
1.
DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
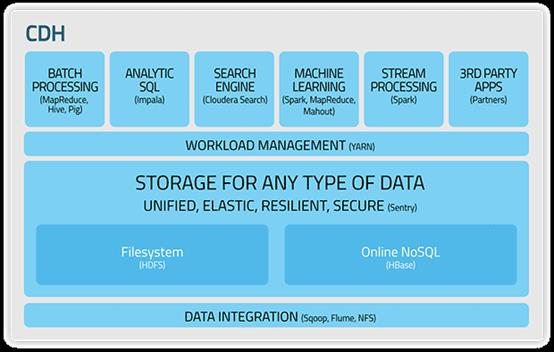
cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。
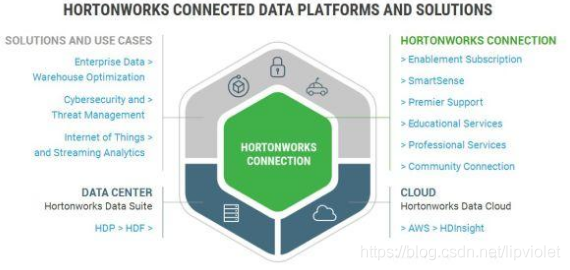
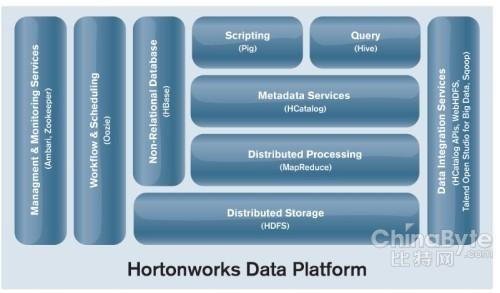
hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
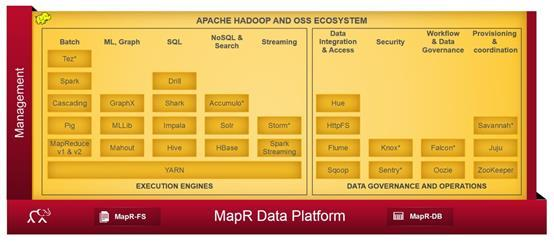
MAPR发行版:mapR有免费和商业两个版本,免费版本在功能上有所减少。
华为hadoop发行版:华为的hadoop版本基于自研的Hadoop HA平台,构建NameNode、JobTracker、HiveServer的HA功能,进程故障后系统自动Failover,无需人工干预,这个也是对hadoop的小修补,远不如mapR解决的彻底
2.
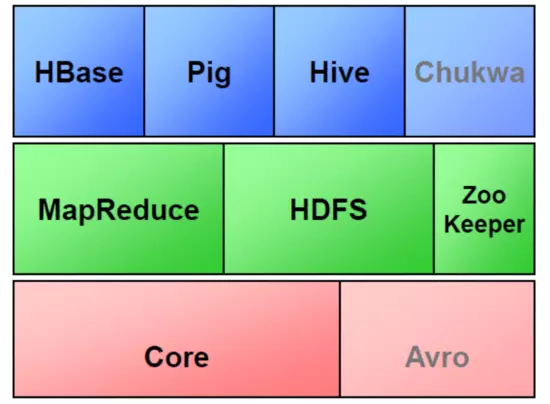
HBase:Google Bigtable的开源实现,列式数据库,可集群化,可以使用shell、web、api等多种方式访问,NoSQL的典型代表产品
Hive:支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持,可以看成是从SQL到Map-Reduce的映射器
Zookeeper:Google Chubby的开源实现,用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等,应用场景:Hbase,实现Namenode自动切换,工作原理:领导者,跟随者以及选举过程
Sqoop:
用于在Hadoop和关系型数据库之间交换数据
通过JDBC接口连入关系型数据库
Chukwa:
架构在Hadoop之上的数据采集与分析框架
主要进行日志采集和分析
通过安装在收集节点的“代理”采集最原始的日志数据
代理将数据发给收集器
收集器定时将数据写入Hadoop集群
指定定时启动的Map-Reduce作业队数据进行加工处理和分析
Pig:
Hadoop客户端
使用类似于SQL的面向数据流的语言Pig Latin
Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
Avro:
数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
Thrift接口
Cassandra:
NoSQL,分布式的Key-Value型数据库,由Facebook贡献
与Hbase类似,也是借鉴Google Bigtable的思想体系
只有顺序写,没有随机写的设计,满足高负荷情形的性能需求
3.
