DFAT—Dual Focus-Attention Transformer for Robust Point Cloud Registration
创新点
(1)提出新框架,采用双层焦点注意力特征交互机制提升性能
(2)提出双空间一致性匹配模块,充分利用几何一致性来提升supperPoint匹配的质量。
(3)引入线性注意力模块,用于优化点特征。
流程
首先使用局部特征提取对两个视角的点云进行Kpconv卷积提取特征,接着分为两部分,一部分是最粗糙的下采样,也就是进行到最下面的下采样,最粗超点经 Superpoint Focus-Attention 和双空间一致性过滤后得到粗对应,这些粗对应再引导裁出同名超点内部的密集点;上采样则是经 Point Focus-Attention 增强后做细匹配,生成多组密集对应;对点集合配对,然后进行处理,处理后和经过处理的下采样部分进行级联,最后进行评估,整体流程如下图所示
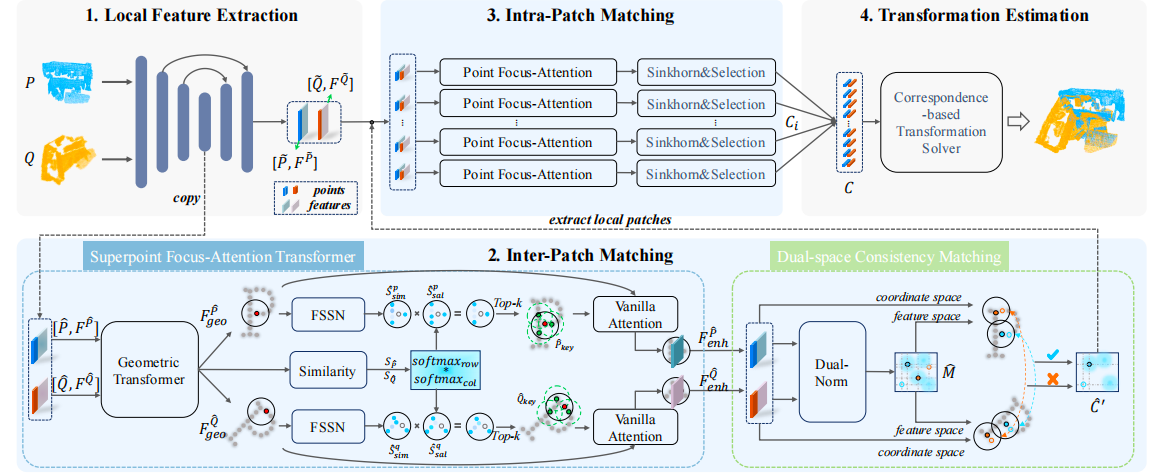
局部特征提取
局部特征提取采用的是基于Kpconv卷积FPN骨干网络,在之前已经学习过Kpconv,这里大致讲一下Kpconv卷积:
(1)给定中心点,设置一个半径画圆,在范围内设定固定的N个核点,这些点不是真正的点,而是虚拟的
(2)通过K近邻找出最近的设定的K个邻居点,作为邻点
(3)通过如下公式进行卷积核函数设定
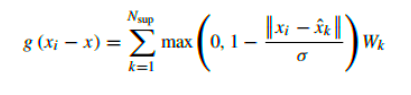
(4)对每个点进行加权求和获得最终的特征
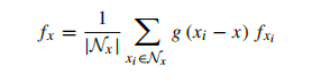
这里的编码器主要是进行下采样,我们输入原始点云P和Q,网络会经过多个下采样块,每个块通常包含:
(1)最远点采样:减少点的数量
(2)Kpconv:在采样的点上进行卷积,提升特征,扩大感受野
这里需要最远点采样而不是只做卷积操作的原因是点云并不似2D像素之间有规则,他是无序的,所以只做卷积很慢也不一定能覆盖全部,所以需要最远点采样最大程度覆盖整个空间。
最终到最后一层下采样的时候,输出点集P,Q,这时的点集被称为超点,他们是原始点的子集,数量很少,代表了原始点云的全局结构;输出的f_p和f_q是与超点对应的d维特征,他们包含了广阔的上下文信息。
