

Python之路——day10-20230423:字符编码与转换
python的字符编码与转换
一、字符编码
1、ASCII码只能存储英文字符,并且一个字符占用一个字节大小。
2、Unicode码可以同时存储中、英文字符,并且统一每个字符占用两个字节大小,这样对英文国家来说就很吃亏,同一个文件本来用ASCII2M大小,现在用了Unicode码变成了4M大小,所以衍生出 了UTF-8编码格式,UTF-8是Unicode码的扩展集,称为可变长的字符编码,对于英文还是按照ASCII格式占用一个字节大小,对于中文按照三个字节大小占用。
二、字符编码转换
看下面这张图就够了:
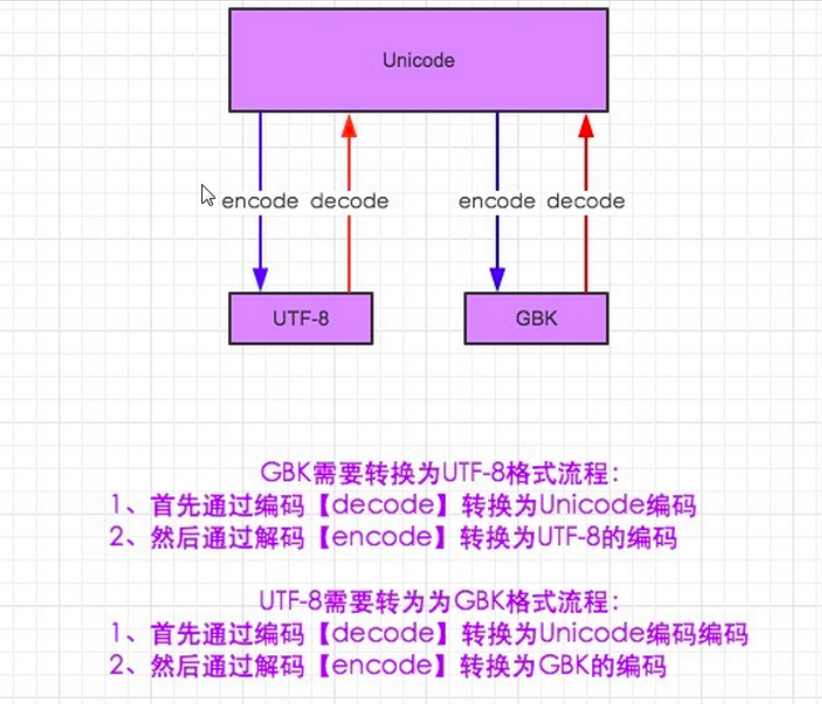
decode:编码,encode:解码,Python的数据类型默认都是Unicode类型的,文件开头声明的编码格式只是代表当前python文件的编码格式,并不是python数据类型的编码格式:
,所以如果要转换为utf-8、gbk或者gb2312格式的话,必须先进行encode解码;utf-8的数据类型可以直接和unicode的数据类型转换并且打印:
s = u"你好" # 数据类型默认还是unicode
print(s)
但是gbk和Unicode编码格式不可以直接进行转换并打印,必须先通过decode进行编码才可以再打印:
s = "你好" # 数据类型默认还是unicode
print(s.encode('gbk').decode('gbk'))在python3里,encode解码不但转换了数据的编码格式,并且将数据统一转换为bytes类型,decode将数据重新转换为了字符串类型:
s = "你好" # 数据类型默认还是unicode
print(s.encode('gbk'))
print(s.encode('gbk').decode('gbk')) D:\selfcontrol\pythonProject\venv\Scripts\python.exe D:/selfcontrol/pythonProject/老男孩day1_20230423/day10-20230423.py
b'\xc4\xe3\xba\xc3'
你好
本文来自博客园,作者:投资交易大师,转载请注明原文链接:https://www.cnblogs.com/qq2751044056/p/17347264.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号