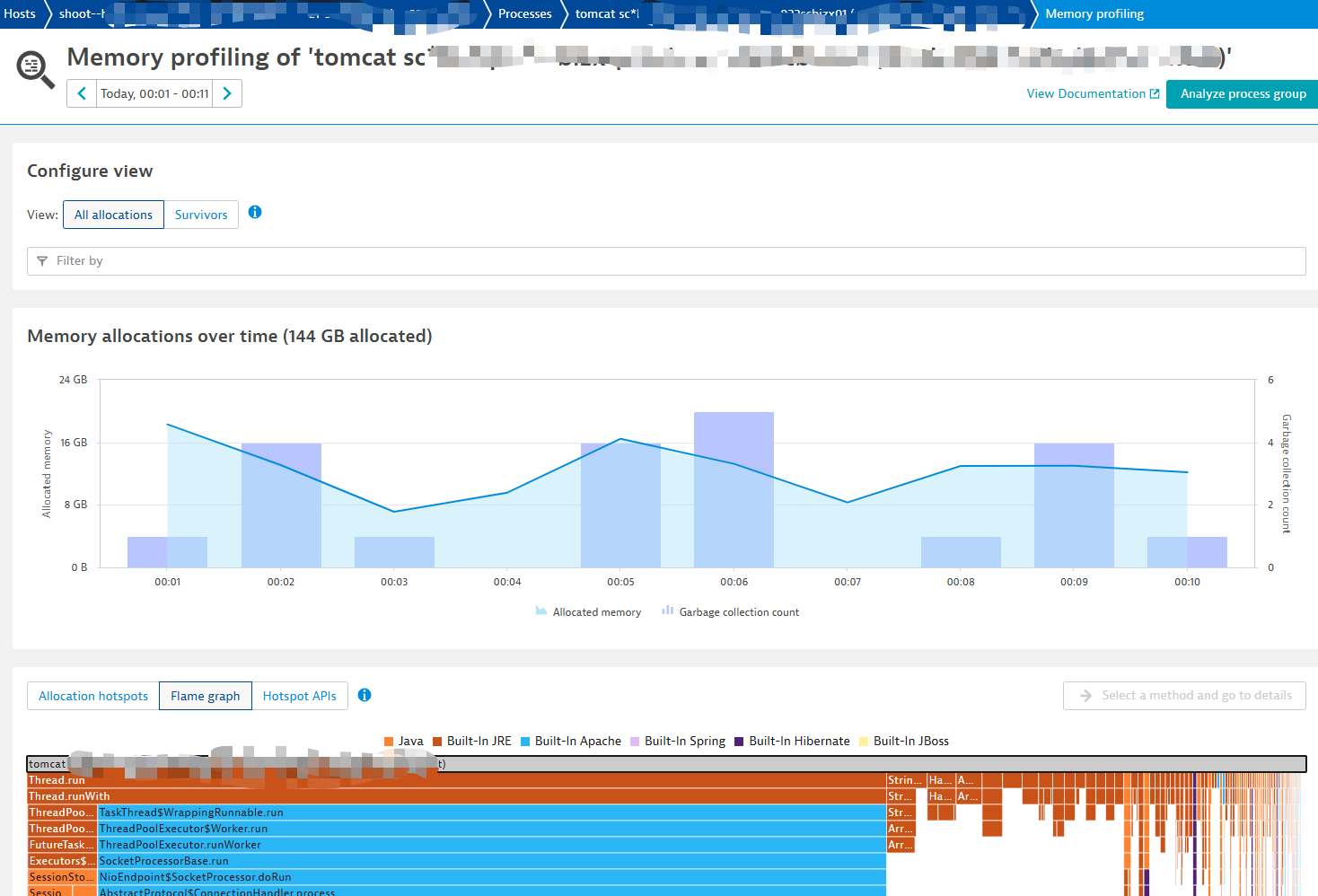
JVM Memory Profiling
Async Profiler
最近一直忙着搞AI 的application adoption, 都没空记录点东西。 趁着最近有个memory的profiling,记录一下如何进行memory profiling.
