梯度下降
Have some function J(θ0, θ1), generally J(θ0, θ1,θ2, θ3,..., θn)
Want: \[\mathop {\min }\limits_{{\theta _0},{\theta _1}} J\left( {{\theta _0},{\theta _1}} \right)\]
generally: \[\mathop {\min }\limits_{{\theta _0},{\theta _1},...{\theta _n}} J\left( {{\theta _0},{\theta _1},...{\theta _n}} \right)\]
Outline:
- Start with some θ0, θ1
- Keep changing θ0, θ1 to reduce J(θ0, θ1) until we hopefully end up at a minimum
有函数J(θ0, θ1),一般情况下表示为J(θ0, θ1,θ2, θ3,..., θn)
目标:\[\mathop {\min }\limits_{{\theta _0},{\theta _1}} J\left( {{\theta _0},{\theta _1}} \right)\]
一般情况下: \[\mathop {\min }\limits_{{\theta _0},{\theta _1},...{\theta _n}} J\left( {{\theta _0},{\theta _1},...{\theta _n}} \right)\]
梯度下降
图示
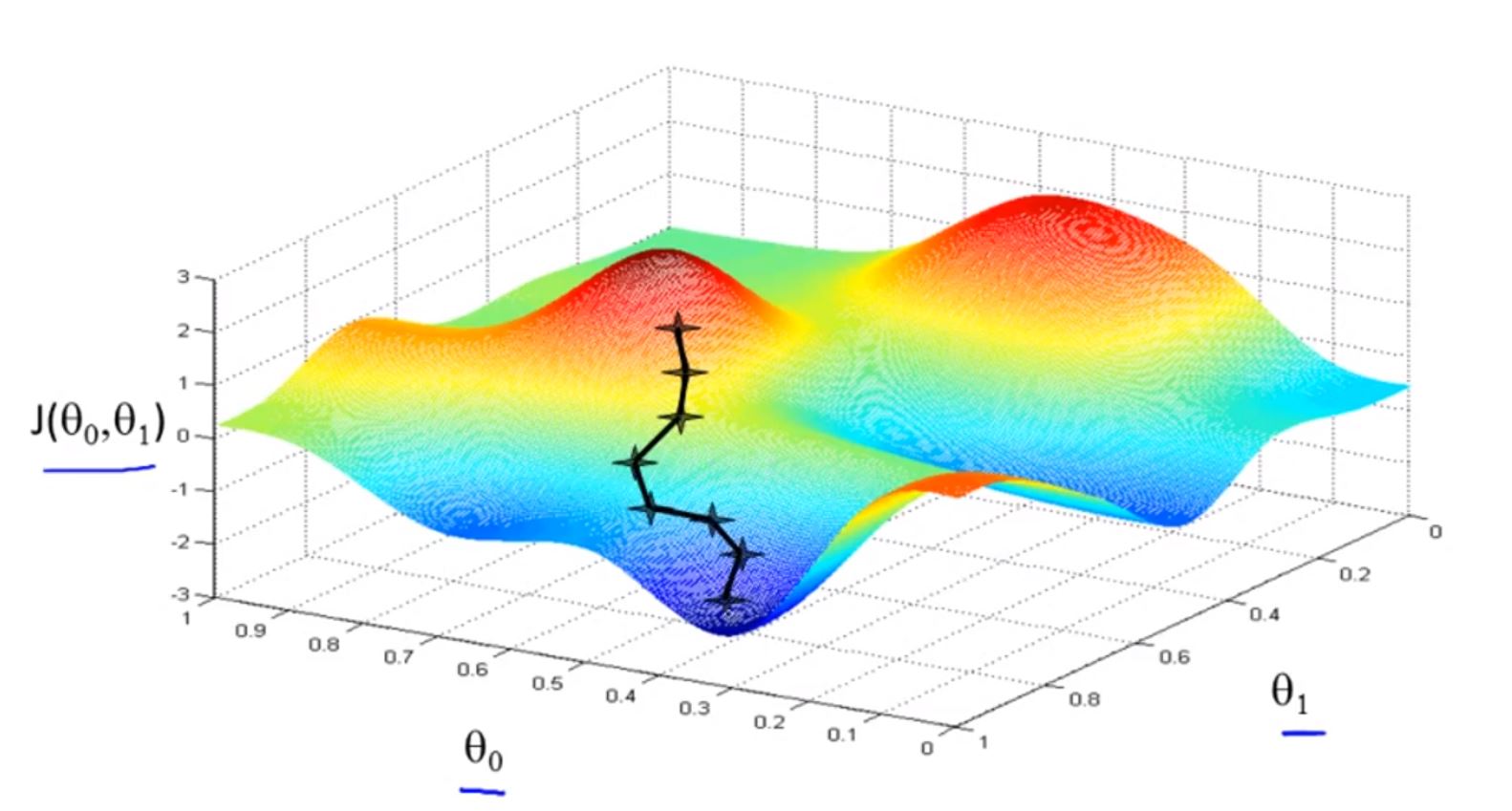
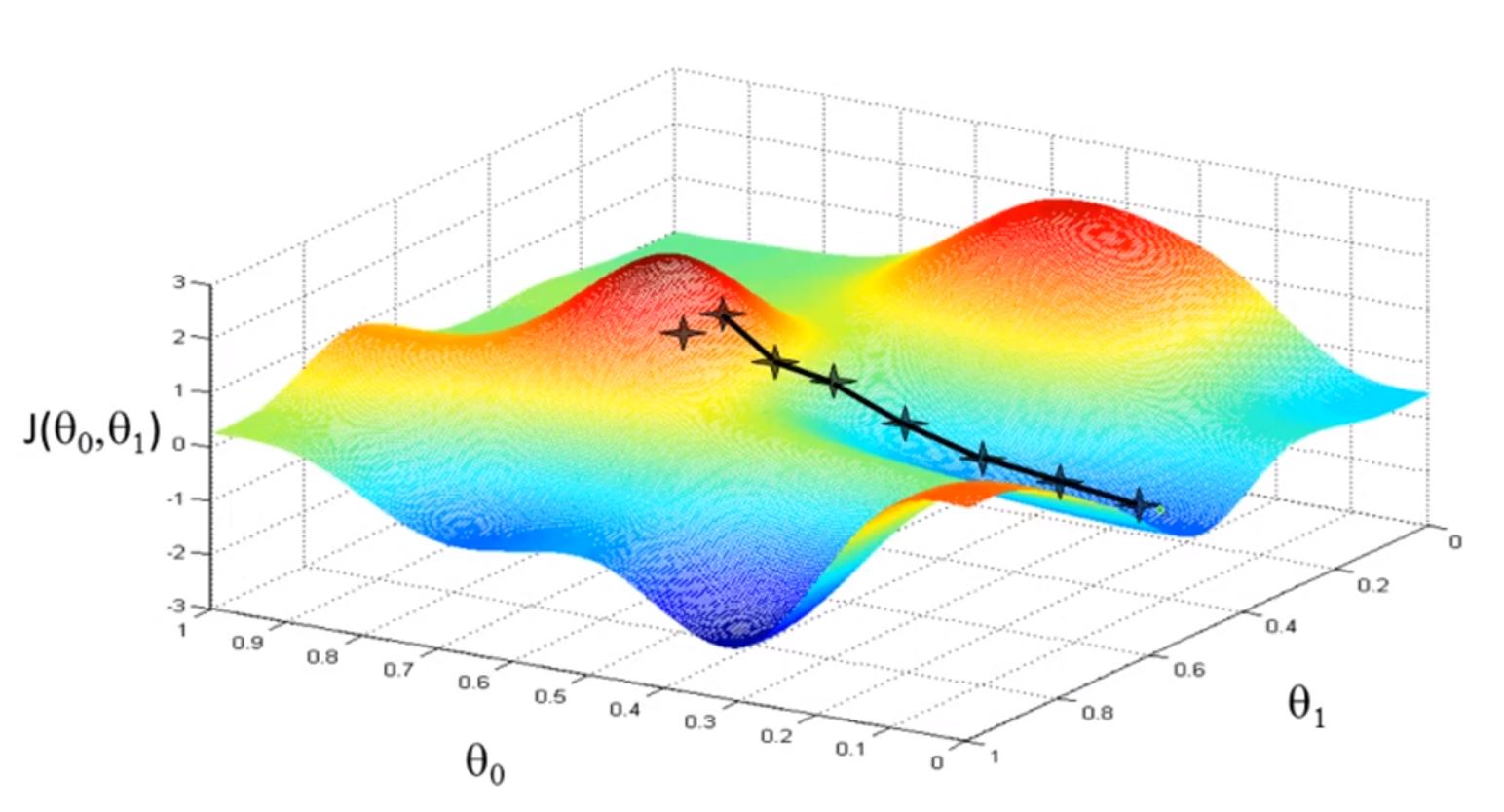
当梯度下降选择第一个图的点为初始点时,可能会沿着第一个图的路径达到局部最小;
当梯度下降选择第二个图的点为初始点时,可能会沿着第二个图的路径达到局部最小。
梯度下降算法
符号
:= 赋值运算符
α: 学习率(learning rate)(总是正数)。它的作用时控制算法的下降步长
算法定义
repeat until convergence {
\[{\theta _j}: = {\theta _j} - \alpha \frac{\partial }{{\partial {\theta _j}}}J\left( {{\theta _0},{\theta _1}} \right)\left( {for{\rm{ j = 0 and j = 1}}} \right)\]
}
重复直到收敛 {
