
Selenium+Python微博爬虫实战
Selenium靠着一个很全的语法博客+一个B站视频+大佬室友勇哥的帮助下成功上手
博客链接:https://blog.csdn.net/l01011_/article/details/133167674
视频链接:https://www.bilibili.com/video/BV1wT411b7Ea/?vd_source=8d39d79cffe8373303d902c4194fbea2
1 安装
selenium 是一个 web 的自动化测试工具。selenium爬虫基于网页的模拟操作,便于理解,适合新手上手爬虫。
selenium 支持多平台:windows、linux、MAC ,支持多浏览器:IE、safari、opera、chrome
第一步:安装selenium
Win:pip install selenium
Mac: pip3 install selenium
第二步:安装webdriver
各大浏览器webdriver地址可参见:https://docs.seleniumhq.org/download/
Firefox:https://github.com/mozilla/geckodriver/releases/
Chrome:https://googlechromelabs.github.io/chrome-for-testing/
IE:http://selenium-release.storage.googleapis.com/index.html
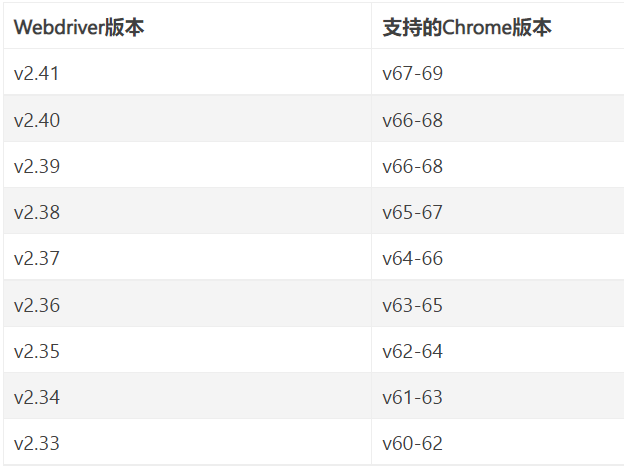
附: Webdriver版本对应的Chrome版本
第三步:Webdriver 安装路径
Win:复制 webdriver 到 Python 安装目录下
Mac:复制 webdriver 到 /usr/local/bin 目录下
第四步:启动尝试
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')
2 Selenium基础
2.1 启动浏览器
from selenium import webdriver
browser = webdriver.Chrome() #选择自己的浏览器
browser.get('http://www.baidu.com/')
2.2 切换代理IP
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--proxy-server={}'.format("IP地址"))
driver = webdriver.Chrome(options=chrome_options)
2.3 元素定位
webdriver 提供了一系列的对象定位方法,常用的有以下几种(新版定位方法已更新):
from selenium.webdriver.common.by import By
# id定位:
ele.find_element(By.ID,"xx")
# name定位:
ele.find_element(By.NAME,"xx")
# class定位:
ele.find_element(By.CLASS_NAME,"xx")
# link定位:
ele.find_element(By.LINK_TEXT,"xx")
# partial link定位:
ele.find_element(By.PARITIAL_LINK_TEXT,"xx")
# tag定位:
ele.find_element(By.TAG_NAME,"xx")
# xpath定位:
ele.find_element(By.XPATH, "xxx")
其中id定位和xpath定位是最常用的,微博的HTML框架比较稳定,一般用xpath定位很稳
2.4 等待方式
爬取数据过程中如果网速不稳定,在程序执行爬取命令时对应元素没有加载完全,程序会因找不到对应元素而报错。解决方法:
# 方法一:强制等待3秒再执行下一步
import time
time.sleep(3)
# 方法二:隐性等待,最长等10秒
driver.implicitly_wait(10)
# 方法三:显性等待,最长等10秒
import selenium.webdriver.support.ui as ui
wait = ui.WebDriverWait(driver,10)
wait.until(lambda driver: driver.find_element(By.CLASS_NAME,"woo-input-main"))
2.5 浏览器操作
# (1)浏览器最大化
browser.maximize_window()
# (2)浏览器最小化
browser.minimize_window()
# (3)设置窗口大小(宽480,高800)
browser.set_window_size(480, 800)
# (4)前进
browser.forword()
# (5)后退
browser.back()
2.6 键盘与鼠标事件
# 键盘操作需要调用keys包
from selenium.webdriver.common.keys import Keys
