正则化——解决过拟合问题
线性回归例子
如果
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x\]
通过线性回归得到的曲线可能如下图

这种情况下,曲线对数据的拟合程度不好。这种情况称为“Underfit”,这种情况属于“High bias”(高偏差)。
如果
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x + {\theta _2}{x^2}\]
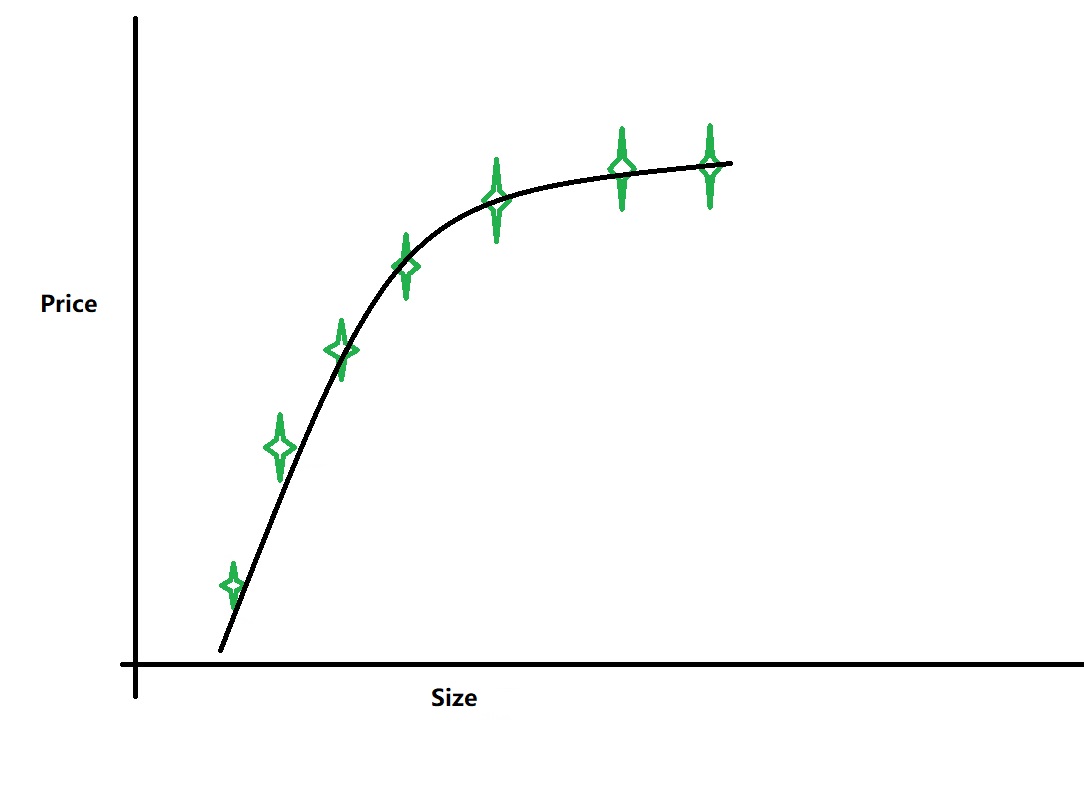
