哈希函数对元素值进行 K 次计算,得到 K 个哈希值,根据得到的哈希值,检查对应的 K 个比特值。
| 缓存雪崩
高并发场景下,同一时间大面积的缓存失效,所有的请求打到数据库上,导致数据库压力过大。与缓存击穿不同的是,缓存击穿是并发查询同一条数据,缓存雪崩是大量的缓存失效。

解决思路
随机生成 Redis Key 的过期时间
在写入缓存时随机生成 Key 的过期时间,比如随机在 1-10 之间生成秒数。
加锁排队
与缓存击穿解决思路一致。
缓存预热
系统上线时将相关数据写入缓存,这样可以避免在系统上线初期的高并发访问。
永不失效
和缓存击穿解决思路一致。
对于加锁排队方案可以减轻数据库压力,但是会降低吞吐量,分布式系统中,还要考虑分布式锁的问题,并且在高并发情况下,可能会导致用户等待超时,对系统并发能力并没有显著作用。
总结
对以上提及的解决思路,也存在如下一些缺点。
| 问题类型 | 思路 | 缺点 |
|---|---|---|
| 击穿&雪崩 | 永不失效 | 容易产生脏数据 |
| 击穿&雪崩 | 使用互斥锁 | 造成系统吞吐量降低 |
| 穿透 | 布隆过滤器 | 产生假阳性情况 |
故针对不同的业务系统,需要根据不同的业务场景具体分析,对症下药。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号