


一.索引概述
- 索引:是为了加速对表中数据行的检索而创建的一种分散存储结构。它是针对一个表而建立的,每个索引页面中的行都含有逻辑指针,指向数据表中的物理位置,以便加速检索物理数据。因此,对表中的列是否创建索引,将对查询速度有很大的影响。一个表的存储是由两部分组成的,一部分用来存放表的数据页,另一部分存放索引页。从中找到所需数据的指针,然后直接通过该指针从数据页面中读取数据,从而提高查询速度。
二.索引的优点
- 索引有以下优点:
创建唯一性索引,保证数据库表中每一行数据的唯一性。
大大加快数据的检索速度,这也是创建索引的最主要原因。
加速表与表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
在使用分组和排序子句进行数据检索时,同样可以减少查询中分组和排序的时间。
通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能。
三.索引的缺点
- 索引有以下缺点:
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚集索引,那么需要的空间就会更大。
当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,降低了数据的维护速度。
四.聚集索引的实现原理
- 聚集索引根据数据行的键值在表或视图中排序和存储这些数据行。索引定义中包含聚集索引列。每个表只能有一个聚集索引,因为数据行本身只能按一个顺序排序。
- 只有当表包含聚集索引时,表中的数据行才按排列顺序存储。如果表具有聚集索引,则该表称为聚集表。如果表没有聚集索引,则其数据行存储在一个称为堆的无序结构中。
- 除了个别表之外,每个表都应该有聚集索引。聚集索引除了可以提高查询性能之外,还可以按需重新生成或重新组织来控制表碎片。
聚集索引按下列方式实现: - PRIMARY KEY 和 UNIQUE 约束
(1)在创建 PRIMARY KEY 约束时,如果不存在该表的聚集索引且未指定唯一非聚集索引,则将自动对一列或多列创建唯一聚集索引。主键列不允许空值。
(2) 在创建 UNIQUE 约束时,默认情况下将创建唯一非聚集索引,以便强制 UNIQUE 约束。如果不存在该表的聚集索引,则可以指定唯一聚集索引。 - 独立于约束的索引
(1)指定非聚集主键约束后,您可以对非主键列的列创建聚集索引。 - 索引视图
(1)若要创建索引视图,请对一个或多个视图列定义唯一聚集索引。视图将具体化,并且结果集存储在该索引的页级别中,其存储方式与表数据存储在聚集索引中的方式相同。
五.非聚集索引的实现原理
- 非聚集索引具有独立于数据行的结构。非聚集索引包含非聚集索引键值,并且每个键值项都有指向包含该键值的数据行的指针。
- 从非聚集索引中的索引行指向数据行的指针称为行定位器。行定位器的结构取决于数据页是存储在堆中还是聚集表中。对于堆,行定位器是指向行的指针。对于聚集表,行定位器是聚集索引键。
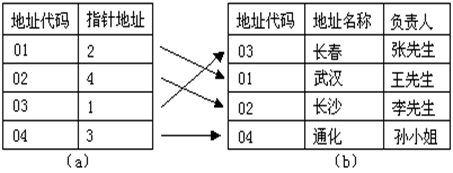
- 下面对非聚集索引的结构进行详细地说明。表a中的数据是按表b中的数据进行顺序存储的,在表a中为“地址代码”列建立索引,“指针地址”列是每条记录在表中的存储位置(通常称为指针),当查询地址代码为01的信息时,先在索引表中查找地址代码01,然后根据索引表中的指针地址(在这里指针地址为2)找到第2条记录,这样就很大地提高了查询速度。
六.创建索引
使用企业管理器创建索引,操作步骤如下:
- 启动SQL SERVER MANAGEMENT STUDIO,并连接到SQL SERVER 2012数据库.。
- 选择指定的数据库“DB_2012”,然后展开要创建索引的表,在表的下级菜单中,鼠标右键单击“索引”,在弹出的快捷菜单中选择“新建索引”命令,如图7.2所示。弹出“新建索引”窗体。
- 在“新建索引”窗体中单击“添加”按钮,弹出“从表中选择列”窗体,在该窗体中选择要添加到索引键的表列。
- 单击“确定”按钮,返回到“新建索引”窗体,在“新建索引”窗体中,单击“确定”按钮,便完成了索引的创建。