\[{\theta _j}: = {\theta _j} - \alpha \frac{\partial }{{\partial {\theta _j}}}J\left( {{\theta _0},{\theta _1}} \right)\left( {for{\rm{ j = 0 and j = 1}}} \right)\]
}
Correct: Simultaneous update (正确的更新顺序:同步更新)
\[temp0 = {\theta _0} - \alpha \frac{\partial }{{\partial {\theta _0}}}J\left( {{\theta _0},{\theta _1}} \right)\]
\[temp1 = {\theta _1} - \alpha \frac{\partial }{{\partial {\theta _1}}}J\left( {{\theta _0},{\theta _1}} \right)\]
\[\begin{array}{l}
{\theta _0} = temp0\\
{\theta _1} = temp1
\end{array}\]
Incorrect(不正确的更新顺序):
\[temp0 = {\theta _0} - \alpha \frac{\partial }{{\partial {\theta _0}}}J\left( {{\theta _0},{\theta _1}} \right)\]
\[{\theta _0} = temp0\]
\[temp1 = {\theta _1} - \alpha \frac{\partial }{{\partial {\theta _1}}}J\left( {{\theta _0},{\theta _1}} \right)\]
\[{\theta _1} = temp1\]
为什么用这个公式更新θ?
\[{\theta _j}: = {\theta _j} - \alpha \frac{\partial }{{\partial {\theta _j}}}J\left( {{\theta _0},{\theta _1}} \right)\left( {for{\rm{ j = 0 and j = 1}}} \right)\]
首先,简化J(θ0, θ1)为J( θ1),则我们的目标是
\[\mathop {\min }\limits_{{\theta _1}} J\left( {{\theta _1}} \right)\]
更新公式是 \[{\theta _1}: = {\theta _1} - \alpha \frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
当变量只有一个的时候用"求导"(d),多个变量用“偏导”(∂)
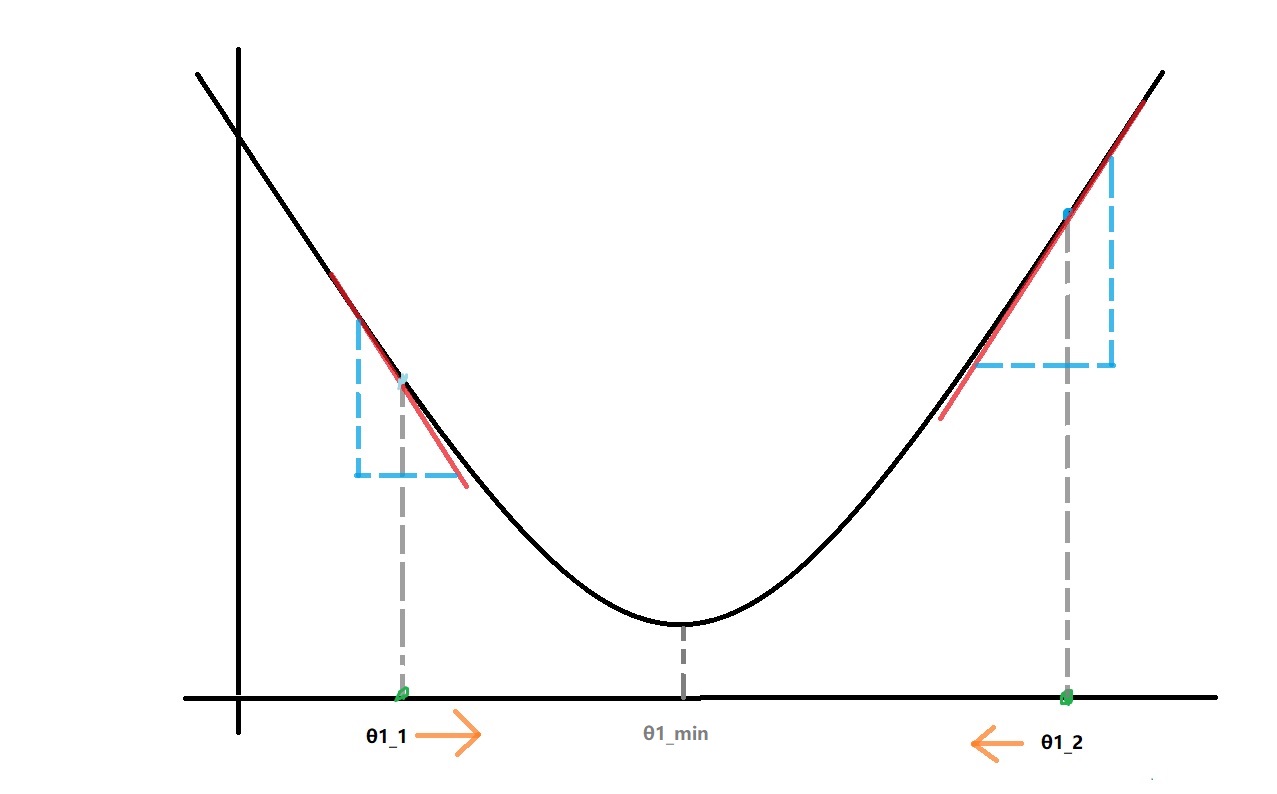
