


设计思想:采用分而治之的降维思想,把这个大的问题最简化,把每一个函数里封装一个最基本的操作
出现的问题:查看常用短语没有实现
源代码:
1 package main; 2 3 import java.io.BufferedReader; 4 import java.io.File; 5 import java.io.FileInputStream; 6 import java.io.FileOutputStream; 7 import java.io.IOException; 8 import java.io.InputStreamReader; 9 import java.io.OutputStreamWriter; 10 import java.text.DecimalFormat; 11 import java.util.HashMap; 12 import java.util.Map; 13 import java.util.Scanner; 14 15 16 17 18 public class demo { 19 public static Map<String,Integer> map1=new HashMap<String,Integer>(); 20 static int g_Wordcount[]=new int[27]; 21 static int g_Num[]=new int[27]; 22 23 static String []unUse=new String[] { 24 "it", 25 "in", 26 "to", 27 "of", 28 "the", 29 "and", 30 "that", 31 "for" 32 }; 33 34 public static void main(String arg[]) { 35 menu(); 36 37 } 38 public static void menu() 39 { 40 Scanner cin=new Scanner(System.in); 41 int command; 42 while (true) 43 { 44 45 System.out.println("功能如下,请按照需要输入功能编号"); 46 System.out.println("0:统计字母"); 47 System.out.println("1:统计单词"); 48 System.out.println("2:统计前N个单词"); 49 System.out.println("请输入"); 50 command=cin.nextInt(); 51 int N; 52 if ((command==0)||(command==1)||(command==2)) 53 { 54 switch (command) 55 { 56 case 0: 57 mathmaticnumber(); 58 break; 59 case 1: 60 daoruFiles("src/newAnalysis.txt","tongji"); 61 break; 62 case 2: 63 System.out.println("请输入想查看的单词个数"); 64 N=cin.nextInt(); 65 NdaoruFiles("src/newAnalysis.txt","tongji",N); 66 break; 67 68 default:System.out.println("输入错误"); 69 break; 70 } 71 break;// 结束循环 72 } else 73 { 74 System.out.println("错误,请重新输入");// 继续循环,即跳转到上一步 75 } 76 } 77 78 } 79 private static void NdaoruFiles(String a, String dc, int N) 80 { 81 map1.clear(); 82 try { 83 daoru(a); 84 } catch (IOException e) { 85 // TODO 自动生成的 catch 块 86 e.printStackTrace(); 87 88 } 89 String sz[]; 90 Integer num[]; 91 final int MAXNUM=N; //统计的单词出现最多的前n个的个数 92 93 for(int i=0;i<g_Wordcount.length;i++) 94 { 95 g_Wordcount[i]=0; 96 g_Num[i]=i; 97 } 98 99 sz=new String[MAXNUM+1]; 100 num=new Integer[MAXNUM+1]; 101 demo demo=new demo(); 102 int account =1; 103 //Vector<String> ve1=new Vector<String>(); 104 try { 105 daoru(a); 106 } catch (IOException e) { 107 // TODO 自动生成的 catch 块 108 e.printStackTrace(); 109 } 110 System.out.println("英文单词的出现情况如下:"); 111 int g_run=0; 112 113 for(g_run=0;g_run<MAXNUM+1;g_run++) 114 { 115 account=1; 116 for(Map.Entry<String,Integer> it : demo.map1.entrySet()) 117 { 118 if(account==1) 119 { 120 sz[g_run]=it.getKey(); 121 num[g_run]=it.getValue(); 122 account=2; 123 } 124 if(account==0) 125 { 126 account=1; 127 continue; 128 } 129 if(num[g_run]<it.getValue()) 130 { 131 sz[g_run]=it.getKey(); 132 num[g_run]=it.getValue(); 133 } 134 //System.out.println("英文单词: "+it.getKey()+" 该英文单词出现次数: "+it.getValue()); 135 } 136 demo.map1.remove(sz[g_run]); 137 } 138 int g_count=1; 139 