使用Transact-SQL语句创建索引
- CREATE INDEX语句为给定表或视图创建一个改变物理顺序的聚集索引,也可以创建一个具有查询功能的非聚集索引。
- 语法如下:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name
ON { table | view } ( column [ ASC | DESC ] [ ,…n ] )
[ WITH < index_option > [ ,…n] ]
[ ON filegroup ]
< index_option > ::=
{ PAD_INDEX |
FILLFACTOR = fillfactor |
IGNORE_DUP_KEY |
DROP_EXISTING |
STATISTICS_NORECOMPUTE |
SORT_IN_TEMPDB
} - CREATE INDEX语句的参数说明。
[UNIQUE][CLUSTERED|NONCLUSTERED]:指定创建索引的类型,参数依次为唯一索引、聚集索引和非聚集索引。当省略UNIQUE选项时,建立非唯一索引,省略CLUSTERED|NONCLUSTERED选项时,建立聚集索引,省略NONCLUSTERED选项时,建立唯一聚集索引。
INDEX_NAME:索引名。索引名在表或视图中必须唯一,但在数据库中不必唯一。索引名必须遵循标识符规则。
TABLE:包含要创建索引的列的表。可以选择指定数据库和表所有者。
COLUMN:应用索引的列。指定两个或多个列名,可为指定列的组合值创建组合索引。
[ASC | DESC]:确定具体某个索引列的升序或降序排序方向。默认设置为ASC。
PAD_INDEX:指定索引中间级中每个页(节点)上保持开放的空间。
FILLFACTOR:指定在SQL SERVER创建索引的过程中,各索引页的填满程度。
IGNORE_DUP_KEY:控制向唯一聚集索引的列插入重复的键值时所发生的情况。如果为索引指定了IGNORE_DUP_KEY,并且执行了创建重复键的INSERT语句,SQL SERVER将发出警告消息并忽略重复的行。
DROP_EXISTING:指定应删除并重建已命名的先前存在的聚集索引或非聚集索引。
SORT_IN_TEMPDB:指定用于生成索引的中间排序结果将存储在“TEMPDB”数据库中。
ON FILEGROUP:在给定的文件组上创建指定的索引。该文件组必须已创建。 - 创建索引的原则
使用索引虽然可以提高系统的性能,增强数据的检索速度,但它需要占用大量的物理存储空间,建立索引的一般原则如下。
(1)只有表的所有者可以在同一个表中创建索引。
(2)每个表中只能创建一个聚集索引。
(3)每个表中最多可以创建249个非聚集索引。
(4)在经常查询的字段上建立索引。
(5)定义text、image和bit数据类型的列上不要建立索引。
(6)在外键列上可以建立索引。
(7)主键列上一定要建立索引。
(8)在那些重复值比较多、查询较少的列上不要建立索引。
七.查看索引信息
- 使用企业管理器查看索引
使用企业管理器查看索引的步骤如下:
(1)启动SQL Server Management Studio,并连接到SQL Server 2012数据库.。
(2)选择指定的数据库“db_2012”,然后展开要查看索引的表。
(3)鼠标右键单击该表,在弹出的快捷菜单中选择“设计”命令。
(4)弹出“表结构设计”窗体,鼠标右键单击该窗体,在弹出的快捷菜单中选择“索引/键”命令。
(5)打开“索引/键”窗体。在窗口的左侧选中某个索引,在窗口的右侧就可以查看此索引的信息,并可以修改相关的信息。
- 利用系统表查看索引信息
查看数据库中指定表的索引信息,可以利用该数据库中的系统表sysobjects(记录当前数据库中所有对象的相关信息)和sysindexes(记录有关索引和建立索引表的相关信息)进行查询,系统表sysobjects可以根据表名查找到索引表的ID号,再利用系统表sysindexes根据ID号查找到索引文件的相关信息。

八.修改索引
- 使用企业管理器修改索引
