知识点整理-挑选索引时有哪些注意事项?
- 背景
例如我们的表及其相关的索引是这样的:
CREATE TABLE person_info ( id INT NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country VARCHAR(100) NOT NULL, PRIMARY KEY (id), KEY idx_name_birthday_phone_number (name, birthday, phone_number) );
其中,有一个联合索引 idx_name_birthday_phone_number
- 下面列举了一些关于索引的一些注意事项:
1.只为用于搜索、排序或分组的列创建索引
也就是说,只为出现在WHERE子句中的列、连接子句中的连接列,或 者出现在ORDER BY或GROUP BY子句中的列创建索引。而出现在查 询列表中的列就没必要建立索引了:
SELECT birthday, country FROM person_name WHERE name = 'Ashburn';
像查询列表中的birthday、country这两个列就不需要建立索引, 我们只需要为出现在WHERE子句中的name列创建索引就可以了。
2. 考虑列的基数
列的基数指的是某一列中不重复数据的个数,比方说某个列包含 值2, 5, 8, 2, 5, 8, 2, 5, 8,虽然有9条记录,但该列的基 数却是3。也就是说,在记录行数一定的情况下,列的基数越大,该 列中的值越分散,列的基数越小,该列中的值越集中。这个列的基数 指标非常重要,直接影响我们是否能有效的利用索引。假设某个列的 基数为1,也就是所有记录在该列中的值都一样,那为该列建立索引 是没有用的,因为所有值都一样就无法排序,无法进行快速查找了~ 而且如果某个建立了二级索引的列的重复值特别多,那么使用这个二 级索引查出的记录还可能要做回表操作,这样性能损耗就更大了。所以结论就是:最好为那些列的基数大的列建立索引,为基数太小列的 建立索引效果可能不好。
3. 索引列的类型尽量小
我们在定义表结构的时候要显式的指定列的类型,以整数类型为例, 有TINYINT、MEDIUMINT、INT、BIGINT这么几种,它们占用的存 储空间依次递增,我们这里所说的类型大小指的就是该类型表示的数 据范围的大小。能表示的整数范围当然也是依次递增,如果我们想要对某整数列建立索引的话,在表示的整数范围允许的情况下,尽量 让索引列使用较小的类型,比如我们能使用INT就不要使 用BIGINT,能使用MEDIUMINT就不要使用INT~ 这是因为:
- 数据类型越小,在查询时进行的比较操作越快(这是CPU层次 的东东)
- 数据类型越小,索引占用的存储空间就越少,在一个数据⻚内 就可以放下更多的记录,从而减少磁盘I/O带来的性能损耗, 也就意味着可以把更多的数据⻚缓存在内存中,从而加快读写 效率。
这个建议对于表的主键来说更加适用,因为不仅是聚簇索引中会存储 主键值,其他所有的二级索引的节点处都会存储一份记录的主键值, 如果主键适用更小的数据类型,也就意味着节省更多的存储空间和更 高效的I/O。
4. 索引列的类型尽量小
我们知道一个字符串其实是由若干个字符组成,如果我们在MySQL中 使用utf8字符集去存储字符串的话,编码一个字符需要占用1~3个 字节。假设我们的字符串很⻓,那存储一个字符串就需要占用很大的 存储空间。在我们需要为这个字符串列建立索引时,那就意味着在对 应的B+树中有这么两个问题:
- B+树索引中的记录需要把该列的完整字符串存储起来,而且字 符串越⻓,在索引中占用的存储空间越大。
- 如果B+树索引中索引列存储的字符串很⻓,那在做字符串比较 时会占用更多的时间。
我们前边儿说过索引列的字符串前缀其实也是排好序的,所以索引的 设计者提出了个方案 --- 只对字符串的前几个字符进行索引也就是 说在二级索引的记录中只保留字符串前几个字符。这样在查找记录时虽然不能精确的定位到记录的位置,但是能定位到相应前缀所在的位 置,然后根据前缀相同的记录的主键值回表查询完整的字符串值,再 对比就好了。这样只在B+树中存储字符串的前几个字符的编码,既 节约空间,又减少了字符串的比较时间,还大概能解决排序的问题, 何乐而不为,比方说我们在建表语句中只对name列的前10个字符进 行索引可以这么写:
CREATE TABLE person_info ( name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country VARCHAR(100) NOT NULL, KEY idx_name_birthday_phone_number (name(10), birthday, phone_number) );
name(10)就表示在建立的B+树索引中只保留记录的前10个字符的 编码,这种只索引字符串值的前缀的策略是我们非常鼓励的,尤其是在字符串类型能存储的字符比较多的时候。
4. 索引列前缀对排序的影响
如果使用了索引列前缀,比方说前边只把name列的前10个字符放到 了二级索引中,下边这个查询可能就有点儿尴尬了:
SELECT * FROM person_info ORDER BY name LIMIT 10;
因为二级索引中不包含完整的name列信息,所以无法对前十个字符 相同,后边的字符不同的记录进行排序,也就是使用索引列前缀的方 式无法支持使用索引排序,只好乖乖的用文件排序喽。
5. 让索引列在比较表达式中单独出现
假设表中有一个整数列my_col,我们为这个列建立了索引。下边的 两个WHERE子句虽然语义是一致的,但是在效率上却有差别:
1. WHERE my_col * 2 < 4
2. WHERE my_col < 4/2
第1个WHERE子句中my_col列并不是以单独列的形式出现的,而是 以my_col * 2这样的表达式的形式出现的,存储引擎会依次遍历所 有的记录,计算这个表达式的值是不是小于4,所以这种情况下是使 用不到为my_col列建立的B+树索引的。而第2个WHERE子句中 my_col列并是以单独列的形式出现的,这样的情况可以直接使 用B+树索引。
所以结论就是:如果索引列在比较表达式中不是以单独列的形式出 现,而是以某个表达式,或者函数调用形式出现的话,是用不到索引 的。
6. 主键插入顺序
我们知道,对于一个使用InnoDB存储引擎的表来说,在我们没有显 式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点 的。而记录又是存储在数据⻚中的,数据⻚和记录又是按照记录主键 值从小到大的顺序进行排序,所以如果我们插入的记录的主键值是依 次增大的话,那我们每插满一个数据⻚就换到下一个数据⻚继续插, 而如果我们插入的主键值忽大忽小的话,这就比较麻烦了,假设某个 数据⻚存储的记录已经满了,它存储的主键值在1~100之间:
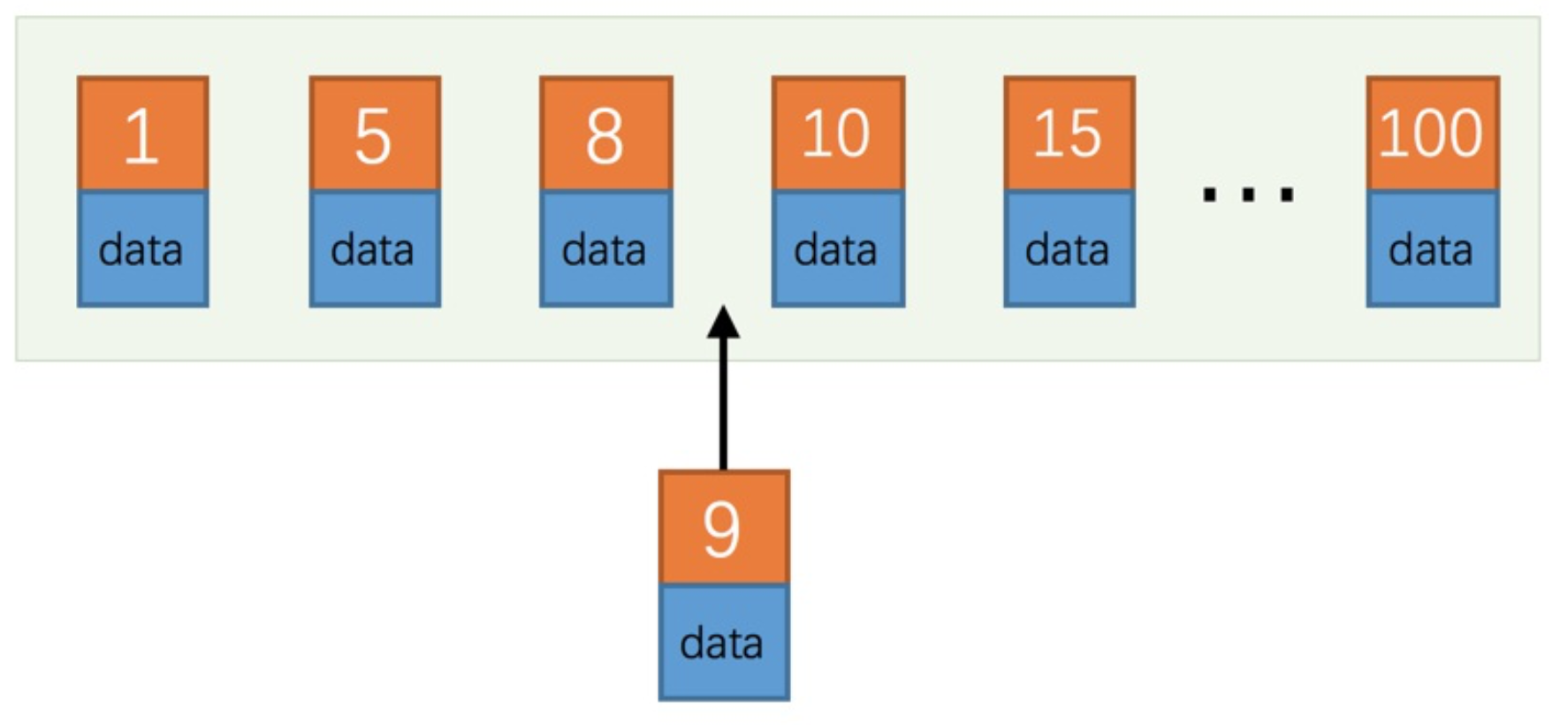
可这个数据⻚已经满了啊,再插进来咋办呢?我们需要把当前⻚面分 裂成两个⻚面,把本⻚中的一些记录移动到新创建的这个⻚中。⻚面 分裂和记录移位意味着什么?意味着:性能损耗!所以如果我们想尽 量避免这样无谓的性能损耗,最好让插入的记录的主键值依次递增, 这样就不会发生这样的性能损耗了。所以我们建议:让主键具有AUTO_INCREMENT,让存储引擎自己为表生成主键,而不是我们手动插入 ,比方说我们可以这样定义person_info表:
CREATE TABLE person_info ( name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country VARCHAR(100) NOT NULL, KEY idx_name_birthday_phone_number (name(10), birthday, phone_number) );
我们自定义的主键列id拥有AUTO_INCREMENT属性,在插入记录时 存储引擎会自动为我们填入自增的主键值。
7. 冗余和重复索引
CREATE TABLE person_info ( id INT UNSIGNED NOT NULL AUTO_INCREMENT, name VARCHAR(100) NOT NULL, birthday DATE NOT NULL, phone_number CHAR(11) NOT NULL, country VARCHAR(100) NOT NULL, PRIMARY KEY (id), KEY idx_name_birthday_phone_number (name(10), birthday, phone_number), KEY idx_name (name(10)) );
我们知道,通过idx_name_birthday_phone_number索引就可以 对name列进行快速搜索,再创建一个专⻔针对name列的索引就算是 一个冗余索引,维护这个索引只会增加维护的成本,并不会对搜索有 什么好处。
另一种情况,我们可能会对某个列重复建立索引,比方说这样:
CREATE TABLE repeat_index_demo (
c1 INT PRIMARY KEY,
c2 INT,
UNIQUE uidx_c1 (c1),
INDEX idx_c1 (c1)
);
我们看到,c1既是主键、又给它定义为一个唯一索引,还给它定义 了一个普通索引,可是主键本身就会生成聚簇索引,所以定义的唯一 索引和普通索引是重复的,这种情况要避免。
- 总结:
在使用索引时需要注意下边这些事项:
- 只为用于搜索、排序或分组的列创建索引 为列的基数大的列创建索引
- 索引列的类型尽量小
- 可以只对字符串值的前缀建立索引
- 只有索引列在比较表达式中单独出现才可以适用索引
- 为了尽可能少的让聚簇索引发生⻚面分裂和记录移位的情 况,建议让主键拥有AUTO_INCREMENT属性。
- 定位并删除表中的重复和冗余索引
- 尽量适用覆盖索引进行查询,避免回表带来的性能损耗。
学习:mysql是怎样运行的:从根儿上理解mysql

 浙公网安备 33010602011771号
浙公网安备 33010602011771号