String tx1=new String(); 140 String tx2=new String(); 141 for(int i=0;i<g_run;i++) 142 { 143 if(sz[i]==null) 144 continue; 145 if(sz[i].equals("")) 146 continue; 147 tx1+="出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]+"\r\n"; 148 System.out.println("出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]); 149 g_count++; 150 } 151 try { 152 daochu(tx1,dc+"2.txt"); 153 } catch (IOException e) { 154 // TODO 自动生成的 catch 块 155 e.printStackTrace(); 156 } 157 158 //------------------------------ 159 int temp=g_Wordcount[0]; 160 int numtemp=0; 161 for(int i=0;i<26;i++) 162 { 163 for(int j=i;j<26;j++) 164 { 165 if(g_Wordcount[j]>g_Wordcount[i]) 166 { 167 temp=g_Wordcount[i]; 168 g_Wordcount[i]=g_Wordcount[j]; 169 g_Wordcount[j]=temp; 170 numtemp=g_Num[i]; 171 g_Num[i]=g_Num[j]; 172 g_Num[j]=numtemp; 173 174 } 175 } 176 } 177 int sum=0; 178 for(int i=0;i<26;i++) 179 { 180 sum+=g_Wordcount[i]; 181 } 182 for(int i=0;i<26;i++) 183 { 184 char c=(char) ('a'+g_Num[i]); 185 tx2+=c+":"+String.format("%.2f%% \r\n", (double)g_Wordcount[i]/sum*100); 186 } 187 try { 188 daochu(tx2,dc+"1.txt"); 189 } catch (IOException e) { 190 // TODO 自动生成的 catch 块 191 e.printStackTrace(); 192 } 193 194 195 } 196 public static void daoruFiles(String a,String dc) 197 { 198 map1.clear(); 199 try { 200 daoru(a); 201 } catch (IOException e) { 202 // TODO 自动生成的 catch 块 203 e.printStackTrace(); 204 205 } 206 String sz[]; 207 Integer num[]; 208 final int MAXNUM=20000; 209 210 for(int i=0;i<g_Wordcount.length;i++) 211 { 212 g_Wordcount[i]=0; 213 g_Num[i]=i; 214 } 215 216 sz=new String[MAXNUM+1]; 217 num=new Integer[MAXNUM+1]; 218 demo demo=new demo(); 219 int account =1; 220 //Vector<String> ve1=new Vector<String>(); 221 try { 222 daoru(a); 223 } catch (IOException e) { 224 // TODO 自动生成的 catch 块 225 e.printStackTrace(); 226 } 227 System.out.println("英文单词的出现情况如下:"); 228 int g_run=0; 229 230 for(g_run=0;g_run<MAXNUM+1;g_run++) 231 { 232 account=1; 233 for(Map.Entry<String,Integer> it : demo.map1.entrySet()) 234 { 235 if(account==1) 236 { 237 sz[g_run]=it.getKey(); 238 num[g_run]=it.getValue(); 239 account=2; 240 } 241 if(account==0) 242 { 243 account=1; 244 continue; 245 } 246 if(num[g_run]<it.getValue()) 247 { 248 sz[g_run]=it.getKey(); 249 num[g_run]=it.getValue(); 250 } 251 //System.out.println("英文单词: "+it.getKey()+" 该英文单词出现次数: "+it.getValue()); 252 } 253 demo.map1.remove(sz[g_run]); 254 } 255 int g_count=1; 256 String tx1=new String(); 257 String tx2=new String(); 258 for(int i=0;i<g_run;i++) 259 { 260 if(sz[i]==null) 261 continue; 262 if(sz[i].equals("")) 263 continue; 264 tx1+="出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]+"\r\n"; 265 System.out.println("出现次数第"+(g_count)+"多的单词为:"+sz[i]+"\t\t\t出现次数: "+num[i]); 266 g_count++; 267 } 268 try { 269 daochu(tx1,dc+"2.txt"); 270 } catch (IOException e) { 271 // TODO 