使用企业管理器修改索引与使用企业管理器查看索引的步骤相同,在“索引/键”窗体中就可以修改索引的相关信息。 - 使用TRANSACT-SQL语句更改索引名称
在当前数据库中更改用户创建对象的名称。此对象可以是表、索引、列、别名数据类型或 MICROSOFT .NET FRAMEWORK 公共语言运行时 (CLR) 用户定义类型。 - 语法如下:
SP_RENAME [ @OBJNAME = ] ‘OBJECT_NAME’ ,
[ @NEWNAME = ] ‘NEW_NAME’
[ , [ @OBJTYPE = ] ‘OBJECT_TYPE’ ] - 参数说明:
[ @OBJNAME = ] ‘OBJECT_NAME’:用户对象或数据类型的当前限定或非限定名称。
[ @NEWNAME = ] ‘NEW_NAME’:指定对象的新名称。
[ @OBJTYPE = ] ‘OBJECT_TYPE’:要重命名的对象的类型。
注意:
要对索引进行重命名时,需要修改的索引名格式必须为“表名.索引名”。
九.销毁索引
- 使用企业管理器删除索引
使用企业管理器删除索引与使用企业管理器查看索引的步骤相同,在“索引/键”窗体,单击“删除”按钮,就可以把当前选中的索引删除。 - 使用Transact-SQL语句删除索引
DROP INDEX 语句表示从当前数据库中删除一个或多个关系索引、空间索引、筛选索引或 XML 索引。
DROP INDEX 语句不适用于通过定义 PRIMARY KEY 或 UNIQUE 约束创建的索引。若要删除该约束和相应的索引,请使用带有 DROP CONSTRAINT 子句的 ALTER TABLE。 - DROP INDEX 语句的语法如下:
DROP INDEX
{ <drop_relational_or_xml_or_spatial_index> [ ,…n ]
| <drop_backward_compatible_index> [ ,…n ]
}
<drop_relational_or_xml_or_spatial_index> ::=
index_name ON
[ WITH ( <drop_clustered_index_option> [ ,…n ] ) ]
<drop_backward_compatible_index> ::=
[ owner_name. ] table_or_view_name.index_name
::=
{
[ database_name. [ schema_name ] . | schema_name. ]
table_or_view_name
} - DROP INDEX 语句的参数说明。
INDEX_NAME:要删除的索引名称。
DATABASE_NAME:数据库的名称。
SCHEMA_NAME:该表或视图所属架构的名称。
TABLE_OR_VIEW_NAME:与该索引关联的表或视图的名称。
<DROP_CLUSTERED_INDEX_OPTION>:控制聚集索引选项。这些选项不能与其他索引类型一起使用。
十.设置索引的选项
- 设置PAD_INDEX选项
PAD_INDEX选项是设置创建索引期间中间级别页中可用空间的百分比。
对于非叶级索引页需要使用PAD_INDEX选项设置其预留空间的大小。PAD_INDEX选项只有在指定了FILLFACTOR选项时才有用,因为PAD_INDEX是由FILLFACTOR所指定的百分比决定。默认情况下,给定中间级页上的键集,SQL Server将确保每个索引页上的可用空间至少可以容纳一个索引允许的最大行。如果FILLFACTOR指定的百分比不够大,无法容纳一行,SQL Server将在内部使用允许的最小值替代该百分比。
【例7.8】 为“Student”表的Sno列创建一个簇索引“IS_Stu_Sno”,并将预留空间设置为“10”,SQL语句如下。
USE db_2012
CREATE UNIQUE CLUSTERED INDEX IS_Stu_Sno --唯一聚集索引
on Student(Sno)
with pad_index,fillfactor = 10 --填充因子,设置中间级别页、每个索引页的页级别可用空间 - 设置FILLFACTOR选项
