keepalived搭建高可用
一、HA集群
1.1 ha集群是什么
高可用集群,是有多台服务器节点组成的集群,通过冗余设计和故障自动切换,保证了核心服务,持续可用,减少了停机时间
- 就是当一个提供网站的服务故障后,另外一台机器充当这个提供网站的角色
1.2 HA集群实现的几种方式
- keepalived
二、keepalived详解
1、概述
1.1 简介
-
keepalived是一款基于VRRP协议的轻量级HA软件,核心功能是vip漂移和服务的健康检查,切换的速度快
-
对LVS进行健康检查,这个keepalvied本身不具备负载均衡的功能,因此需要依赖在linux内核的LVS
-
VRRPv2协议来处理负载均衡集群的故障切换,这个完成集群节点之间的心跳检查,在集群节点故障时,将浮动ip漂移到正常的节点上,保证业务的高可用,能够继续提供服务
1.2 keepalived核心组件
-
vrrp_stack: 核心模块实现VRRP协议,负责vip漂移和主备的选举
-
checkers 健康检查模块,监控后端服务,nginx,mysql等,服务故障后,将请求不转发到这个故障的服务器上
-
libipvs: 负载均衡模块,集成LVS功能,实现了HA+负载均衡一体化
-
专业术语:
-
vip 虚拟ip,对外提供服务的唯一入口,可以切换的,不是固定的
-
地址漂移 当主节点故障的时候,会迁移到备用节点
-
心跳检查 判断主备角色,监控对方的状态
-
脑裂 网络或者数据延迟的问题,在做心跳检查的时候,双方都失败了,都认为对方是坏的,就会去抢占ip地址
-
1.3 VRRP协议(核心原理)
-
就是靠这个来实现高可用的,当一个服务器故障后,备用服务器充当主服务器提供服务
-
是一个二层的协议
1.3.1 VRRP状态机制
-
initalize 不可用状态(初始状态):在Keepalive刚刚启动时还没有进行主从的选举时处于该状态或者是Keepalive的节点故障,在这个状态下是无法处理VRRP的心跳,也就是节点不可用
-
master主节点(活跃状态):在该状态下 Keepalive正常工作,并承载集群的流量访问出入口,也就是该状态下所在的节点是浮动IP所在的节点,并且向网络中正常发送VRRP的报文,优先级为255自动式master状态
-
backup 备用状态 :在该状态下Keepalive处于备用模式,不会承载集群的流量访问,仅接受和处理VRRP的心跳,并判断Master节点的状态,一旦master节点发送故障,则抢占浮动IP,将业务流量切换到当前节点,且自身变成master状态
1.3.2 VRRP选举机制
-
就是谁来获取这个浮动ip,
-
通过比较各个节点的优先级来进行比较,优先级大的成为master
-
当优先级相同的时候,比较接口的ip地址,比较值大的成为master节点
1.3.3 防脑裂机制
-
当出现了突然的情况,比如2个节点的心跳检查都检查不到,都在抢夺这个vip地址,就是一个很大的问题呢
-
解决措施
-
通过第三方软件仲裁
-
通过加强心跳网络,比如专门有一个接口来进行心跳检查
-
通过自定义检查脚本,这个是非常有用的
-
1.4 keepalived原理
-
VRRP2协议,和对业务的健康检查
-
2个节点首先进行选举,主节点接收请求,并且和备用节点进行心跳检查,当主节点故障的时候,备用节点顶替为主节点,接收请求
-
为什么能够自动切换呢?就是靠的VRRP2协议
-
还有一个功能就是对LVS的后端服务器进行健康检查,后面的综合实验会涉及到的
1.5 keepalvied健康检查方式
-
tcp_check 运行在第四层,Keepalived向后端服务器发送TCP连接请求,如果收不到响应或超时,则认为该服务器不可用,会将从服务器池中移除
-
http_get 工作在第5层,向指定的URL执行http请求,将得到的结果用md5加密并与指定的md5值比较看是否匹配,不匹配则从服务器池中移除;此外还可以指定http返回码来判断检测是否成功。HTTP_GET可以指定多个URL检测,多用于一台服务器有多个虚拟主机的场景中
-
通过摘要
-
或者状态码来检查是否成功
-
-
ssl_get 和HTTP_GET类型,区别在于连接使用SSL
-
misc_check 使用脚本对服务器状态进行检查,脚本的返回值为0表示状态正常。如果在配置时设置了misc_dynamic,权重自动会调整为“退出码-2”
Keepalive 通过VRRR 虚拟路由冗余协议来实现 节点之间的高可用,也就是通过心跳转移故障节点
2、keepalvied配置详解
2.1 安装keepalived和配置文件
yum -y install keepalived
