从DETR到DETR3D(2)
最近参加了手写ai的车道线检测项目, 后续会更新一些文章展现对相关项目邻域的总结和理解。
在自动驾驶的环视相机图像中做3D目标检测是一个棘手的问题,比如怎么去从单目相机2D的信息中预测3D的物体、物体形状大小随离相机远近而变化、怎么融合各个不同相机之间的信息、怎么去处理被相邻相机截断的物体等等。
将Perspective View转化为BEV表征是一个很好的解决方案,主要体现在以下几个方面:
- BEV是一个统一完整的全局场景的表示,物体的大小和朝向都能直接得到表达;
- BEV的形式更容易去做时序多帧融合和多传感器融合;
- BEV更有利于目标跟踪、轨迹预测等下游任务。
一 网络架构
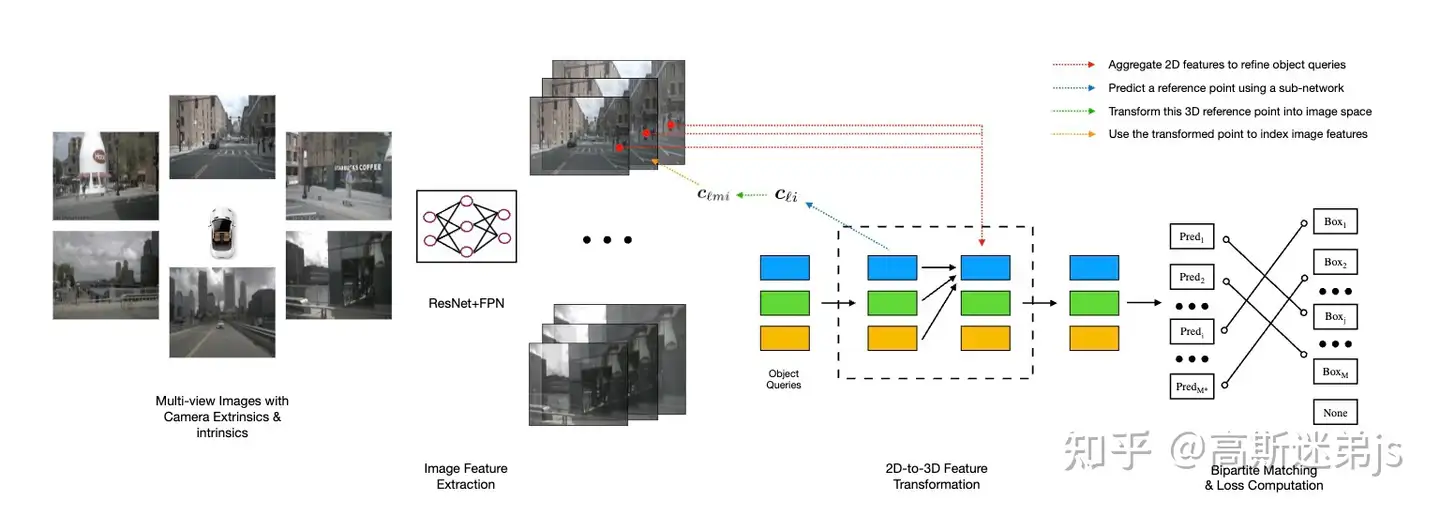
输入:设计好可学习query
关键点:提取参考点,采样图像特征
主体结构:围绕的是3d目标点映射到2d feat,更新query并调整ref point的位置
1.1 Decoder
decoder的输入是经过fpn的特征图,在特征层面实现2D到3D的转换,避免深度估计带来的误差。
Detection head共含有6层transformer decoder layer。类似于DETR,我们预先设置300/600/900个object query,每个query是256维的embedding。所有的object query由一个全连接网络预测出在BEV空间中的3D reference point坐标(x, y, z),坐标经过sigmoid函数归一化后表示在空间中的相对位置。
在每层layer之中,所有的object query之间做self-attention来相互交互获取全局信息并避免多个query收敛到同个物体。object query再和图像特征之间做cross-attention:将每个query对应的3D reference point通过相机的内参外参投影到图片坐标,利用线性插值来采样对应的multi-scale image features,如果投影坐标落在图片范围之外就补零,之后再用sampled image features去更新object queries。
经过attention更新后的object query通过两个MLP网络来分别预测对应物体的class和bounding box的参数。为了让网络更好的学习,我们每次都预测bounding box的中心坐标相对于reference points的offset(ΔX,ΔY,ΔZ) 来更新reference points的坐标。
每层更新的object queries和reference points作为下一层decoder layer的输入,再次进行计算更新,总共迭代6次。
1.2 generate ref point
根据预设值的query数目,预测一组bbox的3维中心点坐标3D reference point。在Decoder中有L层transformer结构中,每次迭代query进行计算,query通过mlp生成3维参考点来更新ref point;具体点是在每一层decode中以3D reference point为基准点投影回多视角的2D特征图像,采样2D特征,reference point所得到的2D特征fli,与上一层输入的query相加得到一个新的object query,通过多次迭代这个过程,queryt多次更新多次预测
1.3 视角转换
使用相机的内外参的物理属性,将中心点3D reference point投影到所有的特征图上。将reference point转为齐次坐标,用内外参转到2d feat上
1.4 特征采样
通过双线性插值从2D的特征图中采样,需要注意的是预测的3D reference point投影回2D中可能无对应的点或者在当前相机下不可见,不可见的需要补零,之后再用sampled image features去更新query
1.5 迭代更新
multi-head attention计算query之间的关系,让query与query之间特征交互,感受全局信息,每层更新的queries和reference points作为下一层decoder layer的输入,再次进行计算更新
二: 总结
在DETR3D里,我们并没有完整显式地表示出了整个BEV,而且由sparse的object query来进行表示。最显著的好处就是节省了内存和计算量。而在BEVDet和BEVFormer里,他们生成了一个dense的BEV feature,虽然增加了显存,不过一来更容易去做BEV space下的data augmentation,二来像BEVDet一样可以另外增加对BEV features 的encoding,三来可以适应于各种3D detection head(BEVDet用了centerpoint,BEVFormer用了deformable detr)。
DETR3D方法也存在不少缺点:
- 严重依赖内外参
- 单个参考点特征采样,模型全局特征不够,局部信息其实也不够,只能检测一些比较规则的目标,对大目标检测效果不理想
- 不好魔改为车道线任务
DETR3D是稀疏的,不好魔改成车道线检测项目,只是每个query学一个offset,但是对后续bev方法的发展还是有很多借鉴意义的,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号