(1)FILLFACTOR选项是设置创建索引期间每个索引页的页级别中可用空间的百分比。
(2)数据库系统在存储数据库文件时,有时会将用到的数据页隔断,在使用数据索引的同时会产生一定程度的碎片。为了尽量减少页拆分,在创建索引时,可以选择FILLFACTOR(称为填充因子)选项,此选项用来指定各索引页的填满程度,即指定索引页上所留出的额外的间隙和保留一定的百分比空间,从而扩充数据的存储容量和减少页拆分。FILLFACTOR选项的取值范围是1~100,表示用户创建索引时数据容量所占页容量的百分比。 - 设置ASC/DESC选项
排序查询是指将查询结果按指定属性的升序(ASC)或降序(DESC)排列,由ORDER BY子句指明。ASC/DESC选项可以在创建索引时设置索引方式。
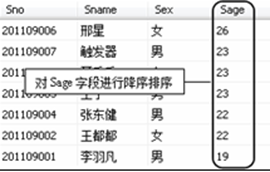
【例7.10】 在Student表中创建一个聚集索引MR,将Sage列按降序排序,SQL语句如下。
USE db_2012
CREATE CLUSTERED INDEX MR ON Student (Sage DESC) --为表Student创建聚集索引,降序排列
创建索引后。
- 设置SORT_IN_TEMPDB选项
(1)SORT_IN_TEMPDB选项是确定对创建索引期间生成的中间排序结果进行排序的位置。如果为 ON,则排序结果存储在 tempdb 中。如果为 OFF,则排序结果存储在存储结果索引的文件组或分区方案中。
十一.索引的分析与维护
索引的分析
A.使用SHOWPLAN语句
显示查询语句的执行信息,包含查询过程中连接表时所采取的每个步骤以及选择哪个索引。
- 语句如下:
SET SHOWPLAN_ALL { ON | OFF }
SET SHOWPLAN_TEXT { ON | OFF } - 参数说明:
(1)ON:显示查询执行信息。
(2) OFF:不显示查询执行信息(系统默认)。
SET SHOWPLAN_ALL 是在执行或运行时设置,而不是在分析时设置。如果 SET SHOWPLAN_ALL 为 ON,则 SQL SERVER 将返回每个语句的执行信息但不执行语句。TRANSACT-SQL 语句不会被执行。在将此选项设置为 ON 后,将始终返回有关所有后续 TRANSACT-SQL 语句的信息,直到将该选项设置为 OFF 为止。
SET SHOWPLAN_TEXT 的设置是在执行或运行时设置的,而不是在分析时设置的。当 SET SHOWPLAN_TEXT 为 ON 时,SQL SERVER 将返回每个 TRANSACT-SQL 语句的执行信息,但不执行语句。将该选项设置为 ON 以后,将返回有关所有后续 SQL SERVER 语句的执行计划信息,直到将该选项设置为 OFF 为止。
B.使用STATISTICS IO语句
STATISTICS IO语句表示使 SQL Server 显示有关由 Transact-SQL 语句生成的磁盘活动量的信息。
- 语法如下:
SET STATISTICS IO { ON | OFF }
如果 STATISTICS IO 为 ON,则显示统计信息。如果为 OFF,则不显示统计信息。如果将此选项设置为 ON,则所有后续的 Transact-SQL 语句将返回统计信息,直到将该选项设置为 OFF 为止。
【例7.16】 在“db_2012”数据库中的“Student”表中查询所有性别为男且年龄大于20岁的学生信息,并显示查询处理过程在磁盘活动的统计信息,SQL语句如下。
USE db_2012
GO
SET STATISTICS IO ON
GO
SELECT Sname,Sex,Sage FROM Student WHERE Sex=‘男’ AND Sage >20
GO
SET STATISTICS IO OFF;
GO
索引的维护
A.使用DBCC SHOWCONTIG语句
显示指定表的数据和索引的碎片信息。当对表进行大量的修改或添加数据后,应该执行此语句来查看有无碎片。显示指定的表或视图的数据和索引的碎片信息。
- 语法如下:
DBCC SHOWCONTIG
[ (
{ table_name | table_id | view_name | view_id }