对于大部分大厂,应该有成熟的监控工具,比如dynatrace,消费级产品使用起来很方便。这里不详细介绍。
Dynatrace有个很方便的火焰图,对于本地我也想要这个效果,那么你可以使用 Async Profiler。
安装
去这里安装 Async Profiler
这里是文档
Quick Start(本地最常用三连):
asprof -d 30 -e cpu -o flamegraph -f cpu.html <PID>
asprof -d 30 -e alloc --total -o flamegraph -f alloc.html <PID>
asprof -d 30 -e alloc --live -o flamegraph -f heap.html <PID>
CPU 看热点;alloc 看高频瞬时分配;alloc --live 看仍存活对象来源(等价于之前的 -e heap)。
基本操作
asprof 提供了 start, stop, dump, status 等基本操作,可以更灵活地控制采样过程。-d 参数只是 start -> sleep -> stop 的一个快捷方式。
start: 启动采样。分析器会持续在后台运行。stop: 停止采样并输出报告。dump: 在不停止采样的情况下,生成一份当前已采集数据的快照。status: 查看当前采样状态。
例如,你可以手动开始,在需要的时候dump,最后再停止:
# 启动CPU采样
asprof start -e cpu <PID>
# ... 执行一些操作后 ...
# dump出一份火焰图,但采样并未停止
asprof dump -o flamegraph -f cpu-dump-1.html <PID>
# ... 再次执行一些操作 ...
# 停止采样并生成最终报告
asprof stop -o flamegraph -f cpu-final.html <PID>
JFR + JMC
Quick Start
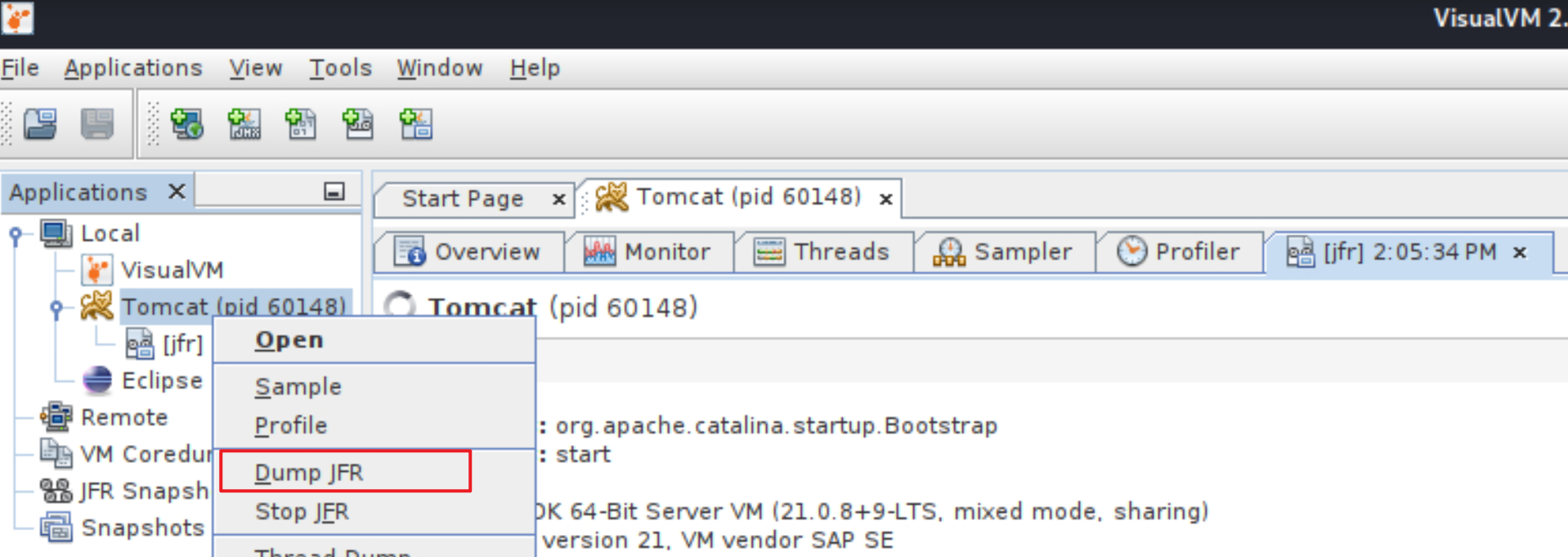
Use VisualVM 创建一个JFR,或者你也可以用命令行,如下图
在JMC里查看
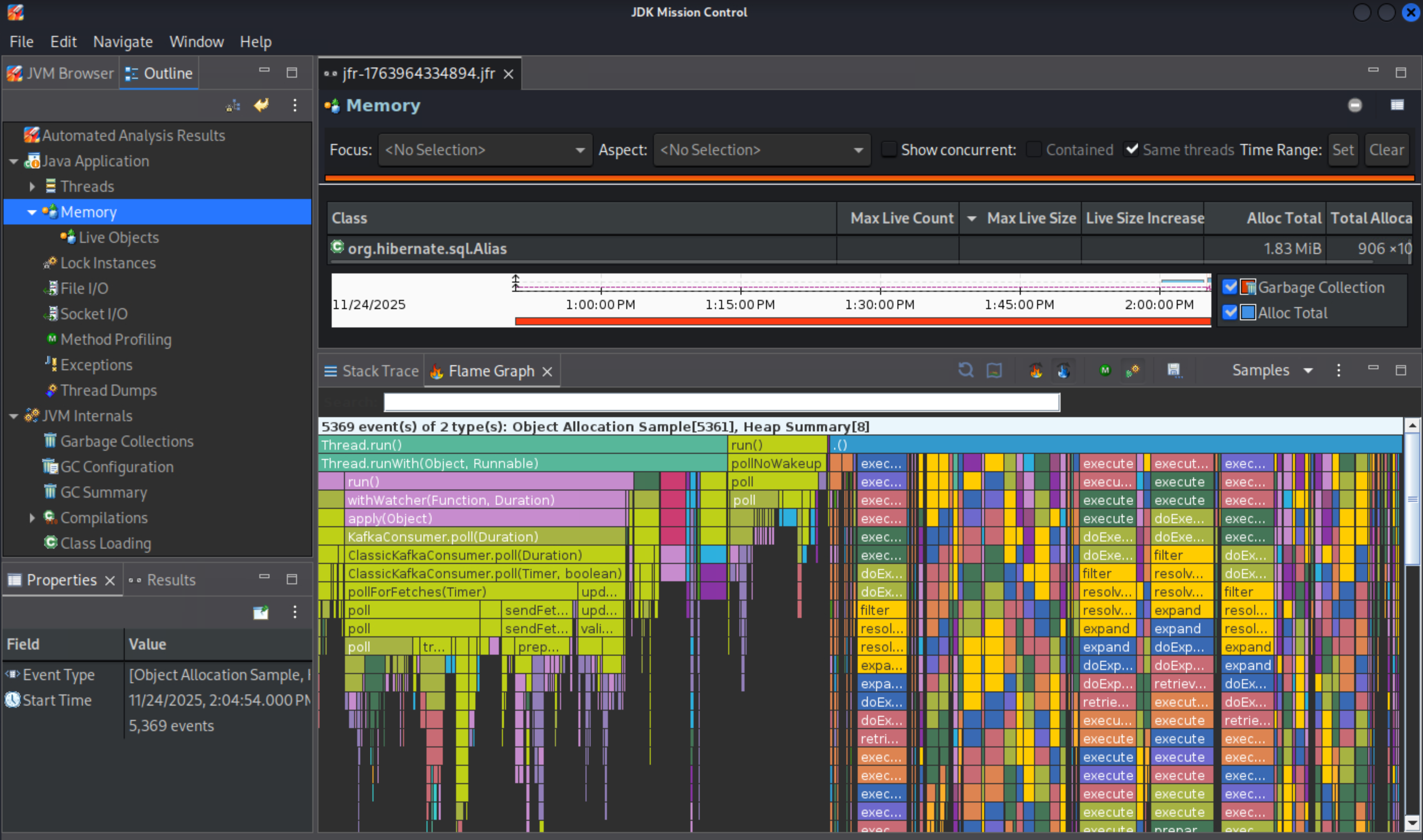
JFR+JMC功能很强大,可以进行很多topic的profiling,比如cpu,锁。
为什么用 JFR
- 低开销(生产可常驻,默认 <1%)
- 事件维度丰富:GC、线程、锁、IO、类加载、编译、内存、CPU 样本
- 时间线视图 + 事件过滤,适合定位“某一时刻发生了什么”