# 配置文件路径
[root@server ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
# 安装产生的文件
[root@server ~]# rpm -ql keepalived
2.2 主配置文件详解
# 全局配置
global_defs {
notification_email {
admin@example.com # 通知邮箱1
ops@example.com # 通知邮箱2
}
notification_email_from keepalived@hostname # 发件人地址
smtp_server 127.0.0.1 # SMTP服务器
smtp_connect_timeout 30 # SMTP连接超时
router_id LVS_DEVEL # 路由器标识,必须唯一,字符串
vrrp_skip_check_adv_addr # 跳过检查广告地址
vrrp_strict # 严格遵守VRRP协议
vrrp_garp_interval 0 # 免费ARP间隔
vrrp_gna_interval 0 # 邻居通告间隔
script_user nobody # 脚本运行用户
enable_script_security # 启用脚本安全
}
# 脚本检查配置,后面实例配置需要引用
vrrp_script chk_nginx {
script "/usr/bin/killall -0 nginx" # 检测脚本路径
interval 2 # 检测间隔(秒)
weight 2 # 权重变化值
fall 2 # 失败次数判定
rise 2 # 成功次数判定
user nobody # 执行用户
}
# VRRP实例配置,核心部分,决定谁是主节点和备用节点
vrrp_instance VI_1 { # 实例名称,可自定义
state MASTER # 初始状态:MASTER/BACKUP
interface eth0 # 绑定的网络接口,也就是浮动ip地址
virtual_router_id 51 # 虚拟路由器ID(0-255),集群内必须一致,这个确保了所有的节点都是属于一个VRRP组的
priority 100 # 优先级(1-254),值越大优先级越高,255自动默认是主节点
advert_int 1 # 宣告间隔(秒),心跳检查
# 认证配置
authentication {
auth_type PASS # 认证类型:PASS/AH
auth_pass 1111 # 密码(最多8位)
}
# VIP配置(可以有多个)
virtual_ipaddress {
192.168.1.100/24 dev eth0 # VIP地址1,可以就是ip地址
192.168.1.200/24 dev eth0 label eth0:1 # VIP地址2(带标签)
}
# 跟踪脚本(健康检查)
track_script {
chk_nginx # 引用上面定义的脚本
}
}
# 虚拟服务配置,lvs相关的
virtual_server 192.168.1.100 80 { # VIP和端口
delay_loop 6 # 健康检查间隔
lb_algo rr # 调度算法:rr|wrr|lc|wlc|lblc|sh|dh
lb_kind NAT # LVS模式:NAT|DR|TUN
persistence_timeout 50 # 持久化超时,就是一个连接要持续多久,在轮询中,一个连接保持50秒,那么在这个期间内都是访问这个服务器,而不是访问另外一个服务器,后面keepalived+lvs 会注释这一行的
protocol TCP # 协议类型
# 真实服务器池
real_server 192.168.1.10 80 { # 真实服务器1
weight 1 # 权重
# TCP健康检查
TCP_CHECK {
connect_timeout 10 # 超时时间
retry 3 # 重试的次数
delay_before_retry 3 # 延迟多长时间后,再次重试
connect_port 80 # 连接的端口,默认是RS提供业务端口
}
# 或HTTP健康检查
HTTP_GET {
url {
path /healthz # 检查的路径是healthz
status_code 200 # 返回值为200就是正确的
}
connect_timeout 3
nb_get_retry 3 # get重试的次数
delay_before_retry 3 # 在重试之前延迟多少秒
}
# 或SSL健康检查,https检查
SSL_GET {
url {
path /
digest <digest_string> # 摘要检查,会生成一个固定的值