[ , index_name | index_id ]
) ]
[ WITH
{
[ , [ ALL_INDEXES ] ]
[ , [ TABLERESULTS ] ]
[ , [ FAST ] ]
[ , [ ALL_LEVELS ] ]
[ NO_INFOMSGS ]
}
} - DBCC SHOWCONTIG语句的参数说明。
(1)TABLE_NAME | TABLE_ID | VIEW_NAME | VIEW_ID:要检查碎片信息的表或视图。如果未指定,则检查当前数据库中的所有表和索引视图。
(2)INDEX_NAME | INDEX_ID:要检查碎片信息的索引。如果未指定,则该语句将处理指定表或视图的基本索引。
(3)WITH:指定有关DBCC语句返回的信息类型的选项。
(4)FAST:指定是否要对索引执行快速扫描和输出最少信息。快速扫描不读取索引的叶或数据级页。
(5)ALL_INDEXES:显示指定表和视图的所有索引的结果,即使指定了特定索引也是如此。
(6)TABLERESULTS:将结果显示为含附加信息的行集。
(7)ALL_LEVELS:仅为保持向后兼容性而保留。
(8)NO_INFOMSGS:取消严重级别从0到10的所有信息性消息。
说明: 当扫描密度为100%时,说明表无碎片信息。
B.使用DBCC DBREINDEX语句
DBCC DBREINDEX表示对指定数据库中的表重新生成一个或多个索引。
- 语法如下:
DBCC DBREINDEX
(
TABLE_NAME
[ , INDEX_NAME [ , FILLFACTOR ] ]
)
[ WITH NO_INFOMSGS ] - 参数说明:
TABLE_NAME:包含要重新生成的指定索引的表的名称。表名称必须遵循有关标识符的规则。
INDEX_NAME:要重新生成的索引名。索引名称必须符合标识符规则。
FILLFACTOR:在创建或重新生成索引时,每个索引页上用于存储数据的空间百分比。
WITH NO_INFOMSGS:取消显示严重级别从 0 到 10 的所有信息性消息。
C.使用DBCC INDEXDEFRAG语句
DBCC INDEXDEFRAG语句指定表或视图的索引碎片整理。
- 语法如下:
DBCC INDEXDEFRAG
(
{ DATABASE_NAME | DATABASE_ID | 0 }
, { TABLE_NAME | TABLE_ID | VIEW_NAME | VIEW_ID }
[ , { INDEX_NAME | INDEX_ID } [ , { PARTITION_NUMBER | 0 } ] ]
)
[ WITH NO_INFOMSGS ] - DBCC INDEXDEFRAG语句的参数说明。
DATABASE_NAME | DATABASE_ID | 0:包含要进行碎片整理的索引的数据库。如果指定 0,则使用当前数据库。
TABLE_NAME | TABLE_ID | VIEW_NAME | VIEW_ID:包含要进行碎片整理的索引的表或视图。
INDEX_NAME | INDEX_ID:是要进行碎片整理的索引。索引名必须符合标识符的规则。
PARTITION_NUMBER | 0:要进行碎片整理的索引的分区号。如果未指定或指定 0,该语句将对指定索引的所有分区进行碎片整理。
WITH NO_INFOMSGS:取消严重级别从0到10的所有信息性消息。
十二.索引和全文目录
A.使用企业管理器启用全文索引
- 操作步骤如下:
(1)启动SQL SERVER MANAGEMENT STUDIO,并连接到SQL SERVER 2012数据库.。
(2)选择指定的数据库“DB_2012”,然后鼠标右键单击要创建索引的表,在弹出的快捷菜单中选择“全文索引/定义全文索引”命令,弹出“新建索引”窗体。
(3)打开“全文索引向导”窗体


B.使用Transact-SQL语句启用全文索引
a. 指定数据库启用全文索引
SP_FULLTEXT_DATABASE用于初始化全文索引,或者从当前数据库中删除所有的全文目录。在 SQL SERVER 2012 及更高版本中对全文目录无效,支持它仅仅是为了保持向后兼容。SP_FULLTEXT_DATABASE 不会对给定数据库禁用全文引擎。在 SQL SERVER 2012 中,所有用户创建的数据库始终启用全文索引。
