

机器学习第二次作业
机器学习第二次作业
1.Iris数据集已与常见的机器学习工具集成,请查阅资料找出MATLAB平台或Python平台加载内置Iris数据集方法,并简要描述该数据集结构。
from sklearn import datasets
iris = datasets.load_iris()
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于(iris-setosa, iris-versicolour, iris-virginica)中的哪一品种。
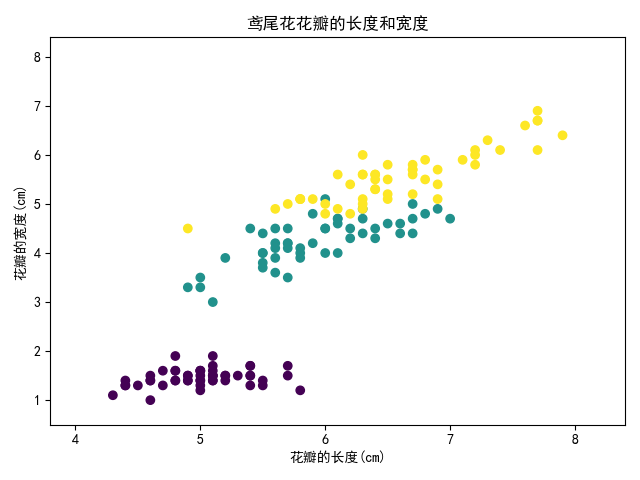
2.Iris数据集中有一个种类与另外两个类是线性可分的,其余两个类是线性不可分的。请你通过数据可视化的方法找出该线性可分类并给出判断依据。
from sklearn import datasets
import matplotlib
import matplotlib.pyplot as plt
import pandas
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #显示中文
iris = datasets.load_iris()
#print(iris.data) # 数据集中的数据
#print(iris.target) # iris的种类
#print(iris.target_names)
x=iris.data[:,2]
y=iris.data[:,1]
x_min, x_max = x.min() - 0.5, x.max() + 0.5
y_min, y_max = y.min() - 0.5, x.max() + 0.5
# Scatterplot
plt.figure()
plt.title('鸢尾花花瓣的长度和宽度')
plt.scatter(x, y, c=iris.target)
plt.xlabel('花瓣的长度(cm)')
plt.ylabel('花瓣的宽度(cm)')
#c指定点的颜色,当c赋值为数值时,会根据值的不同自动着色
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks()
plt.yticks()
plt.show()
对于三个种类,任选两个进行绘图,共6张图:






 浙公网安备 33010602011771号
浙公网安备 33010602011771号