深度学习入门(9):与学习相关技巧
随机梯度下降的实现
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self,params,grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-10,10,100)
y = np.linspace(-10,10,100)
x,y = np.meshgrid(x,y)
z = 1/20*x**2+y**2
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_surface(x, y, z)
plt.show()
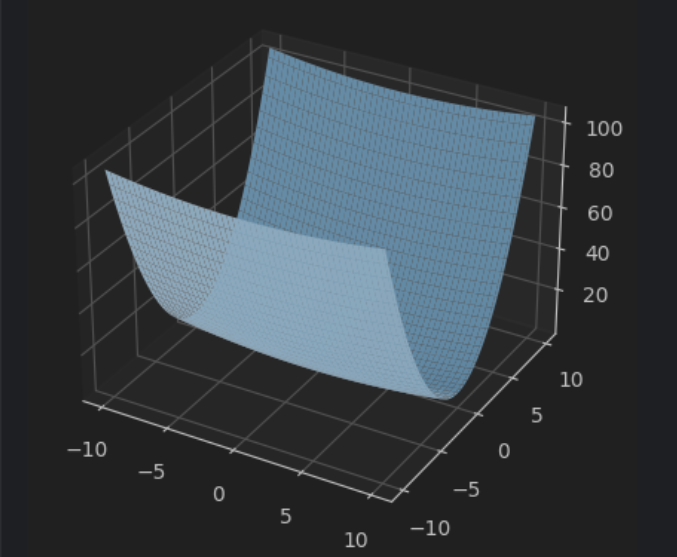
遇见这种函数时候随机梯度下降法的效率不高,所以引出其他的方法求最优解
Momentum
class Momentum:
def __init__(self, lr=0.01,momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self,params,grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] += self.lr * grads[key]
params[key] += self.v[key]
AdaGrad
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self,params,grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= (self.lr * grads[key] /
(np.sqrt(self.h[key])+ 1e-7))
Adam
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
Dropout实现
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self,x,train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape)>self.dropout_ratio
return x*self.mask
else:
return x*(1.0 - self.dropout_ratio)
def backward(self,dout):
return dout*self.mask
参考资料
《深度学习入门:基于python的理论与实践》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号