自动生成的 catch 块 272 e.printStackTrace(); 273 } 274 275 //------------------------------ 276 int temp=g_Wordcount[0]; 277 int numtemp=0; 278 for(int i=0;i<26;i++) 279 { 280 for(int j=i;j<26;j++) 281 { 282 if(g_Wordcount[j]>g_Wordcount[i]) 283 { 284 temp=g_Wordcount[i]; 285 g_Wordcount[i]=g_Wordcount[j]; 286 g_Wordcount[j]=temp; 287 numtemp=g_Num[i]; 288 g_Num[i]=g_Num[j]; 289 g_Num[j]=numtemp; 290 291 } 292 } 293 } 294 int sum=0; 295 for(int i=0;i<26;i++) 296 { 297 sum+=g_Wordcount[i]; 298 } 299 for(int i=0;i<26;i++) 300 { 301 char c=(char) ('a'+g_Num[i]); 302 tx2+=c+":"+String.format("%.2f%% \r\n", (double)g_Wordcount[i]/sum*100); 303 } 304 try { 305 daochu(tx2,dc+"1.txt"); 306 } catch (IOException e) { 307 // TODO 自动生成的 catch 块 308 e.printStackTrace(); 309 } 310 311 //------------------------------ 312 313 } 314 public static void daoru(String s) throws IOException 315 { 316 317 File a=new File(s); 318 FileInputStream b = new FileInputStream(a); 319 InputStreamReader c=new InputStreamReader(b,"UTF-8"); 320 String string2=new String(""); 321 while(c.ready()) 322 { 323 char string1=(char) c.read(); 324 if(WordNum(string1)>=0) 325 { 326 g_Wordcount[WordNum(string1)]+=1; 327 } 328 329 //------------------------ 330 if(!isWord(string1)) 331 { 332 if(!isBaseWord(string2)) 333 { 334 if(map1.containsKey(string2.toLowerCase())) 335 { 336 Integer num1=map1.get(string2.toLowerCase())+1; 337 map1.put(string2.toLowerCase(),num1); 338 } 339 else 340 { 341 Integer num1=1; 342 map1.put(string2.toLowerCase(),num1); 343 } 344 } 345 string2=""; 346 } 347 else 348 { 349 if(isInitWord(string1)) 350 { 351 string2+=string1; 352 } 353 } 354 } 355 if(!string2.isEmpty()) 356 { 357 if(!isBaseWord(string2)) 358 { 359 if(map1.containsKey(string2.toLowerCase())) 360 { 361 Integer num1=map1.get(string2.toLowerCase())+1; 362 map1.put(string2.toLowerCase(),num1); 363 } 364 else 365 { 366 Integer num1=1; 367 map1.put(string2.toLowerCase(),num1); 368 } 369 } 370 371 string2=""; 372 } 373 c.close(); 374 b.close(); 375 } 376 public static void daochu(String txt,String outfile) throws IOException 377 { 378 File fi=new File(outfile); 379 FileOutputStream fop=new FileOutputStream(fi); 380 OutputStreamWriter ops=new OutputStreamWriter(fop,"UTF-8"); 381 ops.append(txt); 382 ops.close(); 383 fop.close(); 384 } 385 public static boolean isWord(char a) 386 { 387 if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a=='\'') 388 return true; 389 return false; 390 } 391 public static boolean isInitWord(char a) 392 { 393 if(a<='z'&&a>='a'||a<='Z'&&a>='A'||a>'0'&&a<'9'||a=='\'') 394 return true; 395 return false; 396 } 397 public static boolean isBaseWord(String word) 398 { 399 for(int i=0;i<unUse.length;i++) 400 { 401 if(unUse[i].equals(word)||word.length()==1) 402 return true; 403 } 404 return false; 405 } 406 public static int