

HPC store data in archive (long term), submit job and run, and kill (cancel) job
1. Log in
Once you have been approved, you can access HPC from:
Within the NYU network:
ssh NYUNetID@prince.hpc.nyu.edu
2. Store Data in '/archive' (long term)
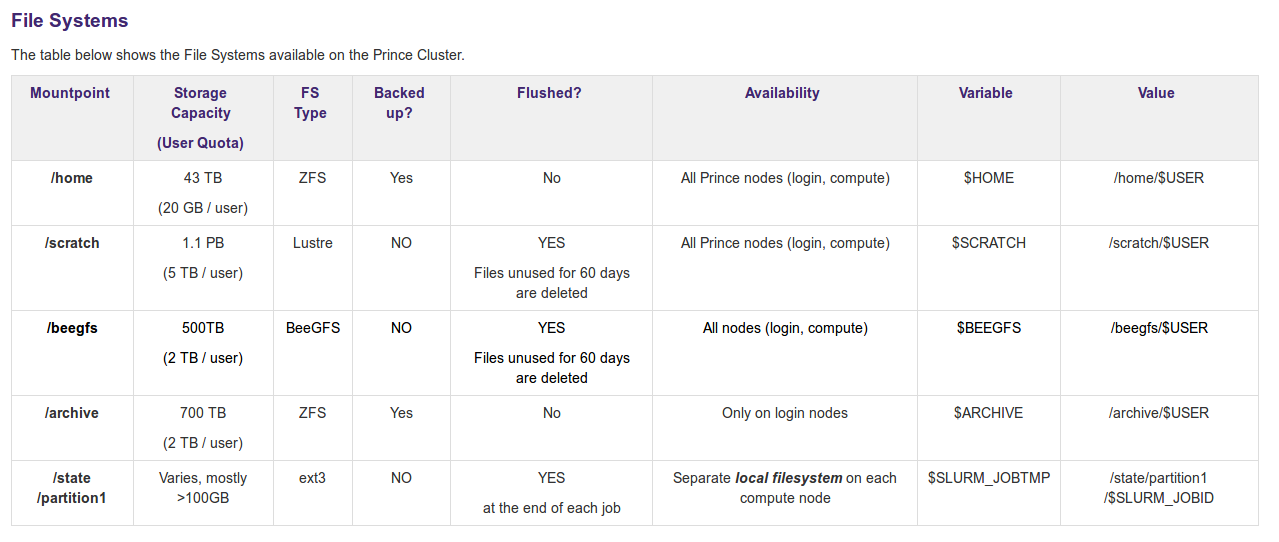
Files on scratch are NOT backed up
Files on /scratch are NOT backed up. Always backup your important data to /archive. /archive is only available on HPC login nodes, not from compute nodes.
https://wikis.nyu.edu/display/NYUHPC/Clusters+-+Prince
cd /archive/k/ky13 pwd
"can save data at /archive/k/ky13, however it can not be executed successfully by sbatch"
The best choice is : 1) copy the latest data to "/archive/" for long term storage consistently , 2) then copy data from /archive to /scratch/ for executing srcipts.
Please execute scripts on /scratch/ky13 or /home/ky13
Transfer files: Between your computer and the HPC
- A File:
scp /Users/local/data.txt NYUNetID@prince.hpc.nyu.edu:/archieve/k/NYUNetID/path/
scp /Users/local/data.txt NYUNetID@prince.hpc.nyu.edu:/archieve/k/ky13/
- A Folder:
scp -r /Users/local/path NYUNetID@prince.hpc.nyu.edu:/archive/k/NYUNetID/path/
3. Submit job and Run
A simple example
A typical batch script on an NYU Prince cluster looks something like these:
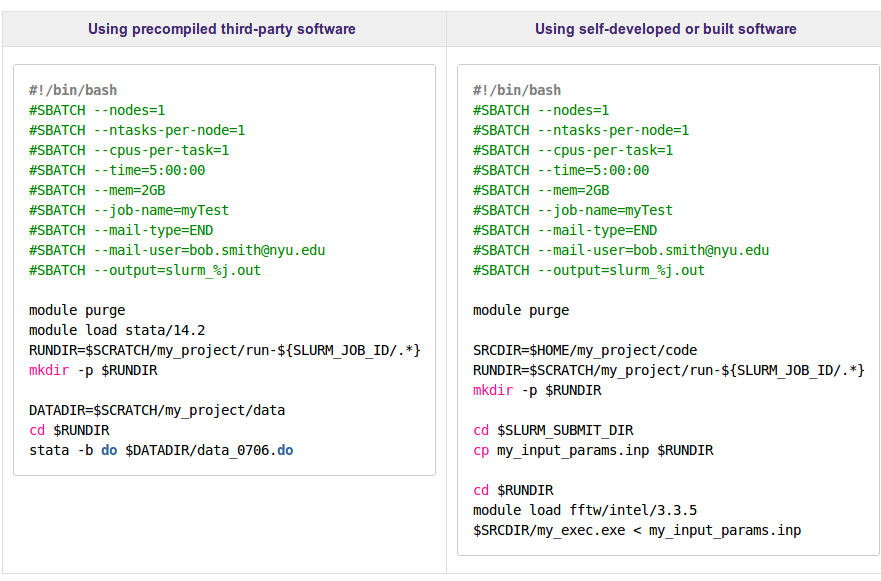
myscript.s
#!/bin/bash # the above line tells the shell how to execute this script # # job-name #SBATCH --job-name=Scapy # # need 4 nodes #SBATCH --nodes=4 #SBATCH --cpus-per-task=2 # # expect the job to finish within 5 hours. If it takes longer than 5 hours, SLURM can kill it #SBATCH --time=20:00:00 # # expect the job to use no more than 24GB of memory #SBATCH --mem=24GB # # once job ends, send me an email #SBATCH --mail-type=END #SBATCH --mail-user=xxx@xx.com # # both standard output and error are directed to the same file. #SBATCH --output=outlog_%A_%a.out ##SBATCH --error=_%A_%a.err #SBATCH --error=errlog_%A_%a.out # # first we ensure a clean running environment: module purge mkdir -p py3.6.3 # and load the module for the software we are using: module load python3/intel/3.6.3 # create the virtual environment for install new libraries which do not need sudo permissions right. virtualenv --system-site-packages py3.6.3 source py3.6.3/bin/activate pip3 install pillow pip3 install scapy #source py3.6.3/bin/activate /home/ky13/py3.6.3 cd /scratch/ky13/Experiments/xxx/Pcap2sessions_Scapy/3_pcap_parser/ python3 pcap2sessions_scapy.py