通过线性回归得到的曲线可能如下图
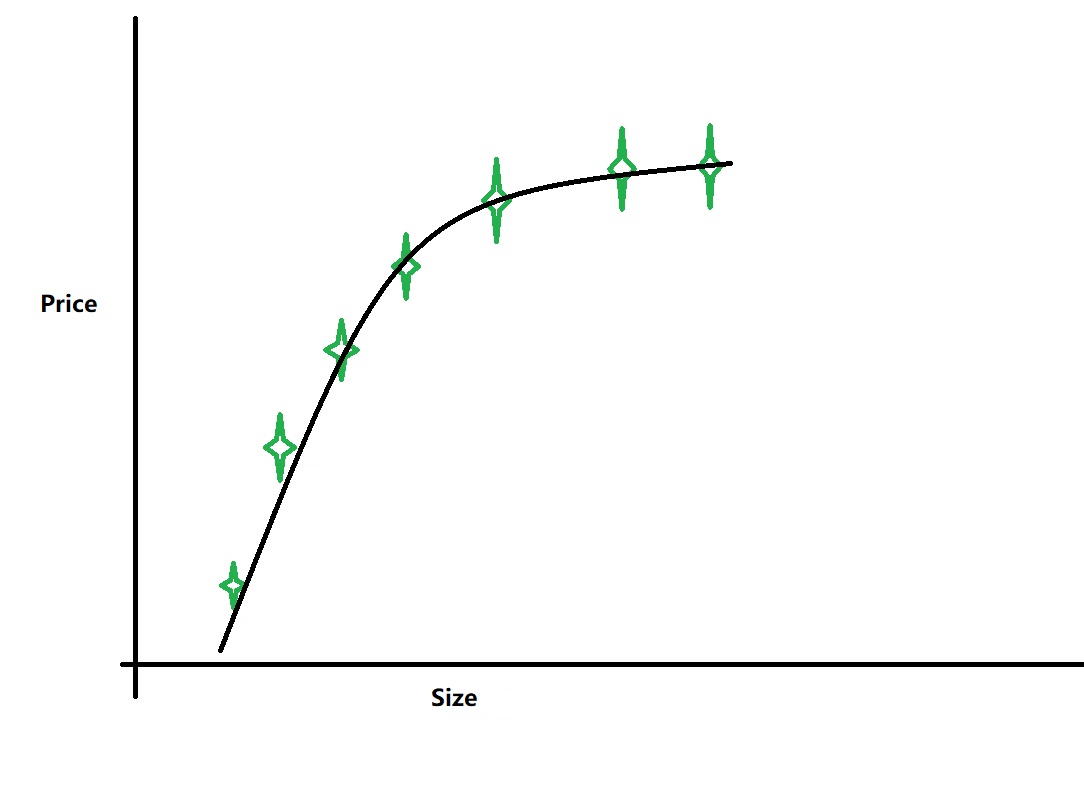
这种情况下,曲线对数据的拟合程度就比较好,可以称为“Just right”。。。
如果
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x + {\theta _2}{x^2} + {\theta _3}{x^3} + {\theta _4}{x^4}\]
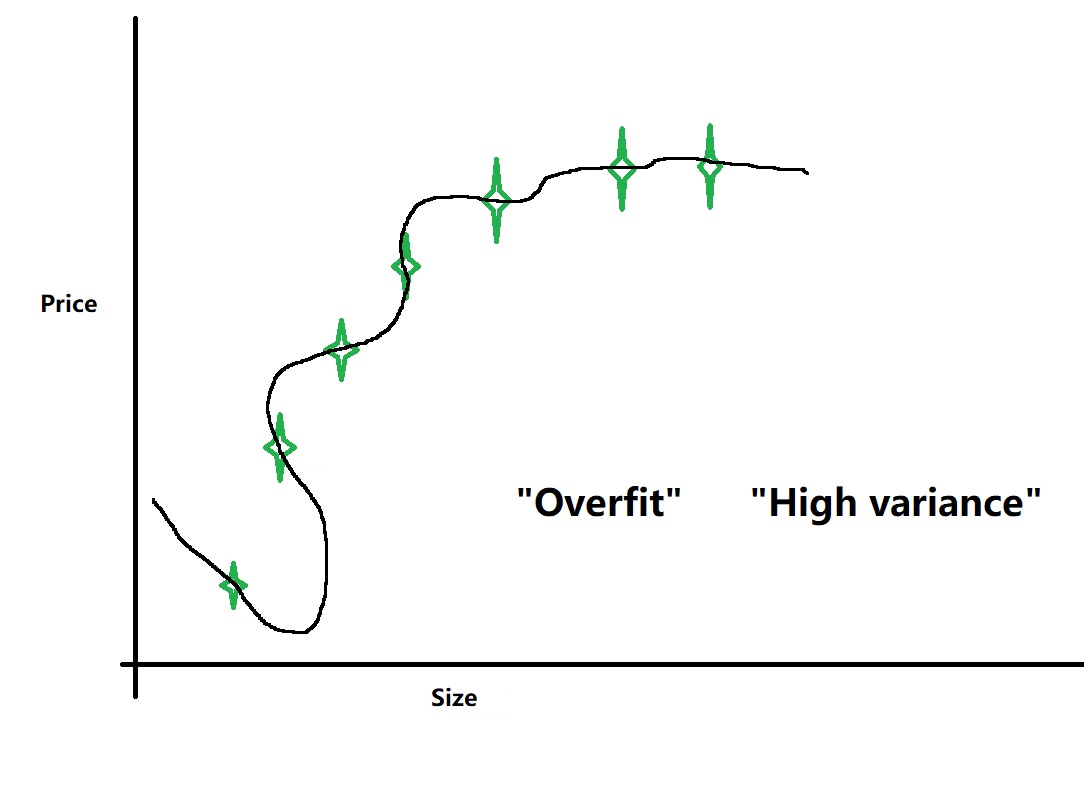
通过线性回归得到的曲线可能如下图