- 语法如下:
SP_FULLTEXT_DATABASE [@ACTION=] ‘ACTION’ - 参数说明:
[ @ACTION=] ‘ACTION’:要执行的操作。ACTION的数据类型为VARCHAR(20),参数取值。
ENABLE:在当前数据库中启用全文索引。
DISABLE:对于当前数据库,删除文件系统中所有的全文目录,并且将该数据库标记为已经禁用全文索引。这个动作并不在全文目录或在表上更改任何全文索引元数据。
b.指定表启用全文索引
SP_FULLTEXT_TABLE用于标记或取消标记要编制全文索引的表。
- 语法如下:
SP_FULLTEXT_TABLE [ @TABNAME = ] ‘QUALIFIED_TABLE_NAME’
, [ @ACTION = ] ‘ACTION’
[ , [ @FTCAT = ] ‘FULLTEXT_CATALOG_NAME’
, [ @KEYNAME = ] ‘UNIQUE_INDEX_NAME’ ] - 参数说明:
(1)[@TABNAME =] ‘QUALIFIED_TABLE_NAME’:表名。该表必须存在当前的数据库中。数据类型为NVARCHAR(517),无默认值。
(2) [@ACTION =] ‘ACTION’:将要执行的动作。ACTION的数据类型为VARCHAR(20),无默认值,参数取值。
①CREATE:为QUALIFIED_TABLE_NAME引用的表创建全文索引的元数据,并且指定该表的全文索引数据应该驻留在FULLTEXT_CATALOG_NAME中。
②DROP:对于 QUALIFIED_TABLE_NAME除去全文索引上的元数据。如果全文索引是活动的,那么在除去它之前会自动停用它。在除去全文索引之前,不必删除列。
③ACTIVATE:停用全文索引后,激活为QUALIFIED_TABLE_NAME聚集全文索引的数据。在激活全文索引之前,应该至少有一列参与这个全文索引。
④ DEACTIVATE:停用的全文索引,使得无法再为QUALIFIED_TABLE_NAME聚集全文索引数据。全文索引元数据依然保留,并且该表还可以被重新激活。
⑤START_CHANGE_TRACKING:启动全文索引的增量填充。如果该表没有时间戳,那么就启动全文索引的完全填充,开始跟踪表发生的变化。
⑥STOP_CHANGE_TRACKING:停止跟踪表发生的变化。
⑦UPDATE_INDEX:将当前一系列跟踪的变化传播到全文索引。
⑧START_BACKGROUND_UPDATEINDEX:在变化发生时,开始将跟踪的变化传播到全文索引。
⑨ STOP_BACKGROUND_UPDATEINDEX:在变化发生时,停止将跟踪的变化传播到全文索引。
⑩START_FULL:启动表的全文索引的完全填充。
⑪ START_INCREMENTAL:启动表的全文索引的增量填充。
(3)[@FTCAT =] ‘FULLTEXT_CATALOG_NAME’:CREATE动作有效的全文目录名。对于所有其他动作,该参数必须为NULL。FULLTEXT_CATALOG_NAME的数据类型为SYSNAME,默认值为NULL。
(4) [@KEYNAME =] ‘UNIQUE_INDEX_NAME’:有效的单键列,CREATE动作在QUALIFIED_TABLE_NAME上的唯一的非空索引。对于所有其他动作,该参数必须为NULL。UNIQUE_INDEX_NAME的数据类型为SYSNAME,默认值为NULL。 - 用表启用全文索引的操作步骤如下:
(1)将要启用全文索引的表创建一个唯一的非空索引(在以下示例中其索引名为“MR_EMP_ID_FIND”)。
(2)用表所在的数据库启用全文索引。
(3)在该数据库中创建全文索引目录(在以下示例中全文索引目录为ML_EMPLOY)。
(4)用表启用全文索引标记。
(5)向表中添加索引字段。
(6)激活全文索引。
(7)启动完全填充。
C.使用Transact-SQL语句删除全文索引