$ sbatch myscript.s
And monitor its progress (as is discussed further in here) with:
$ squeue -u $USER
https://wikis.nyu.edu/display/NYUHPC/Submitting+jobs+with+sbatch
|
|
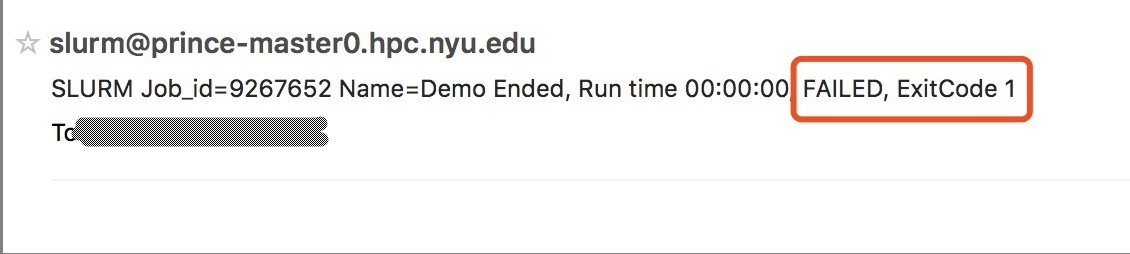
4. Issues
# submit job to nyu cluster (HPC)
>Sbatch run_scapy_pcap.sh
# check the job.
> squeue -u $USER
run_scapy_pcap.sh
#!/bin/bash # the above line tells the shell how to execute this script # # job-name #SBATCH --job-name=Scapy # # need 4 nodes #SBATCH --nodes=4 #SBATCH --cpus-per-task=2 # # expect the job to finish within 5 hours. If it takes longer than 5 hours, SLURM can kill it #SBATCH --time=40:00:00 # # expect the job to use no more than 24GB of memory #SBATCH --mem=24GB # # once job ends, send me an email #SBATCH --mail-type=END #SBATCH --mail-user=xxx@xxx.com # # both standard output and error are directed to the same file. #SBATCH --output=outlog_%A_%a.out ##SBATCH --error=_%A_%a.err #SBATCH --error=errlog_%A_%a.out # # first we ensure a clean running environment: module purge mkdir -p py3.6.3 # and load the module for the software we are using: module load python3/intel/3.6.3 # create the virtual environment for install new libraries which do not need sudo permissions right. virtualenv --system-site-packages py3.6.3 source py3.6.3/bin/activate pip3 install pillow pip3 install scapy #source py3.6.3/bin/activate /home/ky13/py3.6.3 cd /scratch/ky13/Experiments/application_classification_project_201806/Pcap2Sessions_Scapy/3_pcap_parser/ python3 pcap2sessions_scapy.py -i '../../VPN_NonVPN_2016_Dataset/' -o './log.txt'
Issue 1:

https://bugs.schedmd.com/show_bug.cgi?id=3214#c4
>sacct -o JobID,ReqMem,MaxVMSize,MaxRSS,MaxRSSTask,State,NodeList -j 9281183

Note: 9281183 is JobID.
Solution:
The codes is not implemented by distributed code, so it always only run in single node, even I request 4 nodes.
# need 4 nodes
## SBATCH --nodes=4
#SBATCH --nodes=1
#SBATCH --cpus-per-task=8
To kill a running job, or remove a queued job from the queue, use scancel:
$ scancel jobid
To cancel ALL of your jobs:
$ scancel -u NetID
References:
1. https://wikis.nyu.edu/display/NYUHPC/Scratch+area+cleanup
2. https://wikis.nyu.edu/display/NYUHPC/Cancelling+batch+jobs+at+Prince
posted on 2018-10-14 23:53 Quinn-Yann 阅读(583) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号