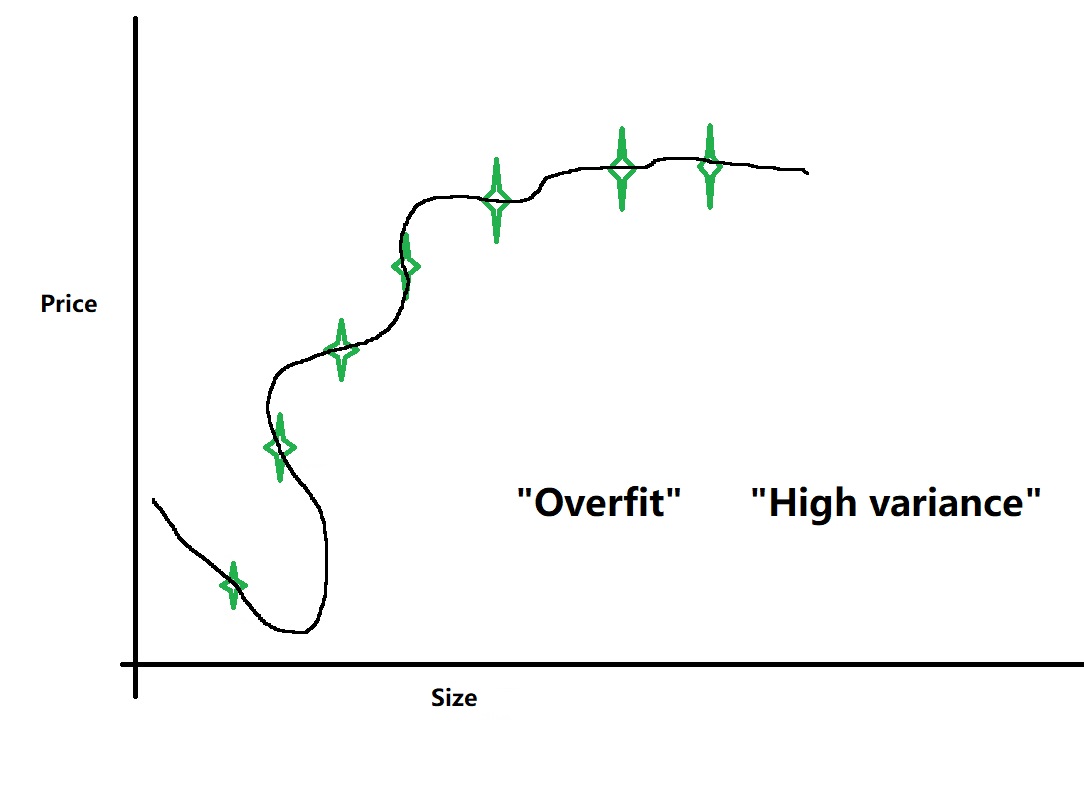
这种情况下虽然对现有数据有很好的拟合程度,但是对于新的数据预测是不合理的。这种情况称为“Overfit”,这种情况属于“High variance”(高方差)。
什么情况会出现过拟合呢?
if we have too many features, the learned hypothesis may fit the training set very well (J(θ)≈0), but fail to generalize to new examples (predict prices on new examples).