WordNum(char a) 407 { 408 if(a<='z'&&a>='a') 409 return a-'a'; 410 else if(a<='Z'&&a>='A') 411 return a-'A'; 412 return -1; 413 } 414 //----递归文件夹 415 public static void traverseFolder2(String path) { 416 417 File file = new File(path); 418 if (file.exists()) { 419 File[] files = file.listFiles(); 420 if (null == files || files.length == 0) { 421 System.out.println("文件夹是空的!"); 422 return; 423 } else { 424 for (File file2 : files) { 425 if (file2.isDirectory()) { 426 System.out.println("文件夹:" + file2.getAbsolutePath()); 427 traverseFolder2(file2.getAbsolutePath()); 428 } else { 429 System.out.println("文件:" + file2.getAbsolutePath()); 430 String name=file2.getName(); 431 daoruFiles(file2.getAbsolutePath(), file2.getParentFile()+"\\"+name.replace(".txt", "")+"tongji"); 432 433 } 434 } 435 } 436 } else { 437 System.out.println("文件不存在!"); 438 } 439 } 440 441 public static void mathmaticnumber() 442 { 443 try 444 { 445 char shu[] = new char[1000000]; 446 char zimu[] = new char[52]; 447 int j = 0; 448 int count[] = new int[52]; 449 String pathname = "src/newAnalysis.txt"; 450 File filename = new File(pathname); 451 InputStreamReader reader = new InputStreamReader(new FileInputStream(filename)); 452 BufferedReader br = new BufferedReader(reader); 453 String line[] = new String[100]; 454 455 for (int i = 0; i < line.length; i++) 456 { 457 line[i] = br.readLine(); 458 System.out.println(line[i]); 459 } 460 461 br.close(); 462 int k = 0; 463 while (line[k] != null) 464 { 465 for (int i = 0; i < line[k].length(); i++) 466 { 467 shu[j] = line[k].charAt(i); 468 j++; 469 } 470 k++; 471 } 472 // 匹配表 473 for (int i = 0; i < shu.length; i++) 474 { 475 switch (shu[i]) 476 { 477 case 'a': 478 zimu[0] = 'a'; 479 count[0]++; 480 break; 481 case 'b': 482 zimu[1] = 'b'; 483 count[1]++; 484 break; 485 case 'c': 486 zimu[2] = 'c'; 487 count[2]++; 488 break; 489 case 'd': 490 zimu[3] = 'd'; 491 count[3]++; 492 break; 493 case 'e': 494 zimu[4] = 'e'; 495 count[4]++; 496 break; 497 case 'f': 498 zimu[5] = 'f'; 499 count[5]++; 500 break; 501 case 'g': 502 zimu[6] = 'g'; 503 count[6]++; 504 break; 505 case 'h': 506 zimu[7] = 'h'; 507 count[7]++; 508 break; 509 case 'i': 510 zimu[8] = 'i'; 511 count[8]++; 512 break; 513 case 'j': 514 zimu[9] = 'j'; 515 count[9]++; 516 break; 517 case 'k': 518 zimu[10] = 'k'; 519 count[10]++; 520 break; 521 case 'l': 522 zimu[11] = 'l'; 523 count[11]++; 524 break; 525 case 'm': 526 zimu[12] = 'm'; 527 count[12]++; 528 break; 529 case 'n': 530 zimu[13] = 'n'; 531 count[13]++; 532 break; 533 case 'o': 534 zimu[14] = 'o'; 535 count[14]++; 536 break; 537 case 'p': 538 zimu[15] = 'p'; 539 count[15]++; 540 break; 541 case 'q': 542 zimu[16] = 'q'; 543 count[16]++; 544 break; 545 case 'r': 546 zimu[17] = 'r'; 547 count[17]++; 548 break; 549 case 's': 550 zimu[18] = 's'; 551 count[18]++; 552 break; 