接下来是解码器,解码器主要是进行上采样和特征融合。
网络会进行多个上采样块,通常包含:
(1)双线性上采样或三线性插值:用于增加点的数量
(2)跳跃连接:将编码器中相同分辨率的特征进行拼接,融合特征
(3)Kpconv层:在融合的点上进行卷积,进一步优化特征
最终输出P,Q,这是上采样后的密集点云,分辨率恢复为原始点云的一半;输出F_P和F_Q,对应点集的d维特征,包含局部细节和全局上下文信息。
补丁间匹配模块
现有的Transformer方法通过全连接的的密集交互让所有特征点相互沟通,这虽然能获取全局上下文,但不可避免地会引入大量错误和冗余的信息交互,反而“污染”了特征,降低了其判别力。首先来讲针对粗匹配的超点聚焦注意力机制
超点聚焦注意力机制
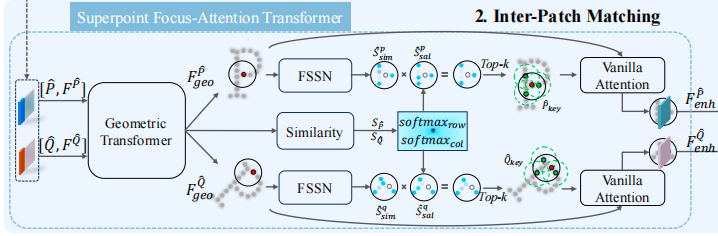
它不是与所有点自由交互,而是先筛选出一组稀疏的关键点,然后让超点与这些具有代表性的点进行深度交互,具体流程如下:
(1)GEO-Transformer
通过此操作获取初步的全局上下文信息,具体操作是进行几何自注意力和几何交叉注意力,前者在单个点云内部,编码变换不变的相对位置信息,后者则是在两个点云之间交换信息。最终输出f_geo_p和f_geo_q,这些特征包含了全局信息,此时是包含冗余信息的。
(2)聚焦注意力
此操作是将普通特征提炼为高判别力特征的关键,具体如下:
首先为每个超点筛选稀疏关键点,它的目的是找出特征上与超点最一致、自身显著性高的邻居作为交互对象(直接找会有不相关点带来的噪声),筛选指标有两个,一个是特征相似性(FSSN),它是通过计算超点与邻居的特征点积得到的,它可以衡量局部一致性,公式如下
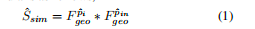
第二个指标是特征显著性,它的计算方式是计算所有点对之间的特征相似性矩阵S_P,然后分别对行和列做softmax,再相乘得到s_sal_all,这个操作能找出在整个特征空间中,哪些点对与其他店的关系都很独特,然后从中取出对应邻居范围的部分S_sal。
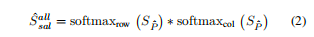
总和评分就是这两个指标相乘,得到每个邻居的综合重要性分数,分数较高,则代表该邻居既与中心超点特征相似,又是特征空间中的显著点。