-
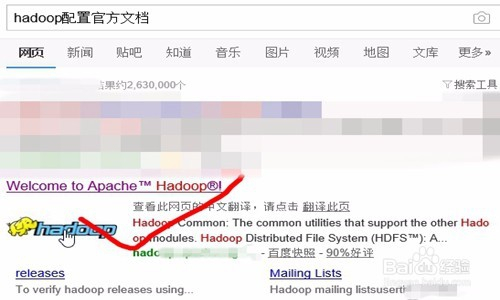
首先,打开浏览器,在搜索栏目里面搜索一下hadoop的官方配置文件,然后点击进入官方网站的链接。
![Hadoop如何查找官网的配置文档Configuration]()
-
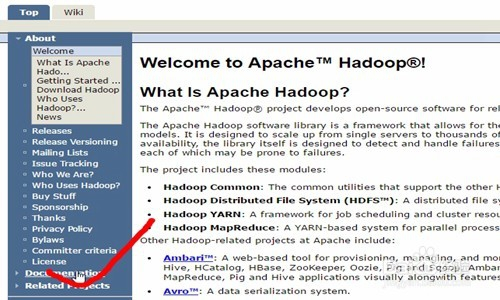
然后下滑到页面中部,点击这里的Documentation,就是文档的意思。
![Hadoop如何查找官网的配置文档Configuration]()
-
然后点击选择你需要的hadoop的软件版本,点击一下,比如这里的2.9.0。
![Hadoop如何查找官网的配置文档Configuration]()
-
然后下滑页面,在左侧找下自己想要查看到的配置文档,比如这里需要看一下hdfs-default的配置文档。
![Hadoop如何查找官网的配置文档Configuration]()
-
然后我们下滑文档找到这里的具体的自己需要查看的配置参数和数据即可。
![Hadoop如何查找官网的配置文档Configuration]() .安装并配置java环境
.安装并配置java环境
hadoop需要在java的环境中运行,需要安装JDK。
1.在官网上下载jdk,网址:http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html
a.进入选择相应的rpm包或者tar包,进行安装。我这里是下载的rpm包,因为这样比较方便。用rpm包不需要进行环境变量的配置就可以使用了。
# rpm -ivh /usr/java/jdk1.8.0_60.rpm
b.检查java环境是否安装成功,敲入如下命令:
# java -version 显示相应的版本号![技术分享]()
# javac javac相应的信息![技术分享]()
# java java相应的信息![技术分享]()






4.
华为 在硬件上具有天然的优势,在网络,虚拟化, PC 机等都有很强的硬件实力。华为的 FusionInsight Hadoop 版本 基于 Apache Hadoop ,构建
NameNode 、 JobTracker 、 HiveServer 的 HA 功能,进程故障后系统自动 Failover ,无需人工干预,这个也是对 Hadoop 的小修补,远不如 MapR 解决的彻底。华为在 Hadoop 社区中的 Contributor 和 Committer 也是国内最多的,算是国内技术实力较强的公司。
华为Hadoop组件中的6大特色:
1、统一的SQL接口,可以支持各种组件进行统一查询,而不需要把数据从一个组件迁移到另一个组件。
2、SparkSQL,SparkSQL概念并非华为提出,但华为为社区做出了很多贡献,自己的产品能力更强,例如华为主导向Spark SQL贡献的CPU优化器,使得稳定性和高性能比社区的开源的SQL更强。
3、完全自研的SQL引擎EIK,华为的SQL引擎更接近数据库甚至超过数据库,用户能够得到跟数据库一样甚至超过数据库交互体验效果。
4、Apach,CarbonData是华为主导的一个社区开展项目,参与者有国内众多互联网公司和大型企业,也有国外IT企业,其特点是对上层的应用无感知,提升了数据分析、数据查询的性能。
5、多级租户管理功能,FusionInsight提供的多级租户管理功能来匹配企业的组织架构,也就是说,可以有这种公司级的租户和管理员,有部门级的综合管理员,还有子部门租户和管理员,在给用户设置权限、设置资源配合有更方便的对应。
6、对异构设备支持,既支持高低配的设备在同一个大集群里,又支持开发应用可以指定某些应用运行在不同的机器上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号