http面试问题集锦
1、http的请求报文和响应报文?
http请求报文:请求行(请求方法+url)、请求头,请求体
http响应报文:状态行(http版本+状态码)、响应头、响应体
2、常用的http请求类型?
请求类型很多:GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT
最常用:get,post
3、http和https的区别,为什么https更加安全,ssl加密是怎样的?
1)http是直接和tcp通信,https=http+ssl加密
2)http端口号为80,https端口号为443
3)https基于传输层、http基于应用层
4)https对于搜索引擎更友好,利于seo,百度、谷歌等搜索引擎优先索引https网页
ssl加密:发送密文的一方使用对方的公钥进行加密处理“对称的密钥”,然后对方用自己的私钥解密拿到“对称的密钥”,这样可以确保交换的密钥是安全的前提下,使用对称加密方式进行通信。
所以,HTTPS采用对称加密和非对称加密两者并用的混合加密机制。
4、如何理解get和post的区别?
1)get请求参数跟在url后面,有长度限制(浏览器长度限制,如果是内部的get请求则不限制长度),post请求参数封装在请求头中,无长度限制。
2)get请求参数暴露,安全性保密性没有post高
3)get请求会被浏览器缓存起来,post请求内容不会被缓存
5、有人说post比get安全,这种说法对吗?
选择性使用,GET对数据进行查询,POST主要对数据进行增删改,get请求不会对服务端数据产生任何影响;因此只要不用get传输保密信息,它还是安全的。
6、http的常用响应码有哪些?502和504的区别?405和415的区别?302和301的区别?
1xx(临时响应)
2xx (成功)
3xx (重定向)
301 (永久移动) 请求的网页已永久移动到新位置。服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx(客户端请求错误)
405 (方法禁用)禁用请求中指定的方法。
415 (不支持的媒体类型)请求的格式不受请求页面的支持。
5xx(服务器错误)
502 (错误网关)服务器作为网关或代理,从上游服务器收到无效响应。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
7、cookie和session的区别?cookie从哪里来?cookie失效时间由哪些方法控制?
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
5、所以个人建议:
将登陆信息等重要信息存放为session
其他信息如果需要保留,可以放在cookie中
能通过Web Server或者客户端浏览器来获取到Cookie。多数浏览器能够配置允许用户访问Cookies,但是注意不同的站点之间的Cookie是不能共享的。
Cookie有一个属性expires,设置其值为一个时间,那么当到达此时间后,此cookie失效
过Okhttp的拦截器去进行持久化cookie
8、浏览器f5和强制刷新ctrl+f5的区别是什么?
1.F5使用缓存,并且只有在资源内容发生变化的时候才会去更新资源
当刷新一个页面的时候,浏览器会尝试使用各种类型的缓存,并且会发送If-Modified-Since头到服务器,如果服务器返回304 Not Modified,那么浏览器会使用本地的缓存;如果服务器返回200 OK和资源内容,那么浏览器会使用返回的资源内容,并把资源内容进行缓存,待下次使用。
2.CTRL-F5 强制更新页面资源的缓存
MSIE会发送Cache-Control: no-cache头,Firefox和Chrome除了发送Cache-Control: no-cache头之外,还会发送Pragma: no-cache头。Opera比较另类,不发送任何和缓存相关的头。
9、http缓存机制是怎样的,如何合理地缓存http?
Http缓存主要分为两种:强缓存和协商缓存
1)强缓存基本原理是:所请求的数据在缓存数据库中尚未过期时,不与服务器进行交互,直接使用缓存数据库中的数据。
Expire 其指定了一个日期/时间, 在这个日期/时间之后,HTTP响应被认为是过时的。但是它本身是一个HTTP1.0标准下的字段,所以如果请求中还有一个置了 “max-age” 或者 “s-max-age” 指令的Cache-Control响应头,那么 Expires 头就会被忽略。
Cache-Control通用消息头用于在http 请求和响应中通过指定指令来实现缓存机制。其常用的几个取值有:
private:客户端可以缓存
public:客户端和代理服务器都可以缓存
max-age=xxx:缓存的内容将在xxx 秒后失效
s-max-age=xxx:同s-max-age,但仅适用于共享缓存(比如各个代理),并且私有缓存中忽略。
no-cache:需要使用协商缓存来验证缓存数据
no-store:所有内容都不会缓存,强缓存和协商缓存都不会触发
must-revalidate:缓存必须在使用之前验证旧资源的状态,并且不可使用过期资源。
2)当强缓存过期未命中或者响应报文Cache-Control中有must-revalidate标识必须每次请求验证资源的状态时,便使用协商缓存的方式去处理缓存文件。
协商缓存主要原理是从缓存数据库中取出缓存的标识,然后向浏览器发送请求验证请求的数据是否已经更新,如果已更新则返回新的数据,若未更新则使用缓存数据库中的缓存数据。
10、请求头中一般有什么?
