
【python+flume+kafka+spark streaming】编写word_count入门示例
一. 整体架构的一些理解
1.整体架构的理解:
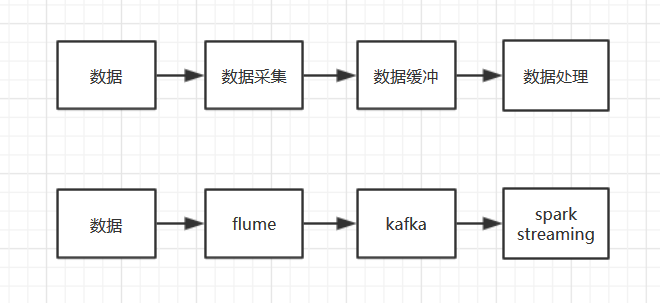
架构中的角色分为了数据采集,数据缓冲,还有数据处理。
flume由于输入和输出的接口众多,于是利用这特点来实现无编程的数据采集。
无编程的数据采集,我是这样理解的,主要就是数据输入和输出的格式转化问题,不过暂时还是纯粹的臆测,学的很浅;
kafka则是将数据输入和数据处理,进行了解耦,从而达到生产和消费平衡(数据采集速度和处理速度平衡);
spark很好理解,就是单纯的处理数据。
2.部署上的理解:
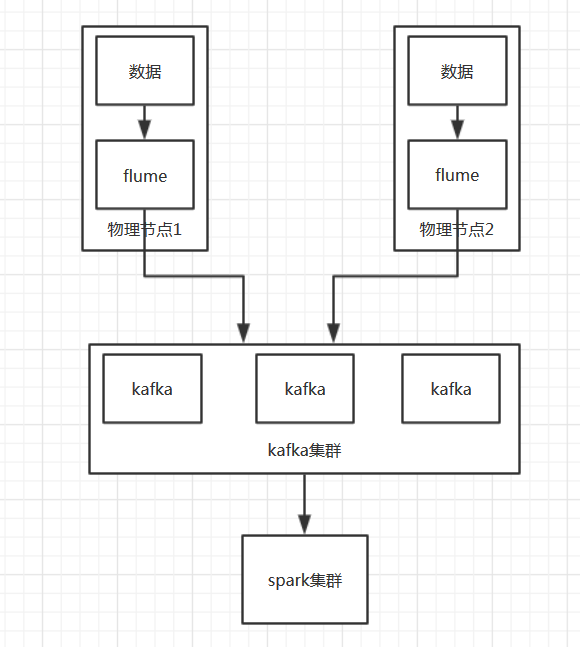
flume是存在于各个数据产生节点上的;
kafka主要是broker的角色,而且是一个集群。
3.关于几个部件原理介绍的一些文章:
二. 代码以及遇到的一些问题
1.代码:
2.问题:
1) 缺jar包:
下载相应的streaming jar包,放到jar文件夹中,或者sumbit加上相应参数即可解决;
2)拒绝访问:
我一开始的时候,使用sl77作为spark集群的master,后来发现sl77并没有其他机子的ssh访问权限,只有75,76做了相应的配置;
3)invalid ip:
在/etc/hosts中配置映射,配置成了ip hadoop@ip的形式,spark识别不出,改成ip slxx的形式后解决;
4)日志过多,影响观察结果问题:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号