启动方式
命令行临时采样 (60s):
jcmd <PID> JFR.start name=diag settings=profile duration=60s filename=app.jfr
持续后台:
jcmd <PID> JFR.start name=bg settings=default disk=true maxage=30m maxsize=256m filename=rolling.jfr
停止:
jcmd <PID> JFR.stop name=bg
常用 settings
- default: 低开销,适合长期
- profile: 更多采样 (ExecutionSample, AllocationInNewTLAB 等)
- 自定义: 基于 JMC 导出 .jfc 修改事件频率后再加载
关键事件关注
| 场景 | 事件 |
|---|---|
| CPU 热点 | ExecutionSample, NativeMethodSample |
| GC 频繁 | GCHeapSummary, GCPhasePause, GCPromotionFailed |
| 锁竞争 | JavaMonitorEnter, ThreadPark, SynchronizerStatistics |
| 内存膨胀 | ObjectCountAfterGC, AllocationInNewTLAB, AllocationOutsideTLAB |
| 类加载慢 | ClassLoad, ClassDefine |
| JIT 延迟 | Compilation, CodeCacheConfiguration |
典型分析工作流
- 发现延迟抖动 → 看 GCPhasePause 是否与高延迟对齐
- 线程阻塞多 → 检查 JavaMonitorEnter / ThreadPark 的堆栈
- CPU 飙升 → ExecutionSample → 展开最宽栈帧 → 对应业务热点
- OOM 前兆 → AllocationOutsideTLAB + ObjectCountAfterGC 变化趋势
- 启动慢 → ClassLoad + Compilation 时间线
与 Async Profiler 联合
- 先用 JFR 获取宏观事件时间线 (GC/锁/线程状态)
- 再用 async-profiler 针对其中一段时间做精细火焰图(CPU / alloc / live)
- 可用
asprof --jfrsync profile -f combined.jfr <PID>直接生成含采样的 JFR - 对比:JFR 的 ExecutionSample 频率低;async-profiler 更精准栈 + 非安全点采样