553 case 't': 554 zimu[19] = 't'; 555 count[19]++; 556 break; 557 case 'u': 558 zimu[20] = 'u'; 559 count[20]++; 560 break; 561 case 'v': 562 zimu[21] = 'v'; 563 count[21]++; 564 break; 565 case 'w': 566 zimu[22] = 'w'; 567 count[22]++; 568 break; 569 case 'x': 570 zimu[23] = 'x'; 571 count[23]++; 572 break; 573 case 'y': 574 zimu[24] = 'y'; 575 count[24]++; 576 break; 577 case 'z': 578 zimu[25] = 'z'; 579 count[25]++; 580 break; 581 case 'A': 582 zimu[26] = 'A'; 583 count[26]++; 584 break; 585 case 'B': 586 zimu[27] = 'B'; 587 count[27]++; 588 break; 589 case 'C': 590 zimu[28] = 'C'; 591 count[28]++; 592 break; 593 case 'D': 594 zimu[29] = 'D'; 595 count[29]++; 596 break; 597 case 'E': 598 zimu[30] = 'E'; 599 count[30]++; 600 break; 601 case 'F': 602 zimu[31] = 'F'; 603 count[31]++; 604 break; 605 case 'G': 606 zimu[32] = 'G'; 607 count[32]++; 608 break; 609 case 'H': 610 zimu[33] = 'H'; 611 count[33]++; 612 break; 613 case 'I': 614 zimu[34] = 'I'; 615 count[34]++; 616 break; 617 case 'J': 618 zimu[35] = 'G'; 619 count[35]++; 620 break; 621 case 'K': 622 zimu[36] = 'K'; 623 count[36]++; 624 break; 625 case 'L': 626 zimu[37] = 'L'; 627 count[37]++; 628 break; 629 case 'M': 630 zimu[38] = 'M'; 631 count[38]++; 632 break; 633 case 'N': 634 zimu[39] = 'N'; 635 count[39]++; 636 break; 637 case 'O': 638 zimu[40] = 'O'; 639 count[40]++; 640 break; 641 case 'P': 642 zimu[41] = 'P'; 643 count[41]++; 644 break; 645 case 'Q': 646 zimu[42] = 'Q'; 647 count[42]++; 648 break; 649 case 'R': 650 zimu[43] = 'R'; 651 count[43]++; 652 break; 653 case 'S': 654 zimu[44] = 'S'; 655 count[44]++; 656 break; 657 case 'T': 658 zimu[45] = 'T'; 659 count[45]++; 660 break; 661 case 'U': 662 zimu[46] = 'U'; 663 count[46]++; 664 break; 665 case 'V': 666 zimu[47] = 'V'; 667 count[47]++; 668 break; 669 case 'W': 670 zimu[48] = 'W'; 671 count[48]++; 672 break; 673 case 'X': 674 zimu[49] = 'X'; 675 count[49]++; 676 break; 677 case 'Y': 678 zimu[50] = 'Y'; 679 count[50]++; 680 break; 681 case 'Z': 682 zimu[51] = 'Z'; 683 count[51]++; 684 } 685 } 686 int ci = 0; 687 int sum = 0; 688 System.out.println("短文中各字母出现情况统计如下:"); 689 for (int i = 0; i < 52; i++) 690 { 691 if (count[i] != 0) 692 { 693 ci++; 694 sum += count[i]; 695 } 696 } 697 698 ci = 0; 699 for (int i = 0; i < 52; i++) 700 { 701 if (count[i] != 0) 702 { 703 ci++; 704 System.out.println(count[i]); 705 double a = (double) ((Math.round(count[i] * 100) / 100.0) / sum) * 100; 706 double b = (double) (Math.round(a * 100) / 100.0); 707 System.out.println(ci + ".字母" + zimu[i] + "的出现次数是:" + b); 708 } 709 } 710 System.out.println("字母共计:" + sum + "个"); 711 } catch (Exception e) 712 { 713 e.printStackTrace(); 714 } 715 } 716 }
结果截图:
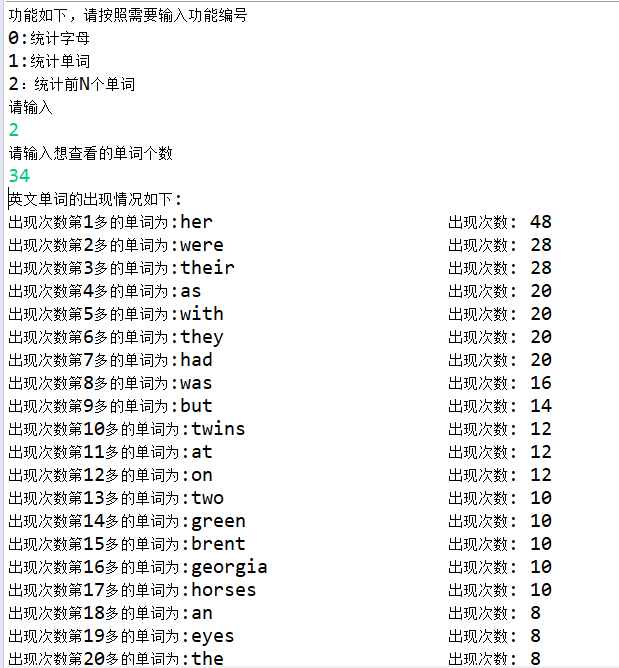
总结:通过基本训练,更加锻炼了自己对复杂问题的解决能力,复杂问题简单化,简单问题逻辑化,顺序化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号