}
connect_timeout 3
retry 3
delay_before_retry 3
}
}
real_server 192.168.1.11 80 { # 真实服务器2
weight 2
TCP_CHECK {
connect_port 80
connect_timeout 3
}
}
}
2.3 脚本检查配置
- 有2种写法
2.3.1 第一种写法(任何版本都能使用)
2.3.2 第二种写法(在高版本使用)
vrrp_script nginx_check {
script “/etc/keepalived/check.sh”
interval 1 脚本执行间隔时间
weight -5 权重
fail 3 错误的次数
}
# 在实例中引用脚本
vrrp_instance Nginx {
track_script {
nginx_check
}
}
三、keepalvied实现
1、keepalived+nginx
-
目的,当一个keepalived停掉的时候,业务还在
-
另外一个问题,当业务停掉的时候,浮动ip还是故障的节点上,使用脚本检查来实现浮动ip漂移
-
vrrp是检查keepalived状态来是否漂移
1.1 拓补图
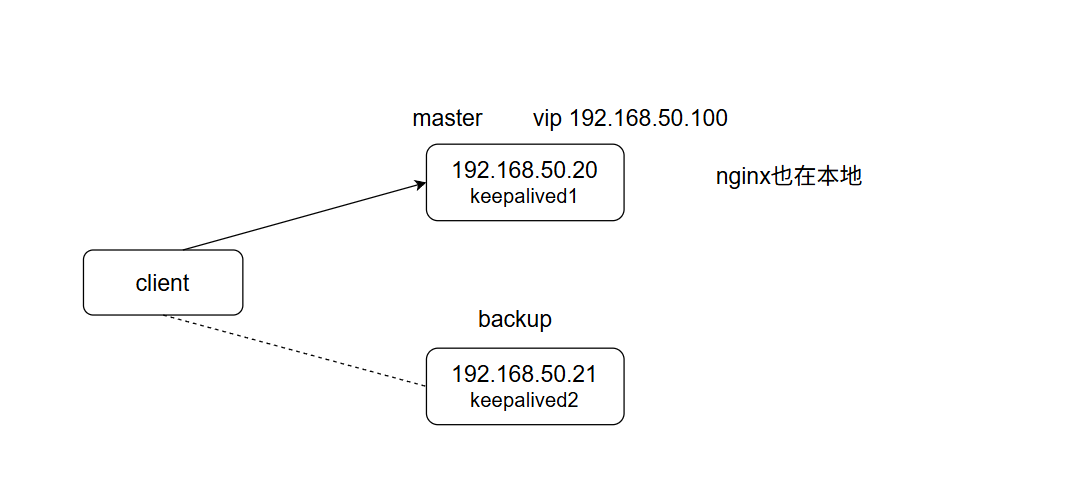
1.2 keepalived配置
主节点配置
[root@server keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs1
}
vrrp_instance lvs1 {
state MASTER
interface ens33
virtual_router_id 10
priority 254
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.50.100/24
}
}
备用节点配置
[root@node1 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs2
}
vrrp_instance lvs2 {
state BACKUP
interface ens33
virtual_router_id 10
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.50.100/24
}
}
重启服务和查看ip地址
[root@server keepalived]# systemctl restart keepalived
# ip 可以看到vip地址,但是ifconfig不会看到
[root@server keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 192.168.50.20/24 brd 192.168.50.255 scope global noprefixroute ens33
inet 192.168.50.100/24 scope global secondary ens33
# secondary 就是一个虚拟的ip地址
# 在主节点上面可以看到这个vip地址
1.2 配置后端nginx服务器
[root@server html]# echo master > index.html
[root@server html]# systemctl restart nginx
[root@node1 html]# echo backup > index.html
1.3 测试和模拟故障
直接访问浮动ip
# 发现请求都是主节点回复的,备用节点没有接收请求
[root@node2 ~]# curl 192.168.50.100
master
[root@node2 ~]# curl 192.168.50.100
master
将主节点故障
[root@server ~]# systemctl stop keepalived.service
# 发现这个浮动ip地址转移到了备用节点
[root@node1 html]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 192.168.50.21/24 brd 192.168.50.255 scope global noprefixroute ens33
inet 192.168.50.100/24 scope global secondary ens33
# 访问浮动ip,现在就是备用节点接收请求
[root@node2 ~]# curl 192.168.50.100
backup
1.4 将业务停掉呢?