首先关注 \[\frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
当 θ1取 θ1_2时,更新公式中的 \[\frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
的结果就是:过J(θ1_2)做函数的切线的斜率值。此时这个值是正值,而α永远是正值,因此更新后的θ1会减小。
同理,当θ1取θ1_1时,更新后的会增大。
最终它们会向着局部最小的θ1_min靠近,这就会使得J( θ1)达到局部最小。
然后关注 α
当α很小的时候,会有如下情况
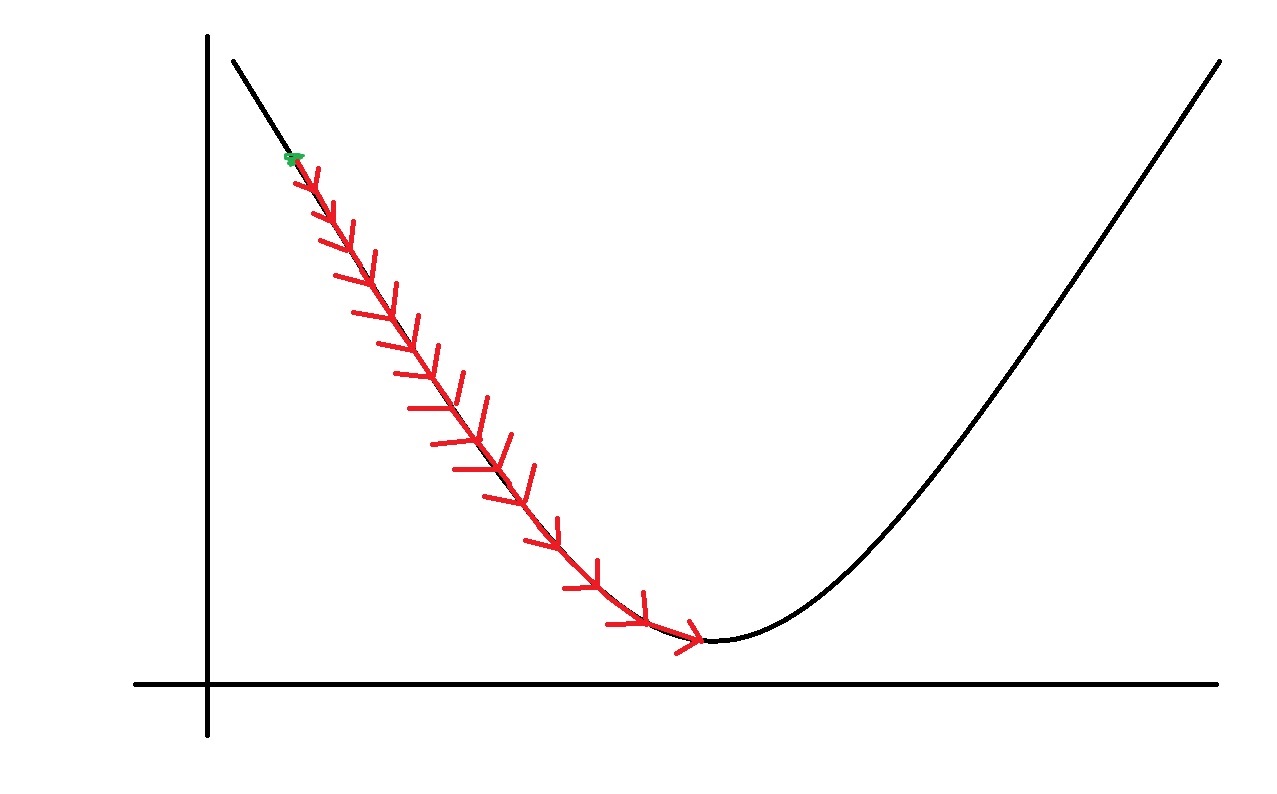
if α is too small, gradient descent can be slow
如果α很小,梯度下降会很慢
当α很大的时候,会有如下情况
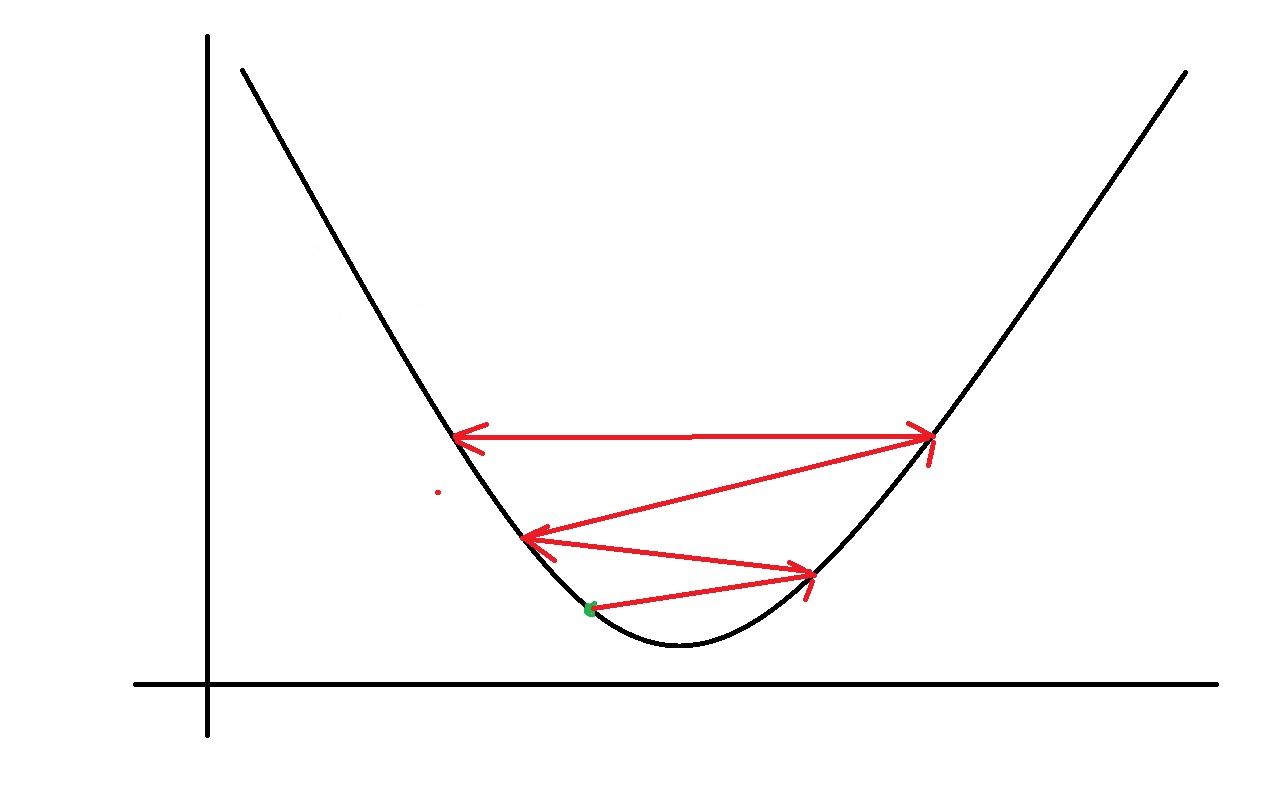
if α is too large, gradient descent can overshoot the minimum. It may fail to converge, or even diverge
如果α太大,梯度下降可能会超过最小值。 它可能无法收敛,甚至分歧
解释:为什么α固定的时候梯度下降算法仍然可以到达局部最小?