如果我们有太多的特征,学习的假设可能非常适合训练集(J(θ)≈0),但不能推广到新的例子(预测新例子的价格)。
在列举逻辑回归的例子
如果
\[\begin{array}{l}
{h_\theta }\left( x \right) = g\left( {{\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2}} \right)\\
\left( {g = sigmoid\_function} \right)
\end{array}\]
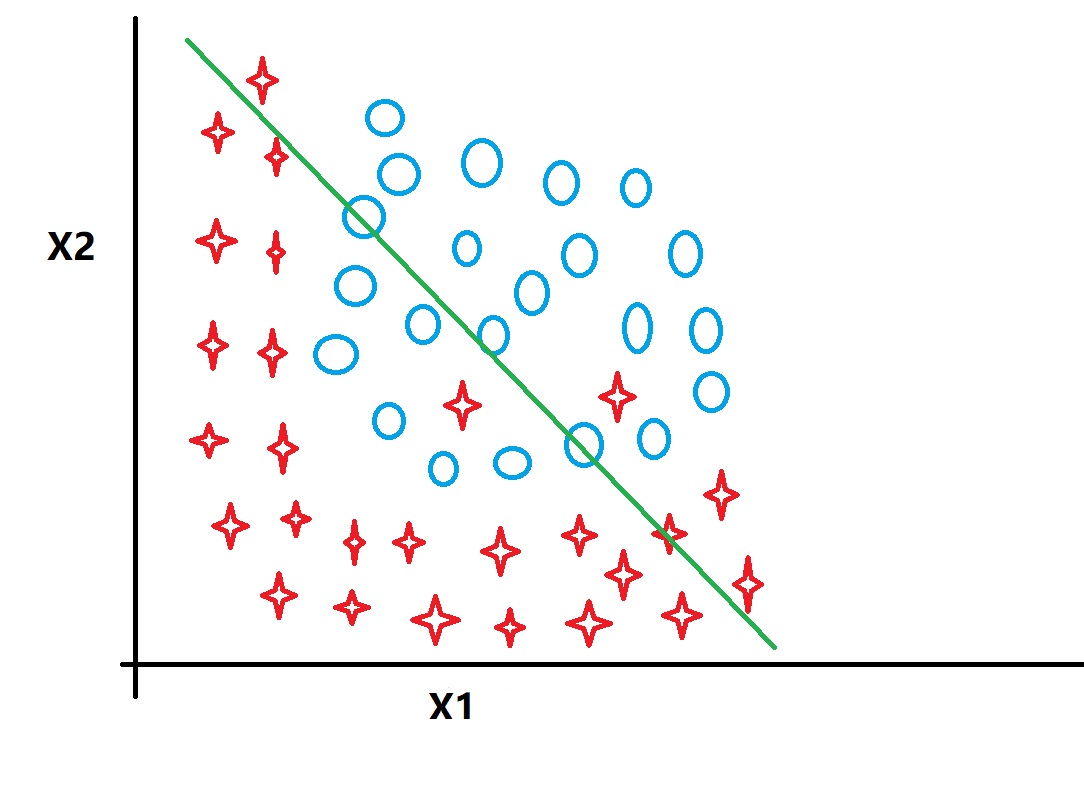
这种情况属于“Underfit”
如果
\[{h_\theta }\left( x \right) = g\left( {{\theta _0} + {\theta _1}{x_1} + {\theta _2}{x_2} + {\theta _3}x_1^2 + {\theta _4}x_2^2 + {\theta _5}{x_1}{x_2}} \right)\]

这种情况属于“Just right”
如果
\[{h_\theta }\left( x \right) = g\left( {{\theta _0} + {\theta _1}{x_1} + {\theta _2}x_1^2 + {\theta _3}x_1^2{x_2} + {\theta _4}x_1^2x_2^2 + {\theta _5}x_1^2x_2^3 + ...} \right)\]
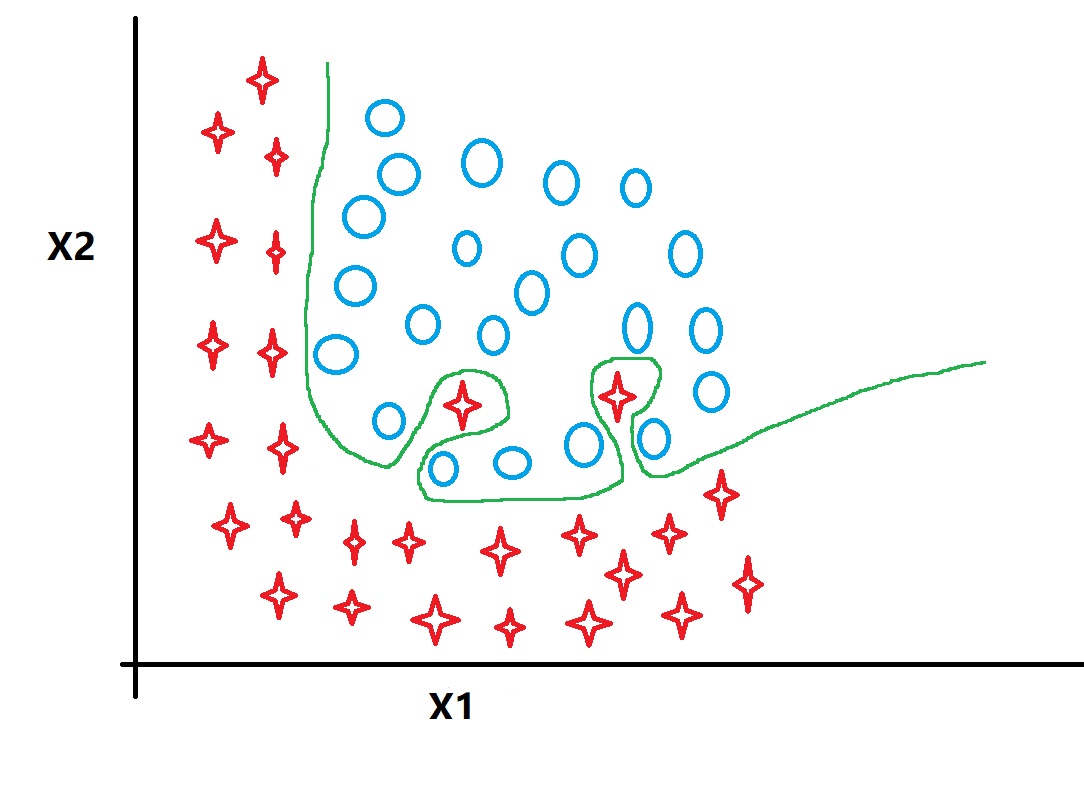
这种情况属于“Overfit”
如何解决过拟合?