-
将主节点的keepalived服务启动,浮动ip会漂移到主节点上
-
现在将主节点上面的业务停掉,发现浮动ip在这个故障的节点上,没有进行漂移
[root@server ~]# systemctl stop nginx
[root@server ~]# ip a| grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 192.168.50.20/24 brd 192.168.50.255 scope global noprefixroute ens33
inet 192.168.50.100/24 scope global secondary ens33
# 业务出现故障的节点,浮动ip地址还在上面,当客户端请求的时候,访问不到服务
[root@node2 ~]# curl 192.168.50.100
curl: (7) Failed to connect to 192.168.50.100 port 80 after 0 ms: Connection refused
-
为什么没有进行漂移呢 因为这个VRRP2协议是检测这个keepalived服务的状态来决定是否漂移,而不是业务状态
-
因此的话,就需要一个脚本进行检查
2、脚本检查业务
2.1、脚本配置
# 添加+x权限
[root@server keepalived]# cat check_nginx.sh
#! /bin/bash
systemctl is-active nginx &> /dev/null
if [ $? -ne 0 ];then
exit 10 # keepalvied健康检查可以根据这个退出码,来决定是否转移浮动ip地址
else
exit 0
fi
2.2、配置文件的添加
[root@server keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs1
}
# 在global 外面定义脚本,后面还需要引用脚本,在实例中引用脚本
vrrp_script nginx_check {
script "/etc/keepalived/check_nginx.sh"
interval 2 # 间隔时间执行
fail 3 # 重试次数
}
vrrp_instance lvs1 {
state MASTER
interface ens33
virtual_router_id 10
priority 254
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.50.100/24
}
track_script { # 引用脚本
nginx_check
}
}
2.3 停掉业务
[root@server keepalived]# systemctl stop nginx
# 查看messages日志,发现移走了浮动ip地址
Oct 19 00:19:17 template systemctl[4202]: [systemctl stop nginx] called by PID 2385 (-bash)
Oct 19 00:19:17 template systemd[1]: Stopping The nginx HTTP and reverse proxy server...
Oct 19 00:19:17 template systemd[1]: nginx.service: Deactivated successfully.
Oct 19 00:19:17 template systemd[1]: Stopped The nginx HTTP and reverse proxy server.
Oct 19 00:19:18 template Keepalived_vrrp[3816]: Script `nginx_check` now returning 10
Oct 19 00:19:18 template Keepalived_vrrp[3816]: VRRP_Script(nginx_check) failed (exited with status 10)
Oct 19 00:19:18 template NetworkManager[855]: <info> [1760804358.0874] policy: set-hostname: current hostname was changed outside NetworkManager: 'server'
Oct 19 00:19:18 template Keepalived_vrrp[3816]: (lvs1) Entering FAULT STATE
Oct 19 00:19:18 template Keepalived_vrrp[3816]: (lvs1) sent 0 priority
Oct 19 00:19:18 template Keepalived_vrrp[3816]: (lvs1) removing VIPs.