常见问题
| 问题 | 处理 |
|---|---|
| 文件过大 | 使用 maxage + maxsize 滚动 |
| ExecutionSample 缺失业务栈 | 加 -XX:+DebugNonSafepoints |
| 锁事件少 | 真实没竞争或 settings 过滤,换 profile / 调高 period |
| 无分配事件 | 默认 settings 不含分配,改用 profile 或自定义开启 Allocation* |
自定义 .jfc 要点
- 降低频率:只保留需要的 10~20 个事件
- 关闭不看的网络/文件事件以减小体积
- 增 AllocationInNewTLAB / OutsideTLAB 时注意开销
分析技巧
- 时间线对齐:选中高延迟点 → “Show Related Events”
- 线程过滤:锁问题先按“Blocked Time”排序
- 频繁小 GC:看 TLAB 分配速率是否异常
- 代码缓存满:关注 CodeCacheFull / Compilation 完成率
何时不用 JFR
- 只需一次性的极短 CPU 火焰图 → 直接 async-profiler
- 容器极度受限无法写入文件 → 退化为简单采样
- 超短压测 (<10s) → JFR 事件密度低,优先采样器
快速决策表
| 目标 | 优选 |
|---|---|
| 持续运行监控 | JFR default |
| 细粒度热点 | async-profiler cpu |
| 瞬时分配压力 | async-profiler alloc --total |
| 内存泄漏来源 | async-profiler alloc --live + JFR ObjectCountAfterGC |
| 线程阻塞 | JFR JavaMonitorEnter + ThreadPark |
| GC 停顿归因 | JFR GCPhasePause + Safepoint (若启用) |
输出管理
- 定期打包: cron 收集 *.jfr → 压缩归档
- 安全: 包含类名/路径,需内部环境使用
- 解析: JMC GUI 或
jfr print --events <event> file.jfr
收尾
采样前后做基线对比;事件与火焰图交叉验证,避免单点误判;关注趋势而非单次尖峰。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号