wav音频文件头动态解析--java语言
之前有处理过一些相对较为不常见的音频格式,也睬过很多坑,这里做一下简单记录。后面可能随着接触音频类型的增多做进一步更新,像之前有记录过包含LIST数据块的wav格式录音就是调试过程中发现遗漏点。
在此之前先整理一下常规音频文件头的基本结构,如下图:
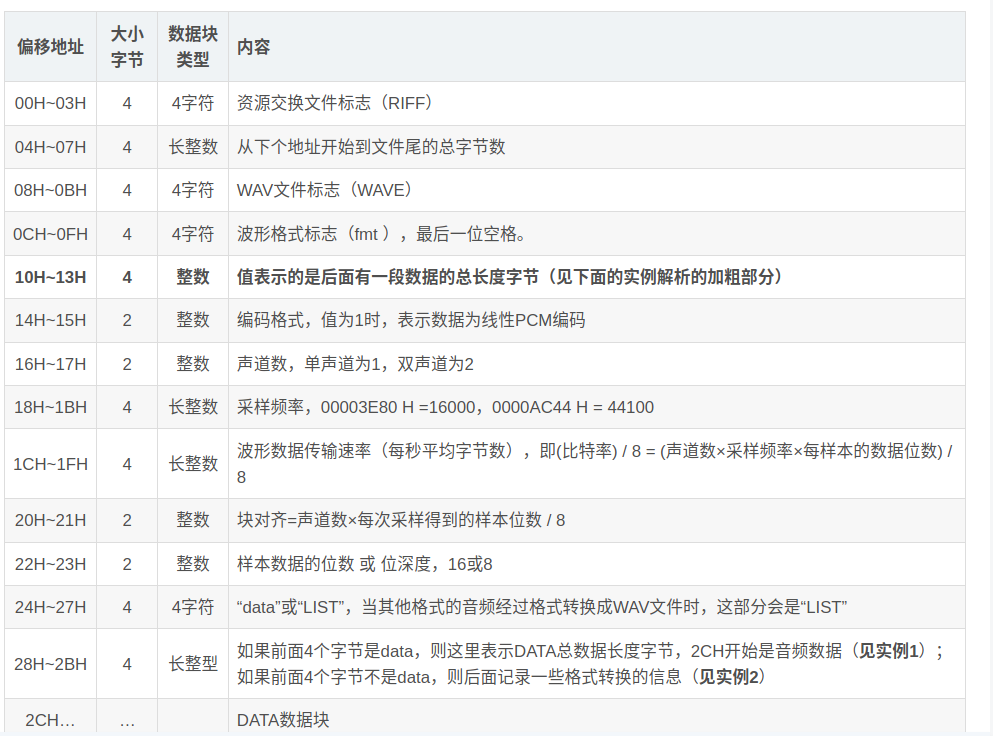
可以看到在文件头中,不同位置的字节代表不同的数据块。相对来说,大部分情况一些数据块的信息是关注度不高的,像LIST数据块,而另一些诸如音频长度,格式,位长,采样率等等是关注度较高的,所以在处理过程中可以把需要的数据块定义成一个通用的结构,在解析后设置该结构对应的结果返回。对于wav文件来说,以chunk为基本存储单位,一个wav文件包含3个必要chunk和一个可选chunk,在文件中排列循序是:RIFF chunk ,Format chunk ,Fact chunk(可选),Data chunk。
所以在从前往后读取文件头并解析时,riff chunk和fm chunk时固定的。chunk划分如下:

根据其不同数据块的次序和长度以及字节长度,可以定义一份固定的riff和fm chunk的结构如下:
{ "name" : "riff_id", "index" : 0, "type" : "chars", "len" : 4, "value" : "RIFF" }, { "name" : "file_size", "index" : 1, "type" : "int", "len" : 4, "value" : 0 }, { "name" : "riff_type", "index" : 2, "type" : "chars", "len" : 4, "value" : "WAVE" }, { "name" : "fmt_hdr_id", "index" : 3, "type" : "chars", "len" : 4, "value" : "fmt " },
一,每一个数据块由一个binaryElement描述,包括name,insex,type,len,value等属性。其中type跟每个数据块的value类型相对应,影响在数据读取后的转化过程。
不同数据类型的转化过程如下做局部示例:
`/**
* byte转int
*
* @param b 字节数组
* @return 解析出来的数字
*/
public static int toInt(byte[] b) {
return b[0] & 0xff | (b[1] & 0xff) << 8 | (b[2] & 0xff) << 16
| (b[3] & 0xff) << 24;
}
/**
* byte转long
*
* @param b 字节数组
* @return 解析出来的数字
*/
public static long toUnsignedInt(byte[] b) {
return b[0] & 0xff | (b[1] & 0xff) << 8 | (b[2] & 0xff) << 16
| (b[3] << 24);
}
/**
* byte转short
*
* @param b 字节数组
* @return 解析出来的数字
*/
public static short toShort(byte[] b) {
return (short) (((b[1] << 8) | b[0] & 0xff));
}`
二,整体的解析过程如下:
先解析固定区域,riff和fmchunk,共11个数据块:
` //记录当前读取位置
int readCur = 0;
byte[] tmp;
for (int i = 0; i < FixedStrutNum; i++) {
BinaryProtocolElement ele = headerStrut.get(i);
if (ele != null) {
tmp = new byte[ele.getLength()];
stream.read(tmp);
//转化未对应数据类型
bytesToElement(tmp, ele, encoding);
readCur += ele.getLength();
}
}`
然后处理fmt的扩展区,如果有的话。该部分可通过fmchunk的长度判断是否存在扩展区。即该chunk的总长度 - 固定的字段长度16,若不为0则说明存在扩展区,需要跳过解析。
`//处理fmt的扩展区 长度fmt_data_len - 16
//无须该区段扩展信息,跳过即可
int extLength = Integer.parseInt(
headerStrut.get(WaveHeaderEleDefine.FMT_HDR_LEN.getIndex()).getValue())
- PCM_FMT_LEN;
if (extLength != 0) {
//先获取扩展块数据的长度
BinaryProtocolElement dataLenExt = new BinaryProtocolElement();
dataLenExt.setDataType(ProtocolDataType.SHORT);
dataLenExt.setLength(2);
tmp = new byte[dataLenExt.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataLenExt, encoding);
readCur += extLength;
