

python读取excel内容
用例:
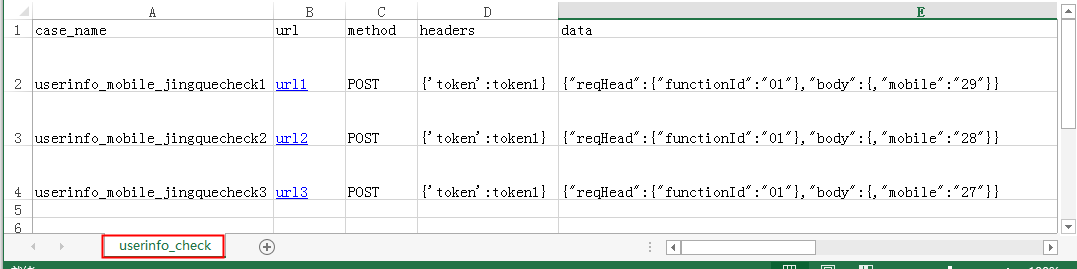
读取excel中的所有用例:
ex1=openpyxl.load_workbook('E:/pythonwork/APItest/testcase/testcase.xlsx')
#打开指定路径的名称为testcase的excel文档
wc2=ex1.sheetnames
#获取文档中所有sheet的名称
for sheet in wc2:
print(sheet.title)
#便利sheet名称
sh1=ex1.get_sheet_by_name('userinfo_check')
#通过sheet的名userinfo_check,选择对应的表,可能会报警告错误可忽略
rowmax=sh1.max_row
#获取sheet中有数据的最大行数
colsmax=sh1.max_column
#获取sheet中有数据的最大列数
header=[]
#新建一个列表用于存放列名
for i in range(1, colsmax + 1):
cellvalue = sh1.cell(row=1, column=i).value
header.append(cellvalue)
#获取列名,保存到header列表
j=2
data_list=[]
while j<=rowmax:
rowdata = []
for i in range(1, colsmax + 1):
cellvalue = sh1.cell(row=j, column=i).value
#循环获取每个单元格的内容
cellvalue=cellvalue.replace('\n','',1)
#最后一列的数据会包含一个\n字符,通过replace方法进行删除
rowdata.append(cellvalue)
#将循环获取的单元格内容添加到列表rowdata 中
j=j+1
d = dict(zip(header,rowdata))
#将列名header列表和rowdata组合,每行数据生成一个字典
data_list.append(d)
#将每行数据的字典添加到data_list列表中
print(data_list)
打印效果:

获取具体那一条用例:
case_name='userinfo_mobile_jingquecheck1'
#指定查询的条件
for case_data in data_list:
if case_name == case_data['case_name']:
print(case_data)
# 字典中存在指定case_name时执行,使用字典格式返回指定要求的用例
打印效果:

获取具体的用例内容:
url=case1['url']
method=case1['method']
headers=case1['headers']
data=case1['data']
expect_res=case1['expect_res']
#根据键获取字典中对应键的值
print(url)
print(method)
print(headers)
print(data)
print(expect_res)
打印效果:
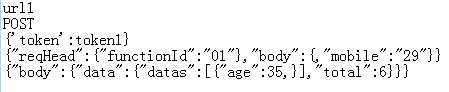
函数化的代码:
import openpyxl
ex1=openpyxl.load_workbook('C:/测试记录/接口测试config.xlsx') #打开excel
sheet_list=ex1.sheetnames #获取表内所有sheet名称
neirongall_list=[]
for sheetname in sheet_list: #循环遍历sheet名
neirong_list1 = [] #每个sheet一个列表
ws1=ex1[sheetname] #打开对应名称的sheet
hangmax =ws1.max_row #最大行数
liemax = ws1.max_column #最大列数
i = 2
while i <= hangmax:
neirong_list2 = [] #每行一个列表
j = 1
while j <= liemax:
neirong= ws1.cell(i, j).value #获取i行,j列的值
neirong_list2.append(neirong) #将获取的值添加到列表中
j = j + 1
neirong_list1.append(neirong_list2) #每行的列表添加到每个sheet列表中
i = i + 1
neirongall_list.append(neirong_list1) #每个sheet的列表添加到文档的列表中
print(neirongall_list)
import openpyxl
def get_all_case(filepath,sheetname):
ex1=openpyxl.load_workbook(filepath)
sh1=ex1.get_sheet_by_name(sheetname)
rowmax=sh1.max_row #最大行数
colsmax=sh1.max_column #最大列数
print(rowmax,' ',colsmax)
print(sh1.cell(1,1).value)
header=[]
for i in range(1, colsmax + 1):
cellvalue = sh1.cell(row=1, column=i).value
header.append(cellvalue)
# print(header)
j=2
data_list=[]
while j<=rowmax:
rowdata = []
for i in range(1, colsmax + 1):
cellvalue = sh1.cell(row=j, column=i).value
cellvalue=cellvalue.replace('\n','',1)
rowdata.append(cellvalue)
j=j+1
d = dict(zip(header,rowdata))
data_list.append(d)
return data_list
def get_test_case(data_list, case_name):
for case_data in data_list:
if case_name == case_data['case_name']: # 如果字典数据中case_name与参数一致
return case_data
def cases(filepath,sheetname,casename):
data_list=get_all_case(filepath, sheetname)
case1=get_test_case(data_list, casename)
if case1 == None:
text1='用例不存在'
elif case1 != None:
text1=case1
return text1
case_dict=cases('E:/pythonwork/APItest/testcase/testcase.xlsx','userinfo_check','userinfo_mobile_jingquecheck1')
print(type(case_dict))
print(case_dict)
print(case_dict['url'])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号