DROP FULLTEXT INDEX从指定的表或索引视图中删除全文索引。
- 语法如下:
DROP FULLTEXT INDEX ON TABLE_NAME - 参数说明:
TABLE_NAME:包含要删除的全文索引的表或索引视图的名称。
D.全文目录相关操作
a.对于 SQL SERVER 2012 数据库,全文目录为虚拟对象,并不属于任何文件组;它是一个表示一组全文索引的逻辑概念。
1. 全文目录的创建、删除和重创建 SP_FULLTEXT_CATALOG用于创建和删除全文目录,并启动和停止目录的索引操作。可为每个数据库创建多个全文目录。 **注意: 在以后的 SQL SERVER 版本中,将删除 SP_FULLTEXT_CATALOG 存储过程。所以应避免在新的开发工作中使用此功能,并计划修改当前使用该存储过程的应用程序。** 2. 语法如下: SP_FULLTEXT_CATALOG [ @FTCAT = ] 'FULLTEXT_CATALOG_NAME' , [ @ACTION = ] 'ACTION' [ , [ @PATH = ] 'ROOT_DIRECTORY' ] 3. 参数说明: (1) [@FTCAT =] 'FULLTEXT_CATALOG_NAME':全文目录的名称。对于每个数据库,目录名必须是唯一的。其数据类型为SYSNAME。 (2) [@ACTION =] 'ACTION':将要执行的动作。ACTION的数据类型为VARCHAR(20),参数取值。 ①CREATE:在文件系统中创建一个空的新全文目录,并向SYSFULLTEXTCATALOGS添加一行。 ②DROP:将全文目录从文件系统中删除,并且删除SYSFULLTEXTCATALOGS中相关的行。 ③START_INCREMENTAL:启动全文目录的增量填充。如果目录不存在,就会显示错误。 ④START_FULL:启动全文目录的完全填充。即使与此全文目录相关联的每一个表的每一行都进行过索引,也会对其检索全文索引。 ⑤STOP:停止全文目录的索引填充。如果目录不存在,就会显示错误。如果已经停止了填充,那么并不会显示警告。b.向全文目录中增加、删除列
SP_FULLTEXT_COLUMN指定表的某个特定列是否参与全文索引。
注意:
后续版本的 MICROSOFT SQL SERVER 将删除该功能。请避免在新的开发工作中使用该功能,并着手修改当前还在使用该功能的应用程序。
- 语法如下:
SP_FULLTEXT_COLUMN [ @TABNAME= ] ‘QUALIFIED_TABLE_NAME’ ,
[ @COLNAME= ] ‘COLUMN_NAME’ ,
[ @ACTION= ] ‘ACTION’
[ , [ @LANGUAGE= ] ‘LANGUAGE’ ]
[ , [ @TYPE_COLNAME= ] ‘TYPE_COLUMN_NAME’ ] - 参数说明:
(1) [ @TABNAME= ] ‘QUALIFIED_TABLE_NAME’:由一部分或两部分组成的表的名称。表必须在当前数据库中。表必须有全文索引。QUALIFIED_TABLE_NAME 的数据类型为 NVARCHAR(517),无默认值。
(2) [ @COLNAME= ] ‘COLUMN_NAME’:QUALIFIED_TABLE_NAME 中列的名称。列必须为字符列、VARBINARY(MAX) 列或 IMAGE 列,不能是计算列。COLUMN_NAME 的数据类型为 SYSNAME,无默认值。
注意:
SQL SERVER 可以为存储在数据类型为VARBINARY(MAX)或IMAGE的列中的文本数据创建全文索引。不对图像或图片进行索引。
(3)[ @ACTION=] ‘ACTION’:要执行的操作。ACTION 的数据类型为 VARCHAR(20),无默认值,可以是下面的列值之一。
① ADD:将QUALIFIED_TABLE_NAME的COLUMN_NAME添加到表的非活动全文索引中。该动作启用全文索引的列。
② DROP:从表的非活动全文索引中删除QUALIFIED_TABLE_NAME的COLUMN_NAME。