# 键盘的清空与输入
driver.find_element(By.ID,"user_name").clear()
driver.find_element(By.ID,"user_name").send_keys("fnngj")
# 也可以使用tab键与enter键
driver.find_element(By.ID,"user_name").send_keys(Keys.TAB) # TAB有清空功能
driver.find_element(By.ID,"user_pwd").send_keys(Keys.ENTER)
# 鼠标操作需要调用ActionChains包
from selenium.webdriver.common.action_chains import ActionChains
driver.find_element(By.ID,"login").click() # 点击
driver.find_element(By.ID,"login").context_click() #右击
driver.find_element(By.ID,"login").double_click() #双击
driver.find_element(By.ID,"login").drag_and_drop() #拖动
driver.find_element(By.ID,"login").move_to_element() #鼠标悬停
3 登录微博
直接账号密码登录遇到的麻烦居多,最简单的办法就是直接手机扫二维码登录。虽然每次爬虫都要用手机扫一下有点麻烦,但是比写半天登录代码还要应对动不动就来的界面更新好多了。
def login():
driver.get('https://weibo.com/login.php')
driver.maximize_window()
time.sleep(3)
title = driver.title
print(title)
while (title != "微博 – 随时随地发现新鲜事"):
time.sleep(1)
title = driver.title
print(title)
time.sleep(1)
4 微博爬取实战
4.1 爬取微博
微博页面大致是相似的,下面的代码基本可以通用:
from selenium import webdriver
import pandas as pd
import selenium.webdriver.support.ui as ui
import time
def login():
driver.get('https://weibo.com/login.php')
driver.maximize_window()
time.sleep(3)
title = driver.title
while (title != "微博 – 随时随地发现新鲜事"):
time.sleep(1)
title = driver.title
time.sleep(1)
author_id = []
author_url = []
text_content = []
text_url = []
video_url = []
text_time = []
text_field = []
Num = 0
# 打开Chorme并登录微博
driver = webdriver.Chrome()
login()
wait = ui.WebDriverWait(driver, 10)
# 打开指定网页
url_name = input("Input Url:")
driver.get(url_name)
time.sleep(1)
for i in range(0, 100): # 爬取轮数
div_list = driver.find_element(By.XPATH,'/html/body/div/div[1]/div[2]/div[2]/main/div/div/div[2]/div/div/div/div/div/div/div[1]/div')
# 爬取相关数据
for div in div_list:
print("No. ", j)
now = div.find_element(By.XPATH,"./div/article/div/header/a")
aid = now.get_attribute('aria-label') # 爬取作者名称
aurl = now.get_attribute('href') # 爬取作者主页
print("author_id: ", aid)
print("author_url: ", aurl)
now = div.find_element(By.XPATH,"./div/article/div/header/div[1]/div/div[2]/a")
_time = now.get_attribute('title') # 爬取发表时间
turl = now.get_attribute('href') # 爬取微博链接
print("text_time: ", _time)
print("text_url: ", turl)
if (aid in author_id and _time in text_time): # 重要的去重工作
print("Have Reptiled!")