[root@node1 keepalived]# ip a | grep ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group
inet 192.168.50.21/24 brd 192.168.50.255 scope global noprefixroute ens33
inet 192.168.50.100/24 scope global secondary ens33
# 恢复业务,发现浮动ip回来了
[root@server keepalived]# systemctl start nginx
Oct 19 00:20:29 template systemctl[4281]: [systemctl start nginx] called by PID 2385 (-bash)
Oct 19 00:20:29 template systemd[1]: Starting The nginx HTTP and reverse proxy server...
Oct 19 00:20:29 template nginx[4286]: nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
Oct 19 00:20:29 template nginx[4286]: nginx: configuration file /etc/nginx/nginx.conf test is successful
Oct 19 00:20:29 template systemd[1]: Started The nginx HTTP and reverse proxy server.
Oct 19 00:20:30 template Keepalived_vrrp[3816]: Script `nginx_check` now returning 0
Oct 19 00:20:30 template Keepalived_vrrp[3816]: VRRP_Script(nginx_check) succeeded
Oct 19 00:20:30 template Keepalived_vrrp[3816]: (lvs1) Entering BACKUP STATE
Oct 19 00:20:30 template Keepalived_vrrp[3816]: (lvs1) received lower priority (100) advert from 192.168.50.21 - discarding
Oct 19 00:20:31 template Keepalived_vrrp[3816]: (lvs1) received lower priority (100) advert from 192.168.50.21 - discarding
Oct 19 00:20:32 template Keepalived_vrrp[3816]: (lvs1) received lower priority (100) advert from 192.168.50.21 - discarding
Oct 19 00:20:33 template Keepalived_vrrp[3816]: (lvs1) Receive advertisement timeout
Oct 19 00:20:33 template Keepalived_vrrp[3816]: (lvs1) Entering MASTER STATE
Oct 19 00:20:33 template NetworkManager[855]: <info> [1760804433.1051] policy: set-hostname: current hostname was changed outside NetworkManager: 'server'
Oct 19 00:20:33 template Keepalived_vrrp[3816]: (lvs1) setting VIPs.
Oct 19 00:20:33 template Keepalived_vrrp[3816]: (lvs1) Sending/queueing gratuitous ARPs on ens33 for 192.168.50.100
- 就是可以发现这个脚本是在运行的,只不是不是那么容易观察到的,可以写一个date命令脚本来发现在运行的
3、keepalived+lvs
3.1 拓补图
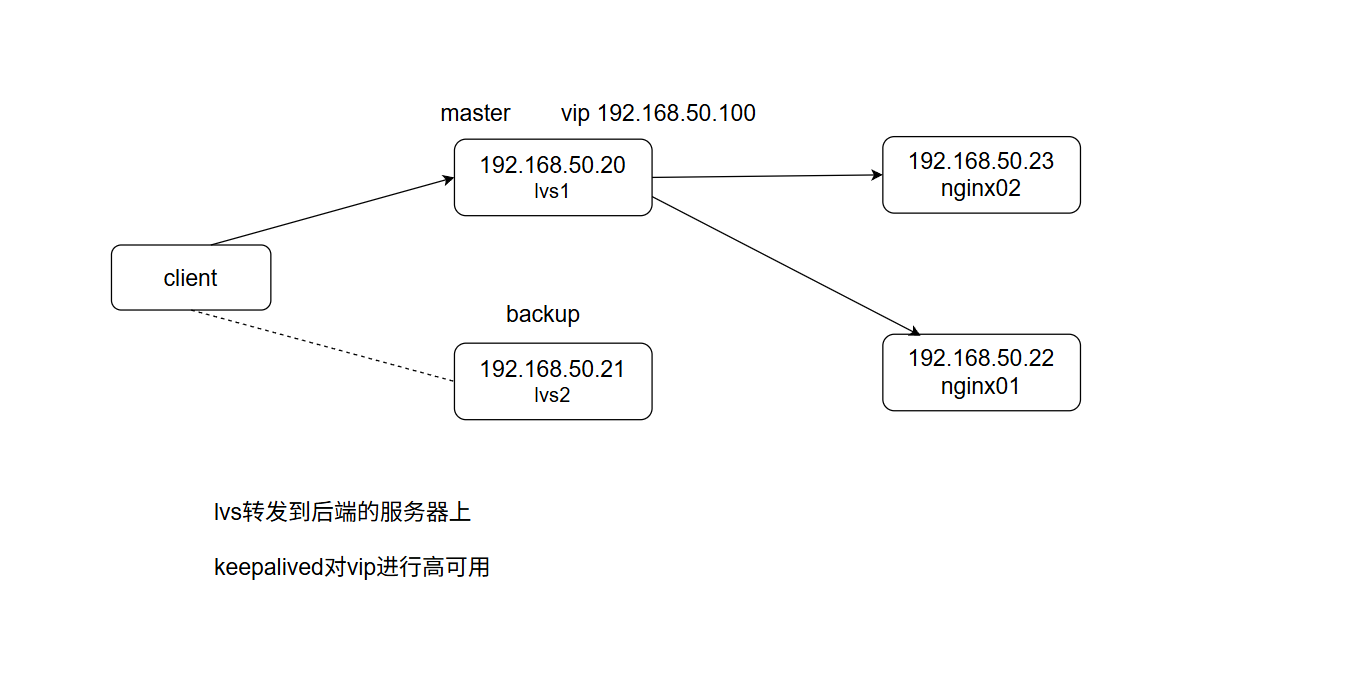
-
4个机器
-
就是对这个vip进行高可用
-
健康检查使用http_check就行了,不需要使用脚本检查
3.2 配置文件更改
