python学习记录8:爬取起点小说信息保存到excel爬虫源码
import xlwt
import requests
from lxml import etree
import time
import xlsxwriter
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
all_info_list=[]
def get_info(url):
html=requests.get(url,headers=headers)
selector=etree.HTML(html.text)
infos=selector.xpath('//ul[@class="all-img-list
cf"]/li')
for info in infos:
name=info.xpath('div[2]/h2/a/text()')[0]
author=info.xpath('div[2]/p[1]/a[1]/text()')[0]
style_1=info.xpath('div[2]/p[1]/a[2]/text()')[0]
style_2=info.xpath('div[2]/p[1]/a[3]/text()')[0]
style=style_1+'.'+style_2
complete=info.xpath('div[2]/p[1]/span/text()')[0]
introduce=info.xpath('div[2]/p[2]/text()')[0].strip()
word=info.xpath('div[2]/p[3]/span/span/text()')[0].strip('万字')
info_list=[name,author,style,complete,introduce,word]
all_info_list.append(info_list)
time.sleep(1)
if __name__=='__main__':
urls=['https://www.qidian.com/all/page{}/'.format(str(i)) for i in
range(1,6)]
for url in urls:
get_info(url)
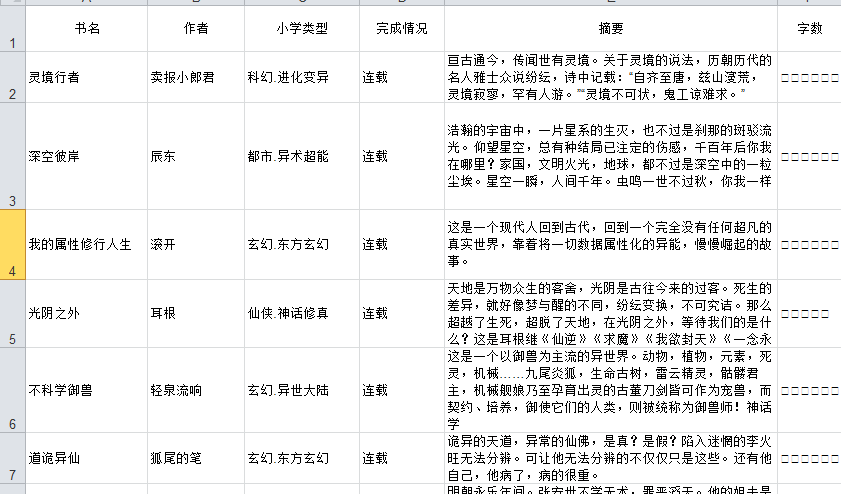
header=['书名','作者','小学类型','完成情况','摘要','字数']
book=xlwt.Workbook(encoding='utf-8')
sheet=book.add_sheet('小说信息')
for h in range(len(header)):
sheet.write(0,h,header[h])
i=1
for info_list in all_info_list:
j=0
for date in info_list:
sheet.write(i,j,date)
j=j+1
i=i+1
book.save('小说信息.xls')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号