

python提取图片中文字
一.安装tesseract-ocr
1.1tesseract-ocr下载
下载地址:Index of /tesseract (uni-mannheim.de) 或者 https://github.com/UB-Mannheim/tesseract/wiki
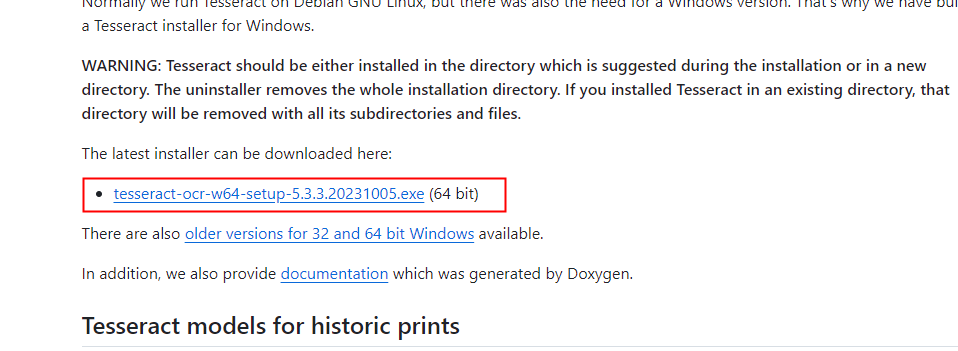
或
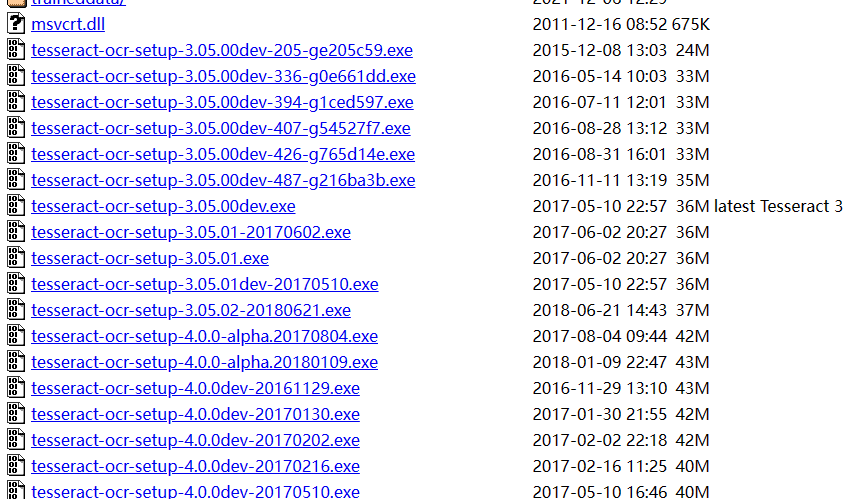
1.2完成tesseract-ocr安装,记住安装路径用于配置环境变量
1.3配置环境变量
将tesseract-ocr的安装路径添加到环境变量的系统变量(PATH)

增加一个TESSDATA_PREFIX变量名,变量值还是安装路径C:\Program Files\Tesseract-OCR\tessdata这是将语言字库文件夹添加到变量中;

1.4配置文件修改
在pytesseract库下的pytesseract.py文件中找到tesseract_cmd = 'tesseract',修改成 tesseract_cmd =r'C:\Program Files\Tesseract-OCR\tesseract.exe'保存

1.5识别效果优化
Tesseract OCR 对于不同的图像可能会有不同的识别效果,尤其是对于那些包含复杂背景、字体大小、颜色和形状等元素的图像。可以对图像进行一些预处理(如裁剪、缩放、旋转、二值化等)以提高识别准确率。同时,也可以设置不同的语言和配置选项来优化识别过程。
二.使用PIL+pytesseract进行提取
pytesseract.image_to_string 函数使用 Tesseract OCR(光学字符识别)引擎从图像中提取文本,可以将图像中的文字识别并转化为字符串形式。使用需要安装pytesseract和Tesseract OCR
import pytesseract
from PIL import Image
#读取图片
image = Image.open("D:/autotest/13.jpg")
# 使用 pytesseract 提取文字
text = pytesseract.image_to_string(image)
# 打印提取的文字
print(text)
三.使用cv2+pytesseract进行提取
使用需要安装pytesseract,Tesseract OCR和cv2
import cv2
import pytesseract
#打开图片
pic1=cv2.imread("D:/autotest/13.jpg",cv2.IMREAD_GRAYSCALE)
#缩放图片(裁剪、缩放、旋转、二值化等操作可以提高识别率)
pic2=cv2.resize(pic1, (2000, 2000))
#提取文字
pic3 = pytesseract.image_to_string(pic2)
#打印提取的文字
print(pic3)
四.使用EasyOCR进行文字识别
使用前需要进行安装 pip install easyocr,如果未安装检测模型,则需要先安装检测模型。
import easycor #创建Easyocr对象
reader=easyocr.Reader(['en'])
#读取图片并提取文字
text=reader.readtext("D:/autotest/13.jpg")
print(text)
五.pytesseract识别中文
pytesseract默认是不支持中文识别的,如果想要识别中文,需要下载相应的中文语言包。目前Tesseract-OCR官方并没有提供中文语言包,但是可以通过第三方渠道下载中文语言包,如chi_sim.traineddata。下载完成后,将chi_sim.traineddata放到Tesseract-OCR安装目录下的tessdata目录中。需要注意的是,由于Tesseract-OCR的版本不同,下载的中文语言包可能存在不兼容的情况,因此建议到官方论坛或社区查询最新、最合适的中文语言包。
5.1中文字库下载
下载地址:https://github.com/tesseract-ocr/tessdata;下载后的中文简体字库chi_sim.traineddata和 chi_sim_vert.traineddata放到安装包的tessdata文件夹下。
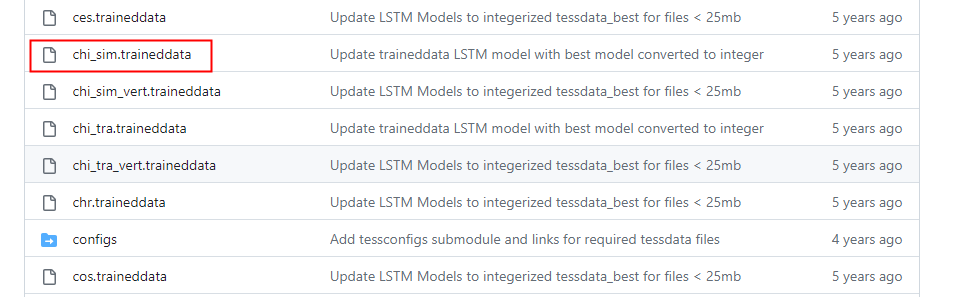
六.识别率优化
在白色背景色中识别黑色字体或者在黑色背景色中识别白色字体的识别率会高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号