[root@lvs1 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs1
}
vrrp_instance lvs1 {
state MASTER
interface ens33
virtual_router_id 10
priority 255
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.50.100/24
}
}
virtual_server 192.168.50.100 80 { # 虚拟vip 端口
delay_loop 6 # 每隔6秒检查后端服务器的状态,如果发现故障,自动的移除列表
lb_algo rr # 负载均衡算法,轮询的
lb_kind DR # 负载均衡模式,直接路由模式 DR模式
# persistence_timeout 50 # 持久化连接,就是在50秒之内,同一个ip请求发送到同一个服务器上面,这里为了演示负载均衡注释掉了
protocol TCP # 使用传输层协议
real_server 192.168.50.11 80 { # 后端真实服务器
weight 1 # 权重,越大分配的请求越多
HTTP_GET { # 健康检查的方式
url {
path / # 访问的是http://192.168.50.11/
status_code 200 # 期望收到200
}
connect_timeout 3 # 连接超时时间,3秒内没有连接上,认为检查失败
retry 3 # 重试次数为3次,一次检查失败,重试3次,重试3次都失败,认为服务器宕机
delay_before_retry 3 # 每次重试前等待的时间为3秒
}
}
real_server 192.168.50.22 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
# 备用节点配置
[root@lvs2 keepalived]# cat keepalived.conf
! Configuration File for keepalived
global_defs {
router_id lvs2
}
vrrp_instance lvs2 {
state BACKUP
interface ens33
virtual_router_id 10
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.50.100/24
}
}
virtual_server 192.168.50.100 80 {
delay_loop 6
lb_algo rr
lb_kind DR
# persistence_timeout 50
protocol TCP
real_server 192.168.50.11 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
retry 3
delay_before_retry 3
}
}
real_server 192.168.50.22 80 {
weight 1
HTTP_GET { # 这个http_get健康检查,后端服务
url {
path /
status_code 200
}
connect_timeout 3
retry 3
delay_before_retry 3
}
}
}
3.3 后端业务配置
echo node1 > index.html
echo "node2" > index.html
3.4 ipvsadm查看和配置后端服务arp屏蔽
# 写完配置文件后,启动这些配置会自动的生效
[root@lvs1 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.50.100:80 rr
-> 192.168.50.11:80 Route 1 0 0
-> 192.168.50.22:80 Route 1 0 0
配置lvs 内核参数
# 2个LVS节点都需要做
sysctl -w net.ipv4.ip_forward=1
[root@lvs1 keepalived]# sysctl -a | grep net.ipv4.ip_forward
net.ipv4.ip_forward = 1
屏蔽arp和配置环回接口
# 2个后端服务器都需要完成
[root@nginx1 html]# nmcli connection add type dummy ifname dummy2 con-name dummy2 ipv4.method manual ipv4.addresses 192.168.50.100/24 autoconnect yes
Connection 'dummy2' (8b8a3477-cd61-4e5d-97ba-071c7f0e8c4d) successfully added.
