
论文略读:阿里智能算力引擎DCAF(DLP-KDD 20)
DCAF: A Dynamic Computation Allocation Framework for Online Serving System
论文地址:https://arxiv.org/pdf/2006.09684.pdf
来源:DLP-KDD 2020 阿里巴巴论文
摘要
现代大规模在线广告推荐系统的目标是有限资源的情况下最大化其收益(比如GMV)。通常的解决办法是用多阶段级联架构来解决,比如增加召回,粗排,精排阶段来解决。每一阶段的数目根据计算力来人为分配。这种方案很容易陷入计算力的局部最优点的情况,另外从请求的纬度来讲,每个请求的价值其实是不一样的,但是都用了同样的计算力,其实是可以优化的。
本文的方法会对不同的请求,根据其价值个性化的给予算力。我们将其问题抽象成为了背包问题,并将这个架构称为DCAF。DCAF能在给定计算资源的情况下,获得最大收益。目前已经在淘宝广告上线了,在同等效果情况下,机器资源节省了20%。
引言
淘宝网的流量很大,以及在特定时候会有尖峰(例如双十一),那么过去的解决办法:
(1) 推荐架构采用多阶段级联架构,根据经验去调整每一层的数目。
(2) 设计多层的降级手段,在突发情况的时候,手动开启降级。
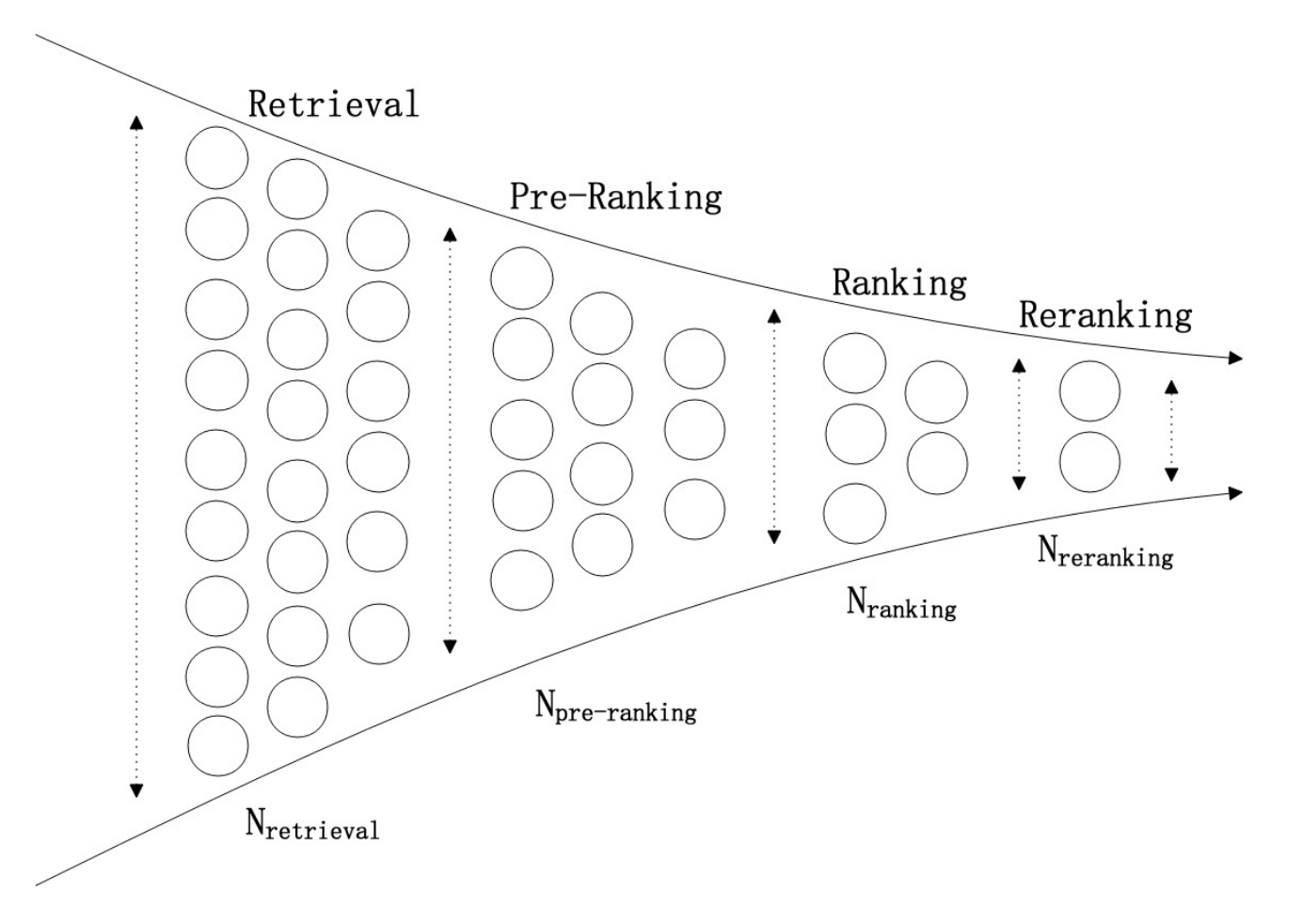
这些解决办法存在一些问题:
(1) 缺乏灵活性,往往需要人工手动干预
(2) 降级策略一视同仁,价值高的请求和价值低的请求,会被用以同样的计算力。
那么里面显然能看到一个简单且有效的方案:为了使得总收益最大,我们可以降级低价值请求,将资源倾斜给高价值请求。
根据以上的问题,DCAF最主要的贡献是:
(1) “个性化”的给予每个请求不同的算力。
(2) 追求总价值最大;且能够在请求量突发的情况下,保持稳定。
(3) 能够带来机器资源的节省。同样的效果下,淘宝广告降低了20%的GPU消耗。
(4) DCAF提高了推荐系统稳定性的天花板(吐槽。。。)
FORMULATION
将该问题抽象成为背包问题。
