
xpath使用
Xpath和LXML类库
lxml:一款高性能的Python HTML/XML解析器,利用xpath来快速定位特定元素以及获取节点信息。
xpath:(XML Path Language)一门在HTML/XML文档中查找信息的语言,可用来在HTML/XML文档中对元素和属性进行遍历。
XPath使用路径表达式来选取XML文档中的节点或节点集。这些路径表达式跟Linux中的路径表达式很相似。
Xpath的W3School官方文档:https://www.w3school.com.cn/xpath/index.asp
XML和HTML的区别

Xpath常用工具:
Chrome插件:XPath Helper(自备梯子)
开源的Xpath表达式编辑工具:XMLQuire(XML格式文件可用)
FireFox插件:XPath Checker
安装Chrome的Xpath插件(自备梯子)
工具的使用
(在Chrome使用这个Xpath Helper插件,被选中的标签会添加一个class属性:class="xh-highlight")

Xpath常用的路径表达式

节点选择语法,查找某个特定的节点或包含某个指定的值的节点
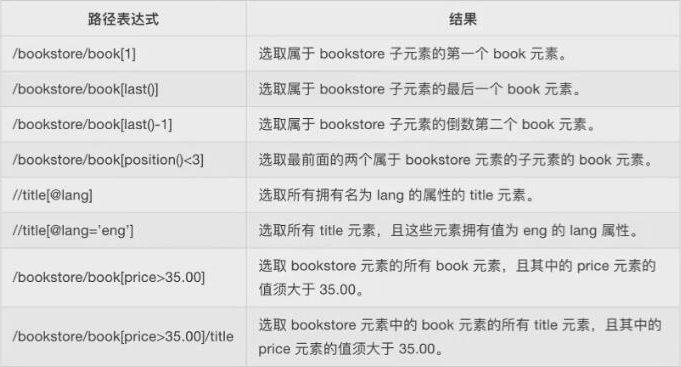
选择未知节点
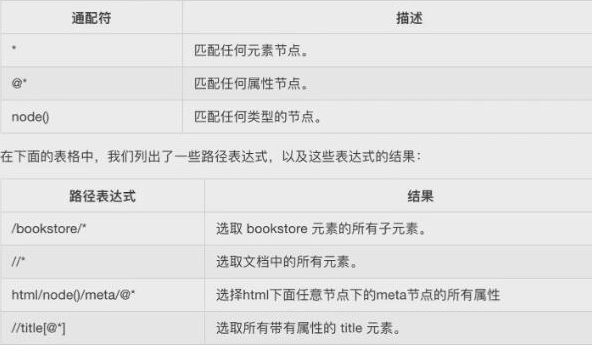
选择若干路径

Xxpath获取文本
"a/text()" 获取a标签下的文本
"a//text()" 获取a标签下所有标签的文本
"//a[text()='下一页']" 根据指定文本来定位该元素
@符号
"a/@href" 获取a标签下href这个属性的值
"//ul[@id='detail-list']" 获取所有id为detail-list的ul标签
"//"
1.在xpath开始的时候,表示从当前html中任意位置开始选择。(类似于绝对路径的理解)
2."li//a" 表示的是li下任何一个a标签。(类似于相对路径的理解)
使用Chrome自带的工具来生成xpath代码
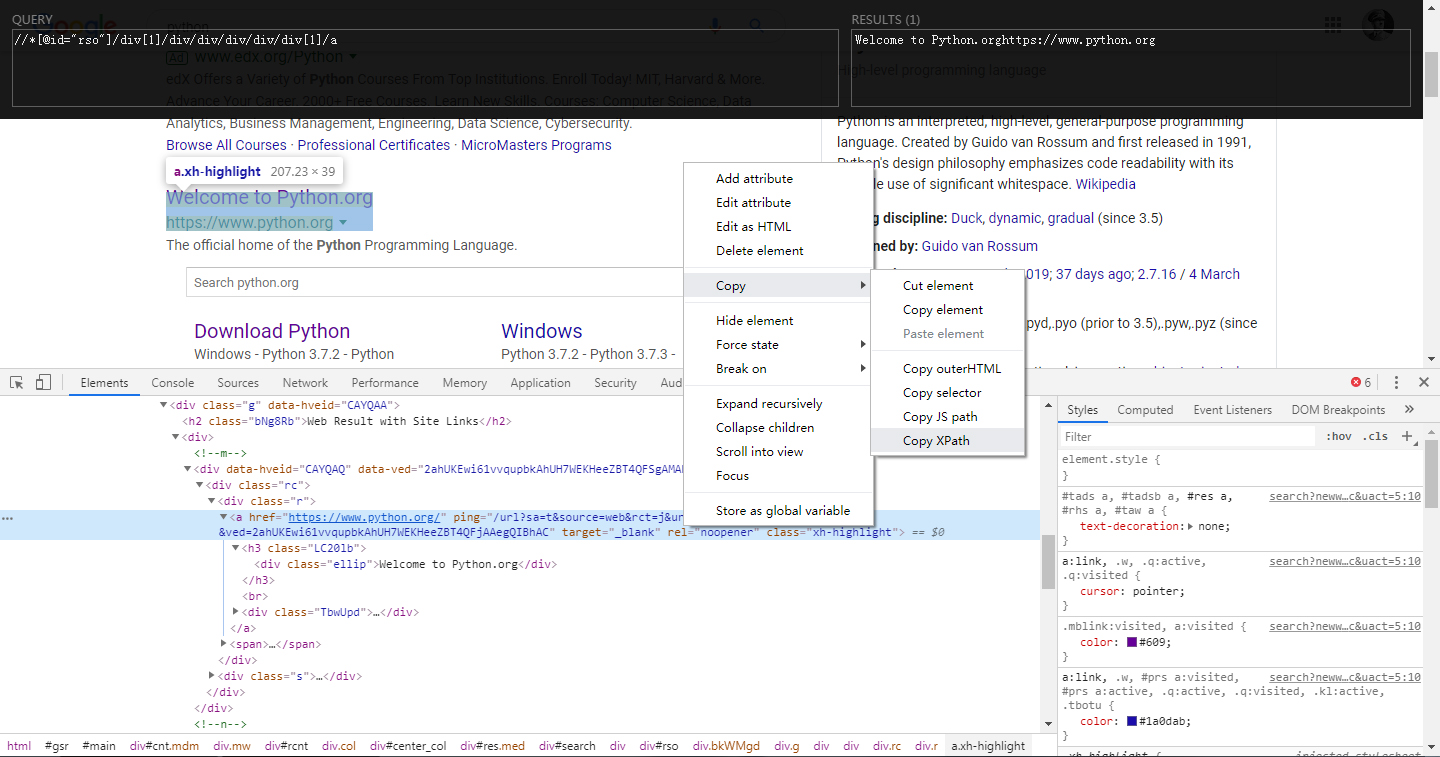
注意:使用xpath工具或是Chrome自带的工具,都是根据elements中提取的数据。但是爬虫获取的是url的响应,往往和elements不一样,不能直接把工具中的代码拿来用。只有当两者内容一样的时候,才能照着去用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号