Python 基础函数、解包
名词解释-函数:
在程序设计中,函数是指用于进行某种计算的一系列语句的有名称的组合。
定义一个函数时,需要指定函数的名称并写下一系列程序语句。定义时不会执行,运行代码时,先加载进内存中,之后使用名称来调用这个函数。
定义一个函数会创建一个函数对象,其类型为"function",要调用它才会执行。
(一).函数的命名规则
与变量一样,参考官方推荐的命名格式:function_name。小写+下划线
(二).形参与实参
形参:定义函数时,设置的参数名字。没有实际意义的,只是个名字。
实参:调用参数时,设置的具体内容。有实际的意义,是具体存在的。
一、函数参数类型
(一).没有参数
(二).必备参数:调用时,必须传参数。
(三).默认参数:调用时,参数可传可不传。不传参,就是默认值;传了参就覆盖。参数名要相同!值可以不一样。
(四).可选参数(分为两种):
(1).不定长参数:
语法:fun(*args) 星号"*"必须要有,是关键字。args是变量名,一般写成*args(约定成俗),随便传什么都可以。
传参时,任何元素都会被包装成元组。
调用时:fun(*[1,2]) 加个*,就是把里面的壳去掉了,解包 -> (1,2)
例外:fun(*{1,2}) -> {1,} 字典的话,只剩键了。
(2).关键字参数:
fun(**kwargs) 例:fun(a=1, b=2) -> {"a":1, "b":2}。包装成字典。要遵循变量命名的规则!
这种情况:fun(**{'a':1}) -> {'a':1} 关键字必须是字符类型,不然报错。
(五).强制关键字参数
Python3.6添加的新功能,强制使用关键字参数进行传递。在调用时显示地去手写一下参数名称,从而避免了因为错误传参而引起逻辑错误或二义性,比使用位置参数表意更加清晰。

必须要显示地手写函数的形参名称!
(六).4种参数混合传参
关键字参数放最后;根据定义的顺序,确保必备参数有且只能拿到一个值;
混合传参时,记住一点:一定要按定义的顺序传参。定义函数时参数顺序怎么写的,调用时也按顺序写。不要出现重复变量名,会发生二义性,导致报错。
def four_params(b, m=20, *args, **kwargs): print("必备参数的值:", b) print("默认参数的值:", m) print("不定长参数的值:", args) print("关键字参数的值:", kwargs) return "OK" g = four_params("quanquan616", 20, *(1, 2, 3), **{"aa": "a", "bb": "b", "cc": "c"}) print(g)
二、return语句
return语句可以放在函数体中的任何地方。return的东西才能被变量接收。
return语句的作用:
(1).返回这个函数结果。
(2).函数结束的标志。远行了return 就强制结合俗了这个函数。
def fun0(): print("quanquan616") fun0() # 调用函数,是函数实际的执行结果 fun0 # 传的是函数体的内存地址
案例:
def other_func(): # 函数的定义,不调用是不会执行的 print("other_func") return 10 def my_func(): # 同理于上 print("my_func") return other_func() print(my_func()) # 第一个被执行 """ 运行结果: my_func other_func 10 """ """ 拆解步骤: 1. 解释器遇到my_func()这条代码,去执行my_func这个函数,先打印出 "my_func" 2. 调用函数 other_func,打印出 "other_func" 3. other_func函数遇到了return 10,结束函数,并把10这个值返回 4. 函数 my_func 接收到了10,并返回。实际就是print(10) """
三、lambda匿名函数
(一).匿名函数的格式
lambda 参数:表达式
(二).不用写def语句、不需使用return


g = lambda: 1 # 函数体赋值给了变量g print(g) # 返回内存地址。结果:<function <lambda> at 0x........> print(g()) # 调用,就像调用函数一样。结果:1 g = lambda x : x + 1 # x是参数,x + 1 相当于 return (x + 1) # 运行结果:2
四、pass关键字
关键字pass的作用:
(一).空语句:do nothing
(二).保证格式完整
(三).保证语义完整
五、解包
(1).例1:

(2).例2:函数返回多个值
def binary(): return 0, 1, 2, 3, 4 a, b, c, *d = binary() print(a, b, c) # 0 1 2 print(d) # [3, 4]
其实是自动打包成元组,然后再解包赋值给了4个变量。
(3).例3:
l = [ ("Bob", "1990-1-1", 10), ("Mary", "1996-10-11", 20), ("Sally", "1988-7-21", 31), ("Rita", "1993-6-16", 25), ] for name, *args in l: print(name, args) """ 运行结果: Bob ['1990-1-1', 10] Mary ['1996-10-11', 20] Sally ['1988-7-21', 31] Rita ['1993-6-16', 25] """
(4).例4:
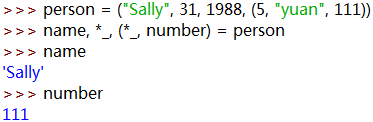
(5).例5:

报错大意:已加星标的分配目标必须位于列表或元组中
(6).字典的解包

小练习:
(1).找到1-100内的质数,结束之后打印“搜索结束”.
(质数:只能被1和自己整除,如2,只有除以1和2才能整除)
""" 思路: 先判断一个数是不是质数 , n = 7,那么就是 1 2 3 4 5 6 7 都要逐个除一下,除了1和自身,能整除就不是质数。 7的时候,只需要 2 3 4 5 6 都除一下,都不能整除,那么7就是质数。 """ li = [] """ range(2,2) 2取不到,返回的是一个空列表。 当list中的元素被取完了,迭代完了,就是空列表了。这里相当于正常结束循环了。所以执行else了 """ for i in range(2, 101): for j in range(2, i): # 不能i+1,不然自己能整除自己,就被下面break了 if i % j == 0: break else: li.append(i) else: print("搜索结束") print(li) """ 运行结果: 搜索结束 [2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97] """
(2).定义一个函数,能够输入字典和元组。将字典的值(value) 和 元组的值交换,交换结束后,打印并且返回 字典和元组。
tu = (4, 5, 6) dic = {'a': 1, 'b': 2, 'c': 3} # *args把接收到的参数,包装成元素 # **kwargs把接收到的参数,包装成字典 def dic_tu(dic, tu): i = 0 li = list(tu) for key in dic.keys(): # 取出所有keys,遍历所有keys # temp = dic[key] # 先取出值,不然下面赋值后,再从字典取值就一样的值了 # dic[key] = li[i] # li[i] = temp # i += 1 dic[key], li[i] = li[i], dic[key] # 同理 a,b = b,a i += 1 """ 如果tu里面元素多了,也不受影响。只会交换前面三个,后面不会变。 因为字典中的key遍历完了,就结束了。 字典长于tu就有问题了,当第三次遍历后,i的值超出tu的长度了,会有IndexError """ print(tuple(li)) print(dic) dic_tu(dic, tu)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号