假设现在有N个请求{i=1....N},请求都需要在 T 时间内预估完成。每个请求我们能选择M个行为{j=1,...,M}。(可以理解为,每个行为就是针对每个请求采用的不同算力)
qj定义为进行第j个行为的花费。(由广告系统的engine来统计)
Qij定义为第i个请求进行第j个行为的收益。(与qij成正比例,广告系统为eCPM)
C表示总的计算资源。
xij表示我们对于第i个请求采用第j个行为,显然我们对于每一个请求,只能选择其中一个行为。
每次广告预估下,对于每个请求,我们只能选择其中一个行为,那么整体的问题公式就可以抽象为:
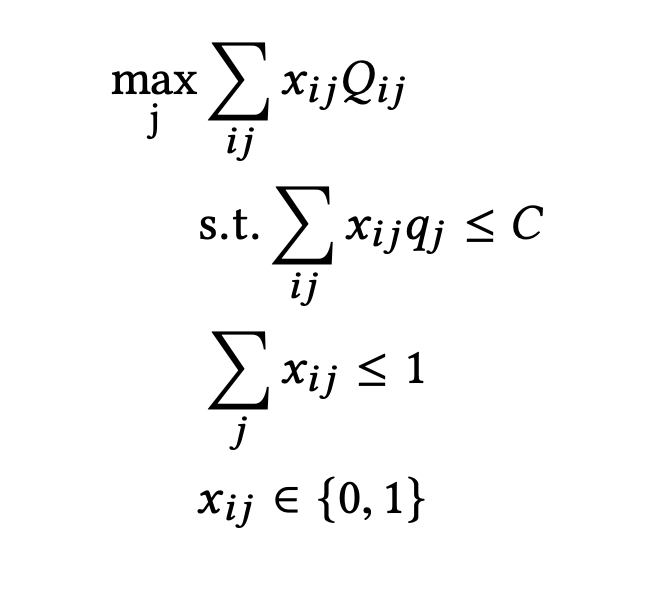
这个公式也会存在一些其他问题:
(1) 请求量在实时变化,所以该背包问题也需要实时计算。
(2) Qij是未知的,所以需要实时且有效的计算;另外还得足够轻的计算。
METHODOLOGY
推导
如何求解这个问题,我们先将背包问题用拉格朗日松弛:
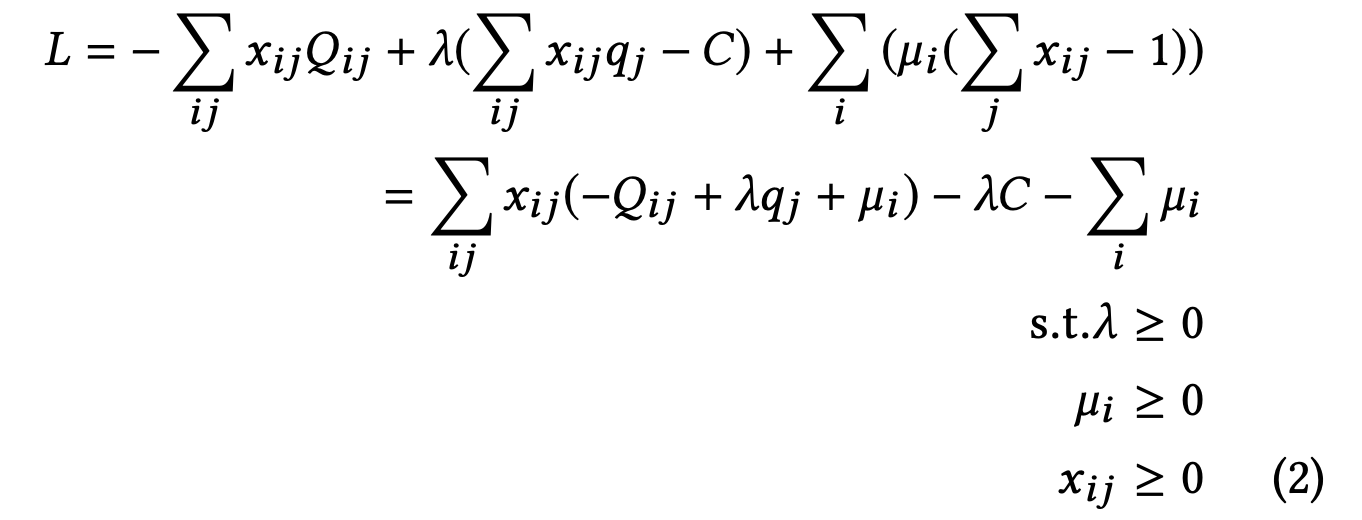
其对偶函数为:
分析该函数,因为xij >= 0,所以对于xij是一个向下的线性函数,故只会在
的时候xij会取1。
那么函数也可以转化为:
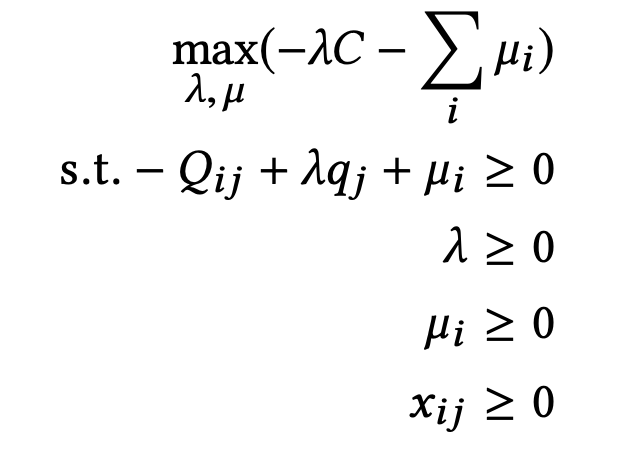
因为µ与其对偶目标是负相关,那么对于µ而言的全局最优解为:
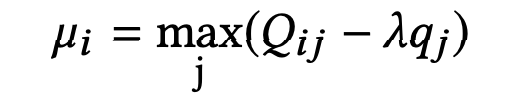
因此对于xij的全局最优解为:
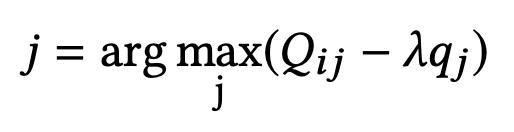
求解
为了求解拉格朗日乘子,提出一些假设:
(1) Qij是随着j增大而增大的。
(2) Qij/qj是随着j增大而减小的。
那么根据其假设,我们可以得到结论:
(1) 对于每个i,如果Qij1/qj1 > Qij2/qj2,那么λ1 ≥ λ2
(2) max(sigma(xijQij))和sigma(xijqj)都会随着λ增大而减小。