(4) [ @LANGUAGE= ] ‘LANGUAGE’:存储在列中的数据的语言。
(5) [ @TYPE_COLNAME = ] ‘TYPE_COLUMN_NAME’:QUALIFIED_TABLE_NAME 中列的名称,用于保存 COLUMN_NAME 的文档类型。此列必须是 CHAR、NCHAR、VARCHAR 或 NVARCHAR。仅当 COLUMN_NAME 数据类型为 VARBINARY(MAX) 或 IMAGE 时才使用该列。TYPE_COLUMN_NAME 的数据类型为 SYSNAME,无默认值。
c.激活全文目录
要激活表“student”的全文目录,首先要在表中创建全文索引,具体步骤可参见7.6.1节中的“指定表启用全文索引”。
- 激活全文目录的SQL语句如下:
USE db_2012
EXEC sp_fulltext_table ‘student’,‘activate’ - 这样就完成了对全文目录的定义,如果要对创建的全文目录进行初始化填充(即全文添充),可以使用如下SQL语句:
USE db_2012
EXEC sp_fulltext_table ‘student’,‘start_full’
E.维护全文目录
a.用企业管理器来维护全文目录
- 操作步骤如下:
(1)启动SQL Server Management Studio,并连接到SQL Server 2012数据库.。
(2)选择指定数据库中的数据表(这里以“db_2012”数据库中的“Employee”表为例,该表已经创建全文索引)。
(3)在“Employee”表上单击鼠标右键,在快捷菜单中选择“全文索引”命令。
(4)在“全文索引”的级联菜单中就可以对全文目录进行修改,具体功能。


十三.认识数据库的完整性
A.实现域完整性
域是指数据表中的列(字段),域完整性就是指列的完整性。指列数据输入的有效性。实现域完整性的方法有:限制类型(通过数据类型)、格式(通过CHECK约束和规则)或可能的取值范围(通过CHECK约束、DEFAULT定义、NOT NULL定义和规则)等。它要求数据表中指定列的数据具有正确的数据类型、格式和有效的数据范围。
域完整性常见的实现机制包括:
默认值(DEFAULT)
检查(CHECK)
外键(FOREIGN KEY)
数据类型(DATA TYPE)
规则(RULE)
B.实体完整性
现实世界中,任何一个实体都有区别于其他实体的特征,即实体完整性。在SQL SERVER数据库中,实体完整性又称为行的完整性,要求表中的一个主键,其值不能为空能惟一地标识对应的记录。通过索引、UNIQUE约束、PRIMARY KEY约束或IDENTITY属性等可实现数据的实体完整性。可以通过以下几项实施实体完整性。
唯一索引(UNIQUE INDEX)
主键(PRIMARY KEY)
唯一码(UNIQUE KEY)
标识列(IDENTITY COLUMN)
C.引用完整性
引用完整性又称参照完整性,引用完整性保证主表中的数据与从表中数据的一致性。SQL Server 2012中,参照完整性的实现是通过定义外键与主键之间或外键与惟一键之间的对应关系实现的。参照完整性确保键值在所有表中一致。参照完整性的实现方法如下:
(1)外键(Foreign Key)。
(2)检查(Check)。
(3)触发器(Trigger)。
(4)存储过程(Stored Procedure)
D.用户定义完整性
用户定义完整性使您可以定义不属于其他任何完整性类别的特定业务规则。所有完整性类别都支持用户定义完整性。这包括 CREATE TABLE 中所有列级约束和表级约束、存储过程以及触发器。
E.混淆全文索引和全文目录
索引侧重于定位要找的数据,目录侧重于显示整体结构。全文索引是为表建立的,全文目录是用来保存全文索引的。全文目录通常是由一个数据库中的几个全文索引构成的。一个表只能有一个全文索引。如果一个表上创建了全文索引,那么该表将只能隶属于一个全文目录。一个数据库可以有多个全文目录,一个全文目录可以有多个全文索引,但一个数据表只能隶属于一个全文目录和全文索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号