1)Accept 作用: 浏览器端可以接受的媒体类型 例:Accept :text/html
2)Accept-Encoding: 作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate)
3)Accept-Language 作用: 浏览器申明自己接收的语言。 例:Accept-Language: en-us
4)Connection 例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
5)Host(发送请求时,该报头域是必需的) 作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
6)Referer 作用:当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的
7)User-Agent 作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
11、什么是正向代理,反向代理,中间人攻击?
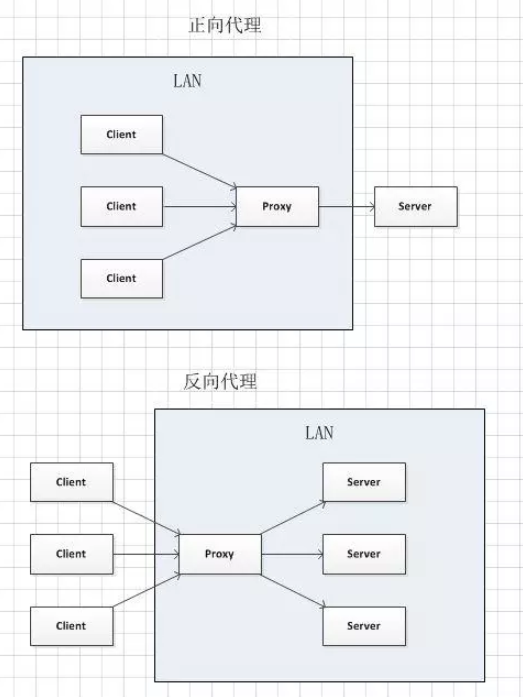
正向代理即是客户端代理, 代理客户端, 服务端不知道实际发起请求的客户端.
反向代理即是服务端代理, 代理服务端, 客户端不知道实际提供服务的服务端
正向代理的用途:
(1)访问原来无法访问的资源,如google
(2) 可以做缓存,加速访问资源
(3)对客户端访问授权,上网进行认证
(4)代理可以记录用户访问记录(上网行为管理),对外隐藏用户信息
反向代理的作用:
(1)保证内网的安全,阻止web攻击,大型网站,通常将反向代理作为公网访问地址,Web服务器是内网
(2)负载均衡,通过反向代理服务器来优化网站的负载
中间人攻击:
中间人攻击(Man-in-the-Middle Attack, MITM)是一种由来已久的网络入侵手段,并且当今仍然有着广泛的发展空间,如SMB会话劫持、DNS欺骗等攻击都是典型的MITM攻击。简而言之,所谓的MITM攻击就是通过拦截正常的网络通信数据,并进行数据篡改和嗅探,而通信的双方却毫不知情。
12、uri和url的区别?
URI 是统一资源标识符,而 URL 是统一资源定位符。每个 URL 都是 URI,但不一定每个 URI 都是 URL。这是因为 URI 还包括一个子类,即统一资源名称 (URN),它命名资源但不指定如何定位资源
13.tcp和udp的区别?
1、TCP是面向连接的(在客户端和服务器之间传输数据之前要先建立连接),UDP是无连接的(发送数据之前不需要先建立连接)
2、TCP提供可靠的服务(通过TCP传输的数据。无差错,不丢失,不重复,且按序到达);UDP提供面向事务的简单的不可靠的传输。
3、UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性比较高的通讯或广播通信。随着网速的提高,UDP使用越来越多。
4、没一条TCP连接只能是点到点的,UDP支持一对一,一对多和多对多的交互通信。
5、TCP对系统资源要去比较多,UDP对系统资源要求比较少
6、UDP程序结构更加简单
7、TCP是流模式,UDP是数据报模式
2、TCP提供可靠的服务(通过TCP传输的数据。无差错,不丢失,不重复,且按序到达);UDP提供面向事务的简单的不可靠的传输。
3、UDP具有较好的实时性,工作效率比TCP高,适用于对高速传输和实时性比较高的通讯或广播通信。随着网速的提高,UDP使用越来越多。
4、没一条TCP连接只能是点到点的,UDP支持一对一,一对多和多对多的交互通信。
5、TCP对系统资源要去比较多,UDP对系统资源要求比较少
6、UDP程序结构更加简单
7、TCP是流模式,UDP是数据报模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号