//扩展区长度为0或22
//如果为22需要手动跳过
int extDataLength;
if ((extDataLength = Integer.parseInt(dataLenExt.getValue())) != 0) {
readCur += extDataLength;
stream.skip(extDataLength);
}
}`
接着判断是否有可选chunk--fack,可以通过后续data_tag标签数据块来判断,若后续DATA_TAG为FACT,则需要获取该chunk长度并跳过解析。
`//根据data_tag判断是否有可选chunk fact
tmp = new byte[dataTag.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataTag, encoding);
readCur += dataTag.getLength();
//如果有fact域需要跳过该域重新解析tag
//如果没有读取data_len即可
if (TAG_CHUNK_FACT.equalsIgnoreCase(String.valueOf(dataTag.getValue()))) {
tmp = new byte[dataLen.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataLen, encoding);
readCur += dataLen.getLength();
//跳过fact chunk的data域
readCur += Integer.parseInt(dataLen.getValue());
stream.skip(Integer.parseInt(dataLen.getValue()));
//解析data域的tag
tmp = new byte[dataTag.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataTag, encoding);
readCur += dataTag.getLength();
}`
同理,需要校验后续chunk是否为LIST chunk,若是,也需跳过解析。
`//针对格式转换过后的wav文件
//存在LIST数据块保留一些格式转换的信息
//此处数据暂时没有业务需要,解析出LIST数据块长度后跳过
//LIST数据块结构包括 listSize listType listData
//listSize占有4字节,listSize的值是listType的大小(即4个字节)加上listData的长度。不包括“LIST”和listSize的长度。
if (TAG_CHUNK_LIST.equalsIgnoreCase(dataTag.getValue())) {
//先解析出list_size
BinaryProtocolElement listSize = new BinaryProtocolElement();
listSize.setDataType(ProtocolDataType.INT);
listSize.setLength(4);
tmp = new byte[listSize.getLength()];
stream.read(tmp);
bytesToElement(tmp, listSize, encoding);
readCur += extLength;
//然后跳过listType和listData
readCur += Integer.parseInt(listSize.getValue());
stream.skip(Integer.parseInt(listSize.getValue()));
//解析data域的tag
tmp = new byte[dataTag.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataTag, encoding);
readCur += dataTag.getLength();
}`
最后,解析data chunk,获取音频数据长度并返回文件头长度(若有需要)
`//没有获取到data标签
//检测音频头信息是否有误
//或者有错误移位
if (!TAG_CHUNK_DATA.equalsIgnoreCase(dataTag.getValue())) {
log.error("can not fetch the tag of data chunk, please check");
return 0;
}
//读取data域的data_len
tmp = new byte[dataLen.getLength()];
stream.read(tmp);
bytesToElement(tmp, dataLen, encoding);
readCur += dataLen.getLength();
//这里由于跳过对应扩展区,所以长度要调整一下
headerStrut.get(WaveHeaderEleDefine.FMT_HDR_LEN.getIndex())
.setValue(PCM_FMT_LEN + "");
//最后返回文件头长度
return readCur;`
参考资料:https://www.jianshu.com/p/02c4df08c51c
https://www.jianshu.com/p/02c4df08c51c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号