[root@nginx1 html]# cat /etc/sysctl.conf
net.ipv4.conf.all.arp_ignore=1
net.ipv4.conf.dummy2.arp_ignore=1
net.ipv4.conf.all.arp_announce=2
net.ipv4.conf.dummy2.arp_announce=2
# 生效配置
sysctl -p /etc/sysctl.conf
3.5 测试
[C:\~]$ curl 192.168.50.100 -s
node1
[C:\~]$ curl 192.168.50.100 -s
node2
3.5.1 停掉一个keepalived服务
[root@lvs1 keepalived]# systemctl stop keepalived.service
# lvs信息也都没有了,vip地址也被转移了
[root@lvs1 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
测试
[C:\~]$ curl 192.168.50.100 -s
node2
[C:\~]$ curl 192.168.50.100 -s
node1
# 发现服务没有受到任何影响
3.5.2 停掉一个业务服务(nginx)
-
先将上面的keepalived恢复
-
停掉一个nginx的话,ipvsadm会自动的将故障的移除掉,后端服务器的请求不会转发到故障的上面
[root@lvs1 keepalived]# systemctl start keepalived.service
# 停掉一个nginx后,这个ipvsadm会自动移除这个故障服务器,因为有这个http_get健康检查
[root@nginx1 html]# systemctl stop nginx
[root@lvs1 keepalived]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.50.100:80 rr
-> 192.168.50.22:80 Route 1 0 11
测试
# 将请求转发到正常的后端服务器上了
[C:\~]$ curl 192.168.50.100 -s
node2
[C:\~]$ curl 192.168.50.100 -s
node2
3.5.3 怎么切换vip
-
发现,后端服务器nginx,状态怎么样,不会实现vip的漂移
-
vip的漂移只关心这个keepalvied的状态
-
可以写一个脚本,检测后端服务器
#!/bin/bash
# /etc/keepalived/check_backends.sh
# 获取LVS中可用的真实服务器数量
available_rs=$(ipvsadm -ln | grep -c "Route")
# 如果没有可用的真实服务器
if [ $available_rs -eq 0 ]; then
exit 1 # 触发优先级降低
else
exit 0 # 正常
fi
# 如果这个keepalived对应的后端服务器一个都没有,则切换到另外备用节点
3.5.4 为什么lvs节点访问vip没有反应了?
-
恰恰证明lvs+keepalived配置是对的
-
dr模式,这个lvs节点只负责转发请求,不负责接收回来的请求
-
也就是回包的时候不经过这个LVS节点
四、总结
-
keepalvied实现高可用,通过这个VRRP2协议来实现的,心跳检查
-
对后端服务器的健康检查,lvs和keepalived
-
解决了单点故障
- keepalived有这个vip,当主服务器出现了故障后,能够快速的将这个vip切换到备用服务器,保证了服务的高可用,保证了服务的稳定运行
-
vrrp2协议
- 主要就是靠这个协议,进行心跳检查,主备之间进行检查,当发现主服务器故障的时候,自动切换到备用服务器上
-
keepalvied+lvs
-
对这个vip进行高可用了,一个主lvs机器故障时,切换到另外一个备用lvs机器提供服务
-
客户端访问这个vip,lvs进行转发到后端上面
-
五、生产环境中怎么实现
-
keepalived+lvs
-
keepalived+haproxy
-
keepalived+nginx
# nginx的负载均衡,反向代理到2台服务器上面,
# nginx里面的话,需要将server_name 改成 vip地址即可,还需要配置一个nginx服务检查的脚本
主备或者双主模式都是可以的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号