对于公式中的 \[\alpha \frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
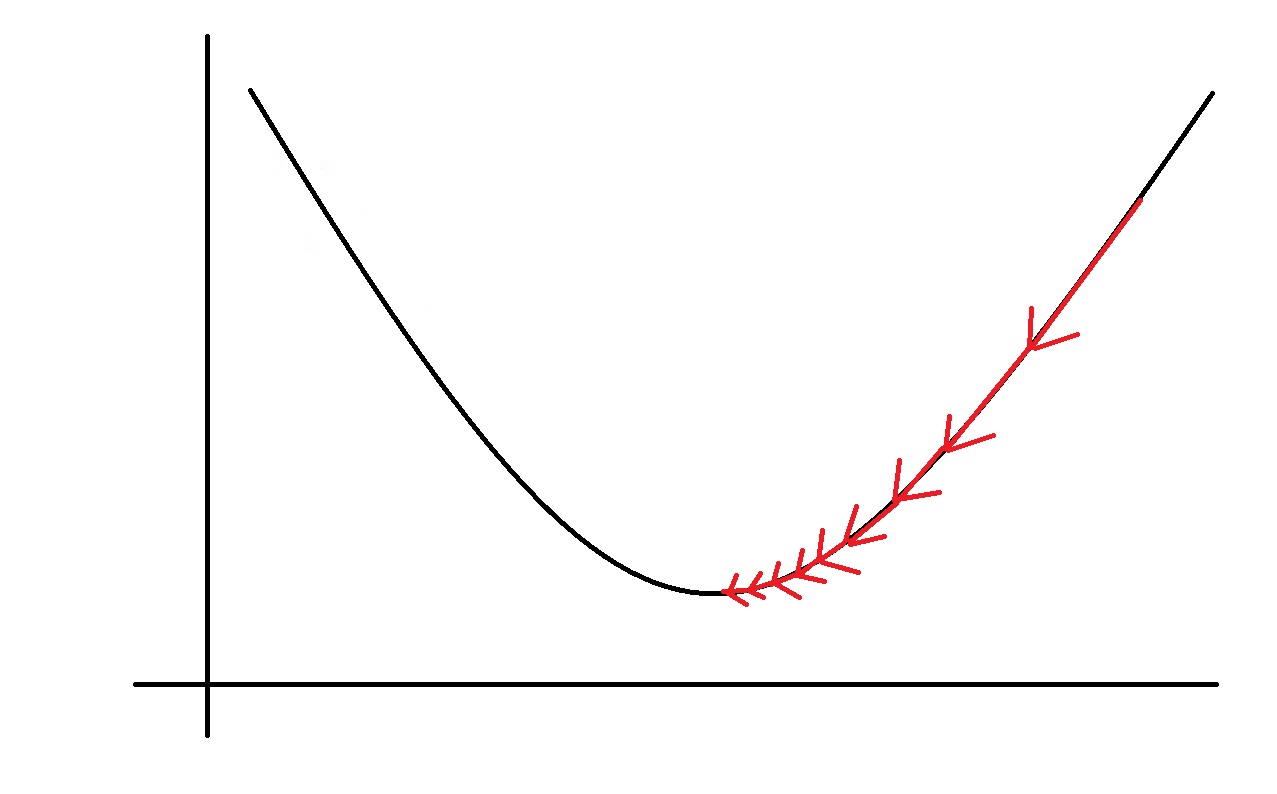
随着J(θ1)越来越靠近局部最小,公式中的 \[\frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
(也就是斜率)会越来越小,所以总的下降速度会越来越小。
As we approach a local minimum, gradient descent will automatically take smaller steps. So, no need to decrease α over time.
当我们接近局部最小值时,梯度下降将自动采取较小的步长。 所以,不需要随着时间的推移减少α。
问题:如果θ1已经位于局部最小,θ1会怎么更新?

答案是θ1保持不变,因为求导后的结果为0,也就是 \[\frac{d}{{d{\theta _1}}}J\left( {{\theta _1}} \right)\]
为0。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号