

python 爬虫爬取bt电影天堂数据
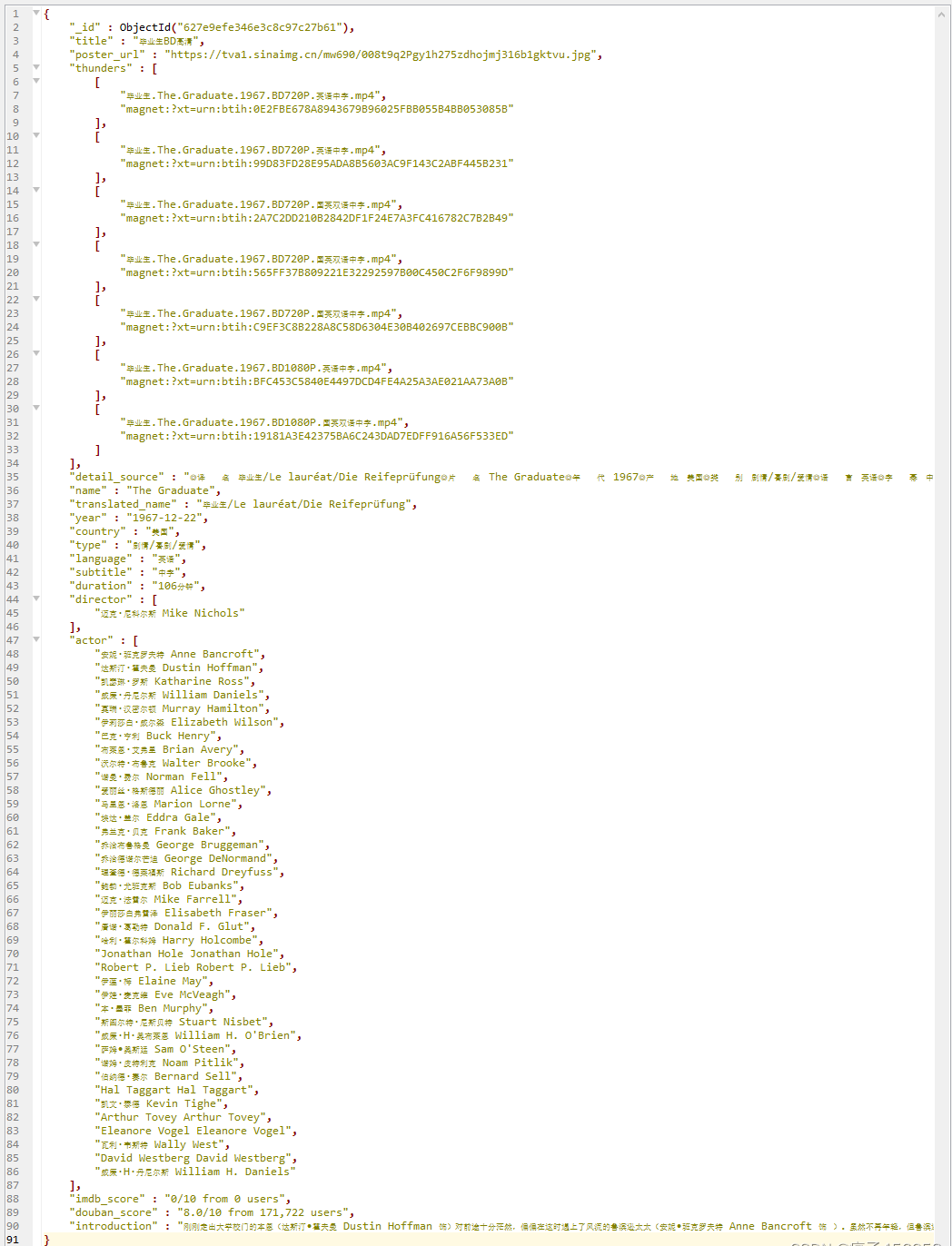
获取的数据格式如下
通过xpath插件解析定位目标位置信息,通过scrapy工具进行抓取
item_list = response.xpath("//div[@class='m-film']/ul[@class='ul-imgtxt2 row']/li")
for item in item_list:
title = item.xpath(".//div[@class='txt']//h3//font/text()").extract_first()
if title in exist_movie_titles:
print("Crawl {} existed".format(title))
continue
detail_link = item.xpath(".//div[@class='txt']//h3//a/@href").extract_first()
crawl.py 种子解析过程
soup = BeautifulSoup(resp.text, 'lxml')
thunder_div = soup.find_all(name='div', attrs={'class': 'bot'})[1]
thunder_href_list = thunder_div.find_all(name='a')
thunders = list()
for thunder_href in thunder_href_list:
href_url = thunder_href.attrs['href']
href_name = thunder_href.text
thunders.append((href_name, href_url))
bt_detail['thunders'] = thunders
包含所有关键信息:电影名、海报、导演演员列表上映时简介等详情、评分数据、以及相关的多个电影链接。
累计近22,000部电影(包括电影、电视剧、动漫、综艺和纪录片等)。
想互相学习交流的可以私信或发油件我,fengzi456258爱特163.com。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号