最后我们可以得到用二分法来计算λ,从而得到每个i的最优action j
得到其二分法的计算方案:

另外:Qij的预估,我们会用4类特征进行预估:用户画像,用户行为,上下文特征,系统状态。
架构
分为两部分,在线决策部分,离线预估部分。
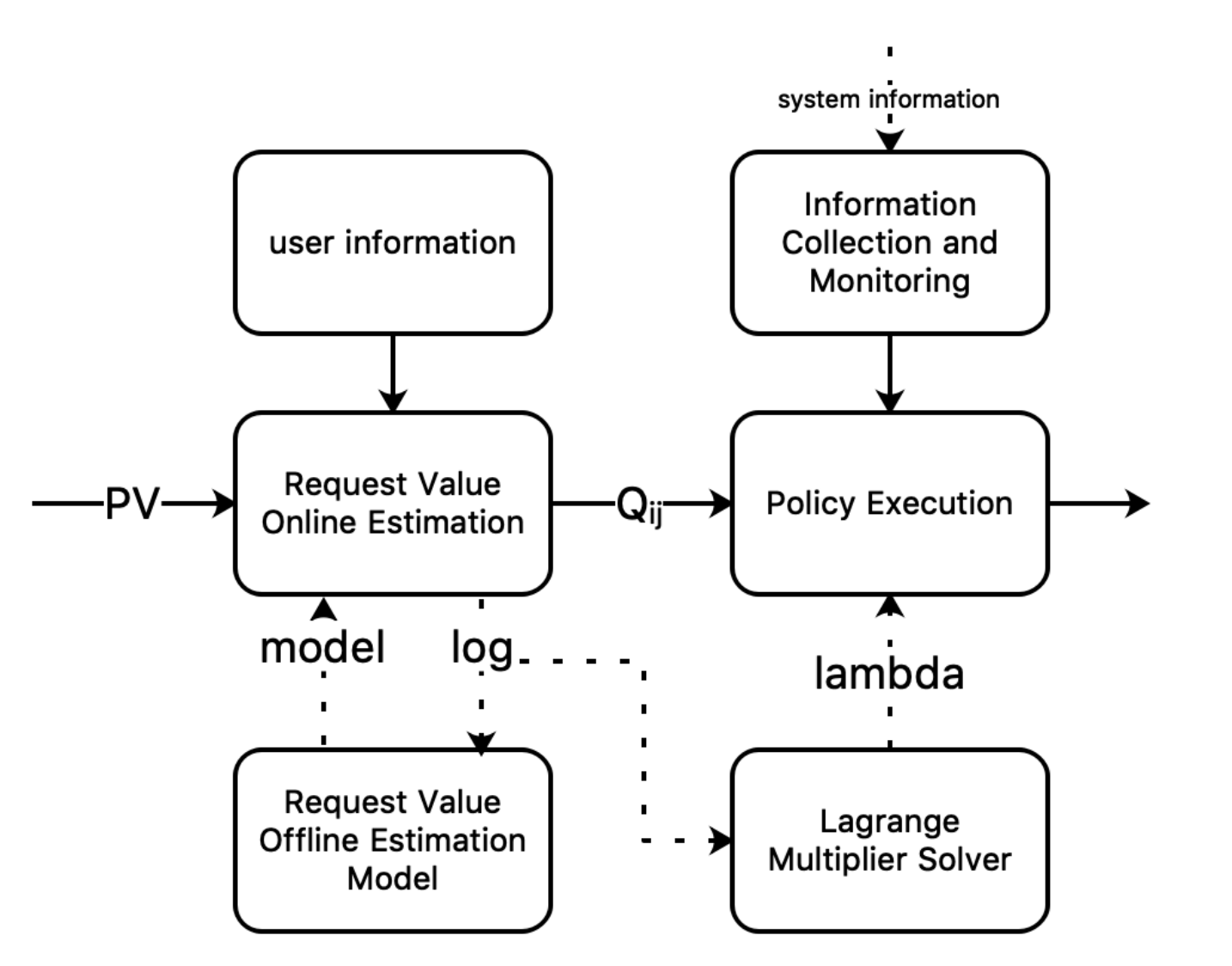
在线部分
每个模块的介绍:
Information Collection and Monitoring:收集系统状态,包含CPU,GPU,运行时间,错误率等。
Request Value Estimation:用以模型计算Qij,该阶段的模型要求轻量级,用了部分其他模型的上下文特征。
Policy Execution:通过类似PID系统,来给予每个请求i的最优行为j。具体操作如下:

离线部分
Lagrange Multiplier Solver:用以计算全局λ,流程:
(1) 每次离线log获取N个请求,每个请求都带有Qij,qj以及C。
(2) 用当前的系统情况来调整C