continue
now = div.find_element(By.XPATH,"./div/article/div/div/div[1]/div")
content = now.text
content = content.replace('\n', '') # 爬取微博文本
print("text_content: ", content)
a_list = div.find_element(By.XPATH,"./div/article/div/div/div[1]/div/a")
if (len(a_list)!=0): # 爬取视频链接
s = a_list[-1].get_attribute("href")
t = s.find("vedio.weibo.com")
if (t!=-1):
vurl = s
else:
vurl = ''
else:
vurl = ''
print("video_url: ", vurl)
# 爬取完毕,添加到数据列表当中
author_id.append(aid)
author_url.append(aurl)
text_content.append(content)
text_url.append(turl)
video_url.append(vurl)
text_time.append(_time)
text_field.append(field[i])
Num = Num + 1
driver.execute_script("window.scrollBy(0,3000)") # 往下滑动更新页面显示的微博
# 输出至csv
csv_name = input("Input csv_name:")
index = range(1, Num + 1)
data = pd.DataFrame(data={"No.": index,
"author_url": author_url,
"author_id": author_id,
"text_content": text_content,
"video_url": video_url,
"text_time": text_time,
"text_url": text_url,
"field": text_field
}).to_csv(csv_name, index=False)
print('数据已保存至', csv_name, '中')
4.2 爬取评论
from selenium import webdriver
import pandas as pd
import selenium.webdriver.support.ui as ui
import time
import re
import csv
# 模拟登录微博
def login():
driver.get('https://weibo.com/login.php')
driver.maximize_window()
time.sleep(3)
title = driver.title
print(title)
while (title != "微博 – 随时随地发现新鲜事"):
time.sleep(1)
title = driver.title
print(title)
time.sleep(1)
# 打开Chorme并登录微博
driver = webdriver.Chrome()
wait = ui.WebDriverWait(driver, 10)
kk = re.compile(r'\d+')
login()
# 打开指定网页
url_name = input("Input Url:")
driver.get(url_name)
list_time = []
list_name = []
list_comment = []
list_like = []
list_reply = []
Num = 0 # 记录爬取评论条数
for i in range(30):
# 当前窗口显示的所有评论的div
div_list = driver.find_element(By.XPATH, '//*[@id="scroller"]/div[1]/div')
for div in div_list:
_time = div.find_element(By.XPATH, './div/div/div/div[1]/div[2]/div[2]/div[1]').text # 爬取时间
print("Time:", _time)
name = div.find_element(By.XPATH, './div/div/div/div[1]/div[2]/div[1]/a[1]').text # 爬取发表人id
print("Name:", name)
if ((name in list_name) or (name == _time)): # 去重
print("Have Reptiled!")
continue
comment = div.find_element(By.XPATH, './div/div/div/div[1]/div[2]/div[1]/span').text #爬取微博内容
print("Comment:", comment)
ele = div.find_element(By.XPATH, './div/div/div/div[1]/div[2]/div[2]/div[2]/div[4]/button/span[2]')
if (len(ele) == 1):
like = ele[0].text
else:
like = 0
print("Like:", like)
ele = div.find_element(By.XPATH, './div/div/div/div[2]/div/div/div/span')
if (len(ele) == 1):
x = re.findall(kk, ele[0].text) # 正则表达式定位数字
reply = int(x[0])
else:
reply = 0
print("Reply:", reply)
# 爬取完毕,添加到数据列表当中
list_time.append(_time)
list_name.append(name)
list_comment.append(comment)
list_like.append(like)
list_reply.append(reply)
Num += 1
driver.execute_script("window.scrollBy(0,3000)") # 往下滑动更新页面显示的微博
# 输出至csv中
csv_name = input("Input csv_name:")
index = range(1, Num + 1)
data = pd.DataFrame(data={"id": index,
"time": list_time,
"name": list_name,
"comment": list_comment,
"like": list_like,
"reply": list_reply
}).to_csv(csv_name, index=False)
print('数据已保存至',csv_name,'中')
5 一些小tip
5.1 关于多标签页的一些操作
handles = driver.window_handles # 获取已打开的所有便签页的handle
driver.switch_to.window(handles[0]) # 跳转到当前标签页
handle = driver.current_window_handle # 获取当前显示便签页的handle
5.2 使用正则表达式提取信息
import re
kk = re.compile(r'\d+') # 定位数字
x = re.findall(kk, ele[0].x) # 提取数字(返回值格式为列表)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号