方案1:
Reduce number of features.
- Manually select which features to keep.
- Model selection algorithm
减少特征的数量
- 人工决定保留哪些特征
- 运用模型选择算法
存在的问题:去掉特征就意味着去掉“Information”,如果去掉了有用的信息就不好了
方案2:
Regularization
- Keep all the features, but reduce magnitude/values of parameters θj
正规化
- 保留所有特征,但减少参数θj的幅度/值
优点:Works well when we have a lot of features, each of which contributes a bit to predicting y.
当我们有很多特征时效果很好,每个功能都有助于预测y。
正则化具体实现
对比以下两种情况
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x + {\theta _2}{x^2}\]
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x + {\theta _2}{x^2} + {\theta _3}{x^3} + {\theta _4}{x^4}\]
假设我们使θ3,θ4很小,那么x3和x4的影响就会很小,这时过拟合的公式结果就很接近好的情况
我们先假设使用如下公式
\[J\left( \theta \right) = \frac{1}{{2m}}\sum\limits_{i = 1}^m {{{\left( {{h_\theta }\left( {{x^{\left( i \right)}}} \right) - {y^{\left( i \right)}}} \right)}^2}} + 1000\theta _3^2 + 1000\theta _4^2\]
线性回归的目的是
\[\mathop {\min }\limits_\theta \frac{1}{{2m}}\sum\limits_{i = 1}^m {{{\left( {{h_\theta }\left( {{x^{\left( i \right)}}} \right) - {y^{\left( i \right)}}} \right)}^2}} + 1000\theta _3^2 + 1000\theta _4^2\]
因为的θ3,θ4权重比较大,所以要想最小化这个方程,θ3,θ4必须很小,这就起到的减小θ3,θ4的效果。
在正则化方法中,我们不知道需要让那个参数更小,这时我们就让所有参数都小。
加上正则化部分后代价函数为
\[\left( \theta \right) = \frac{1}{{2m}}\left[ {\underbrace {\sum\limits_{i = 1}^m {{{\left( {{h_\theta }\left( {{x^{\left( i \right)}}} \right) - {y^{\left( i \right)}}} \right)}^2}} }_{part1} + \underbrace {\lambda \sum\limits_{j = 1}^n {\theta _j^2} }_{part2}} \right]\]
其中,λ称为正则化参数(regulariztion parameter)。这个函数有两个目标:第一个目标是让h(x)尽量接近y;第二个目标是让每个θ尽量小(或让代价函数尽量简单)。
为什么让所有参数都尽量小就可以达到让函数曲线更接近正确?
自己实现了就比较直观的了解了!!
λ的大小选择问题
对于
\[{h_\theta }\left( x \right) = {\theta _0} + {\theta _1}x + {\theta _2}{x^2} + {\theta _3}{x^3} + {\theta _4}{x^4}\]
如果 λ选的过大,所有的参数θ1,θ2,θ3,θ4都会很小,这样就会出现
\[{h_\theta }\left( x \right) \approx {\theta _0}\]
这就会出现欠拟合(underfit)
如果λ选的过小,就起不到正则化的效果,这样就会出现
\[{h_\theta }\left( x \right) \approx {\theta _0} + {\theta _1}x + {\theta _2}{x^2} + {\theta _3}{x^3} + {\theta _4}{x^4}\]
这样就解决不了过拟合(overfit)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号