然后我们为每个超点,选择邻居中分数最高的Top-k个点,作为稀疏关键点集合。
双空间一致性
之前的操作大多只使用双归一化进行超点对应关系的建立,由于部分重叠和可重复结构的存在,导致会产生错误匹配,本文则采用双空间一致性进行过滤,使得匹配更加精细。
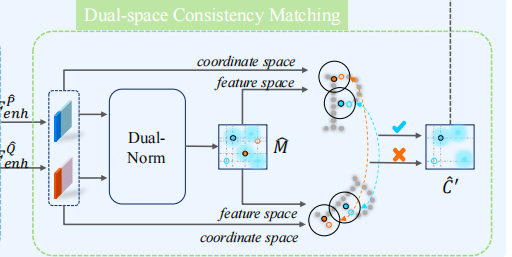
这里首先采用双归一化计算初始匹配得分

然后设置了一个阈值
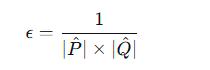
当匹配是完全随机的时候,任意一对点的期望匹配得分就是这个阈值的值,所以它可以过滤掉连随机匹配都不如的明显错误点对。
然后我们匹配分数矩阵M中选出前Km个最高分元素构建假设的超点的对应关系。
这个时候我们在几何空间中构建上述超点对应关系的最近虚拟超点对集合,然后在特征空间中对他们进行验证,对每个超点对(p,q),我们分别为p和q找到最近的超点p和q,并建立对应关系设为c,如果这个对应关系c的匹配分数大于阈值则保留,否则丢弃。保留的对应关系C最终被输入到局部块匹配模块进行精细匹配。
块内细匹配
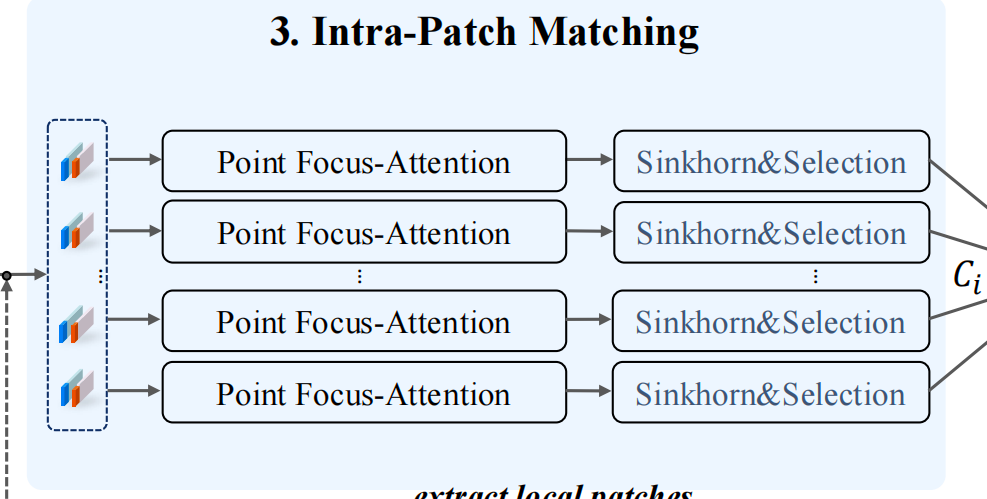
这里将上采样的和刚刚我们经过筛选的粗匹配点对作为输入,这里首先使用Point Focus-Attention,即通过超点对应附近的点间注意力操作来编码局部上下文信息,否则即使超点对应正确,点特征也可能因为缺乏局部上下文信息而生成错误对应,这里使用的注意力是线性注意力,避免过多的计算量
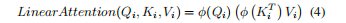
重复此模块L次,就存在了局部的上下文对应关系,其中的激活函数是ELU函数

接着使用sinkhorn算法优化相似度矩阵并输出分配矩阵 A,
这个算法是为了解决硬匹配的局限性而出现,比如存在一种情况,源点云的点A和点B和目标点云的点X相似度都较高,那么就会出现两个点对应这个点的情况,而sinkhorn则可以解决此问题。
这个算法的输入是相似度矩阵S,然后它有一个超参数τ,核矩阵=exp(S/τ),这个操作将相似度转换为正值。
接下来进入迭代操作,如下所示

最终输出分配矩阵A
然后我们从A中选出m个对应关系组成Ci,将多个局部的Ci进行拼接就得到了最终的密集点对。
变换估计
这里考虑到传统方法RANSAC在迭代过程中存在收敛慢或不稳定的情况,所以使用局部到全局的配准策略,具体如下
输入是密集匹配点集C和多个精细匹配子集Ci
我们对每个Ci,使用加权SVD计算一个变换候选Ti={Ri,ti}
最后从多个局部变换候选中选出最优变换

统一的公式如下

相关知识
Geo-Transfrom
注意力机制
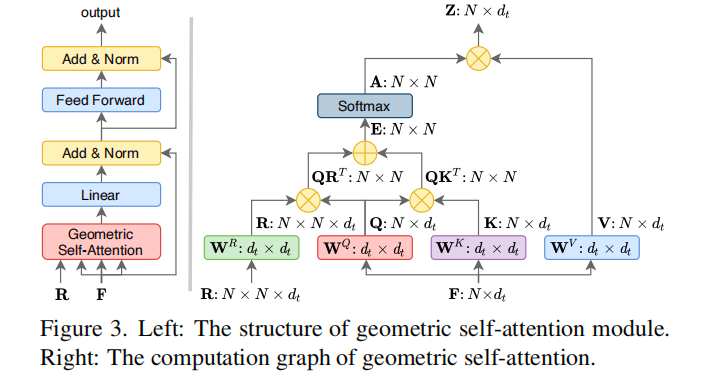
这里与普通注意力机制不同的是,多加入了几何关系矩阵R,R的维度是N * N *D_t,其中,N是点云的点数,D_t是几何特征的维度(包含距离、相对位置、法向量夹角)
总结的话对比如下

这里可以看出来就是多了一个r这部分,然后r由距离嵌入和角度嵌入
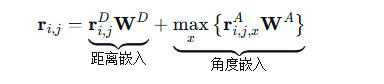
具体计算方法如下:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号