(3) 通过二分搜索来得到λ
Expected Gain Estimator:计算收益Qij,广告领域为ctr*bid(广告主出价) = eCPM,所以需要训练一个CTR模型,来得到Qij。这里定期更新,然后提供给Policy Execution来使用。
实验
离线实验
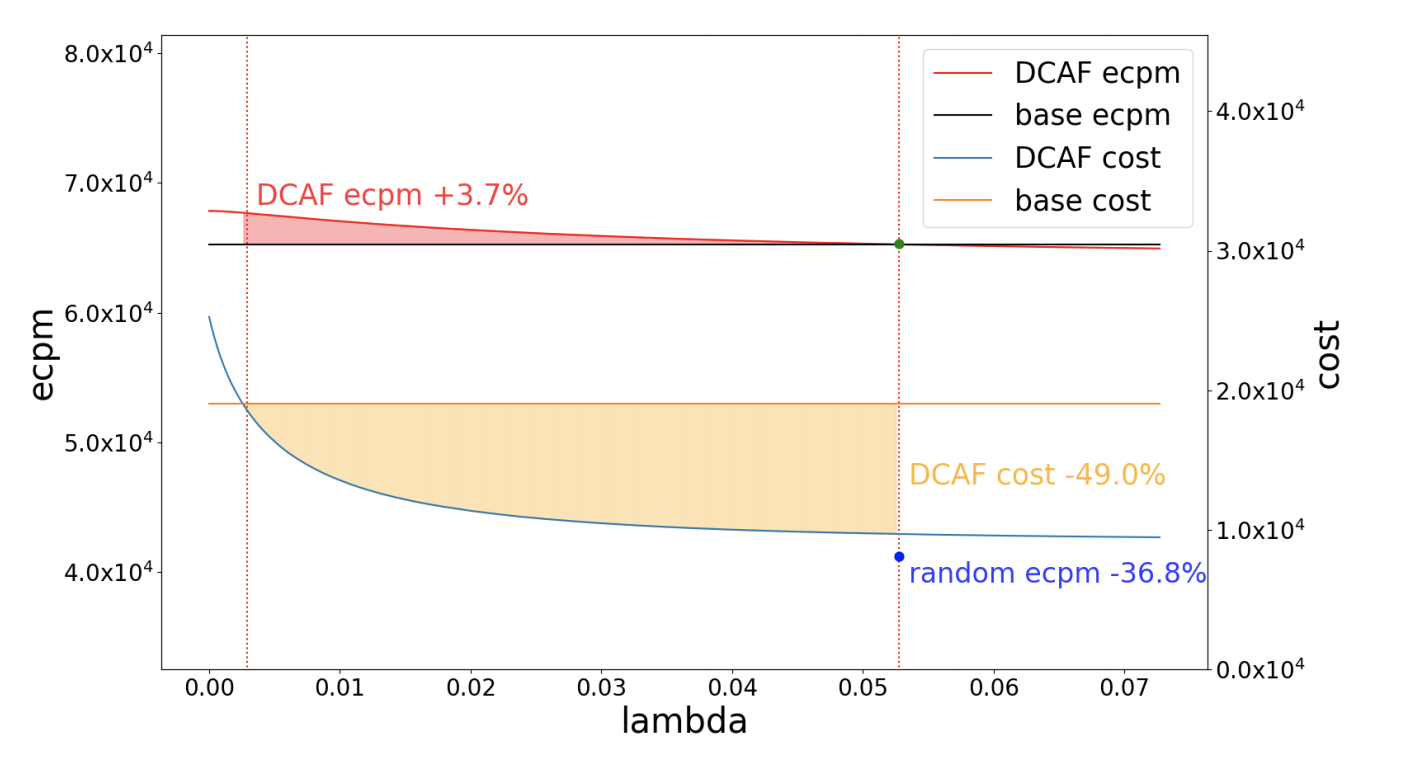
同消耗情况下,DCAF的ecpm + 3.7%
同效果情况下,DCAF的资源节省49%
在用随机策略的情况下,同机器的情况下,ecpm会下降36.8%。
在线实验
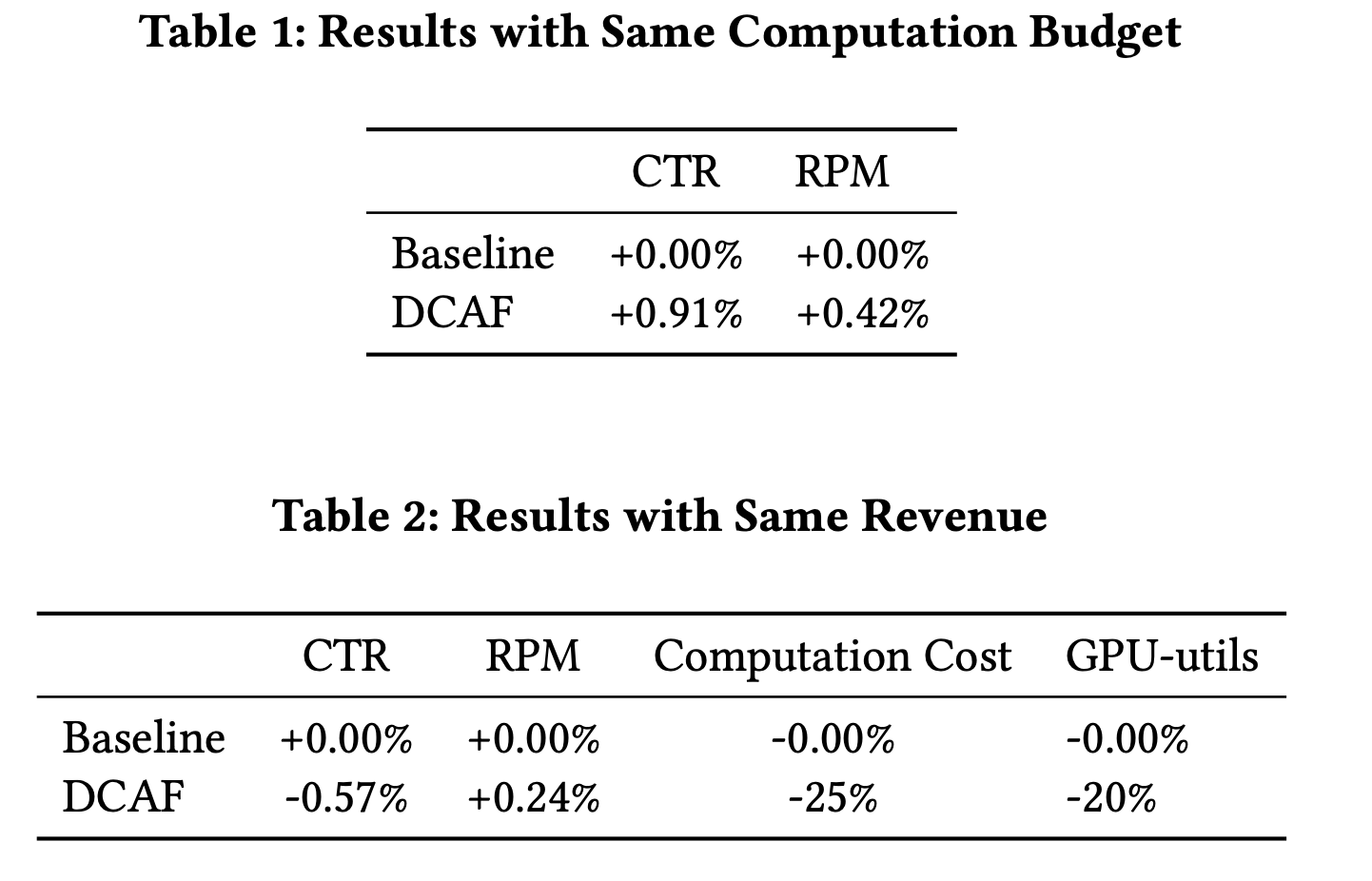
todo
(1) 因为引入了user profile,所以不可避免的会影响到部分用户的体验,如何优化“Fairness”
(2) DCAF仅考虑了推荐流程的单一阶段,未考虑全流程,未来需要实现全链路最优。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号