

5月4日:unordermap/set,哈希以及哈希常用的拉链法,开放地址法,以及模板的特化相关应用
Posted on 2023-05-04 23:29 玄灵镜 阅读(119) 评论(0) 收藏 举报起处较为流行的数据储存方式为树形结构,再加上红黑树等优秀数据结构的发展,直到今天二叉平衡搜索树也经常被应用在各种方面,但是c++库里面还有两个与map/set很像的容器unorderedmap,他们的调用与普通的map几乎一样,有着非常优秀的查找时间复杂度,只是不能像二叉树哪样层序遍历得到顺序的排序结果。
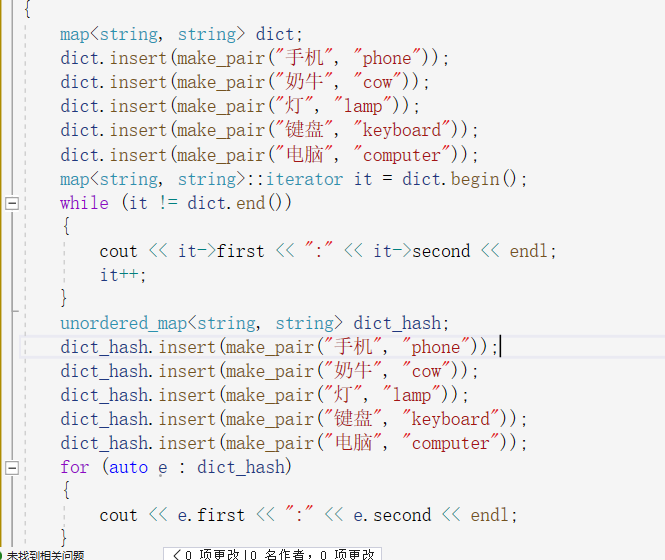
他们看着相似但是他们的底层却大不相同,unorderedmap(umap)底层为哈希表,哈希是一种映射关系。
首先提出一个问题,若将20.33.4444.5555.66666这些数字存起来,并且保证在查找时有着很优的查找时间复杂度,第一种方法就是开一个很大的数组,用下表直接访问,但是这样有着非常大的空间浪费,于是哈希中的除留余数法可以完美解决这个问题,数组中的每一个数对固定的数取余,可以得到很短的范围数据,将这几个数存入数组,当查找时也可以通过哈希映射查找。
但是因为树有很多但是格子就那么多,肯定免不了空间冲突,这是又有两种方法解决冲突:
1:开放地址法:这种方法时当发现取余数·后余数的位置已经有数据,于是可以向后检测,若后面的空间有空可以将数据放进去。这样就解决了冲突。
其中开放地址发包括开放地址发和二次探测法。
2:拉链法:数组中每个位置存放一个链地址,每次发生冲突时,将数据连在后面,这样也就解决了冲突。
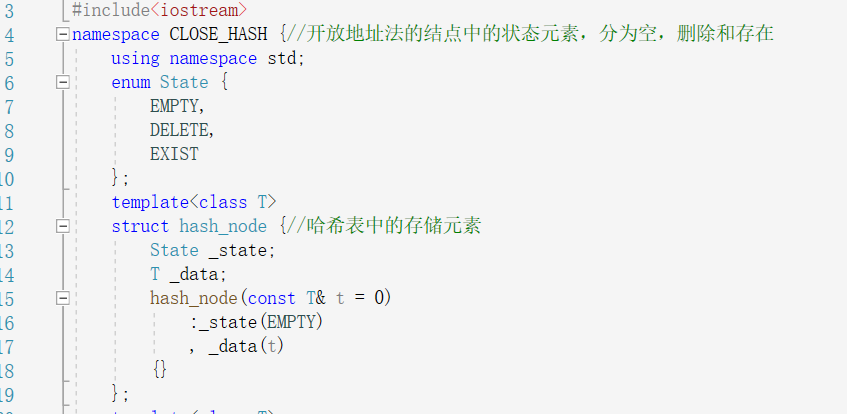
实现哈希表:
首先是闭散列的开放地址法/链地址法:
1:大概架构:unordermap与map很像也是一个容器适配器,通过对容器中的容器修饰达到插入删除查找的目的,其中可以有开散列和闭散列两种选择,开散列就是利用vector容器存数据,用开放地址法解决冲突。闭散列也是用vector容器作为主要结构,其中vector中的数据类型是一个链式的结点,方便用链地址法解决冲突,这个也叫哈希桶。
首先定义一个vector作为map类的类成员变量,vector中存储要放的数据,
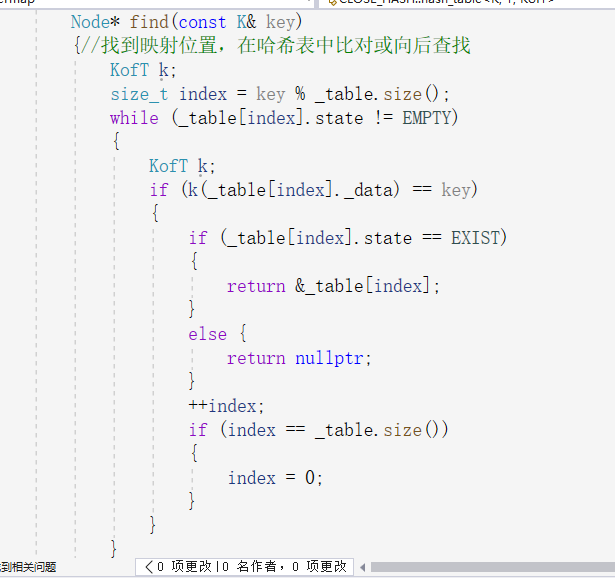
首先是往哈希表中插入数据,先得到数据的key值并且对其取余数,得到哈希表中下标的位置,并且检测此位置是否为空,不为空则向后探测,若探测到末尾,令index等于零,继续探测,不可能存在放不下的情况,因为哈希表本就是开了很大的空间,且再负载因子达到0.7左右时开始增容。要注意的是在插入时探测到与插入是key相同的值时返回插入失败,因为其性质与二叉搜索树一样,key值不能重复。
tips:插入时首先要检查负载因子是否达到增容的标准,若达到了进行增容,哈希表的增容与普通表的增容不一样,若只是普通的开辟空间,那么已有的表中数据就会不准确,所以需要重新将原表中的数据重新插入,因此哈希表的增容代价非常大,需要谨慎增容,增容的一般思路是另起一个vector将数据意义挪入新表中,如下图:

但是还有一种对人来说比较轻松的写法,就是直接开一个新的哈希表,对新表直接开辟足够的空间,调用已经实现的插入函数一一插入,然后将新表中的vector与旧表中的互换,因为新表是临时变量所以出了作用域会自动析构。所以对人来说很省事。

插入函数到此为止:

然后是查找函数:
一样的思路找到key取余的值,定位到表中,若数值不匹配则继续往后找,因为可能被开放地址放到后面了,一旦遇到空就就结束,但是又有一个问题,若是数据被删除了,就不能确定这个地方曾将有没有过数据,可能曾经有过被删除了,但是被删除之前开放地址到后面去了,就会出错,。但是有一个很巧妙的解决方法,就是给每个数据加一个状态分别是删除,存在和空,这样在遇到空时直接结束,遇到存在和删除时继续向后探测。于是vector中的数据类型就变成了这样:一个有枚举类型构成的状态,和数据本身,
然后就是一如既往的查找步骤,探测到vector末尾时将index置为一。继续探测,直到找到,或者为空。
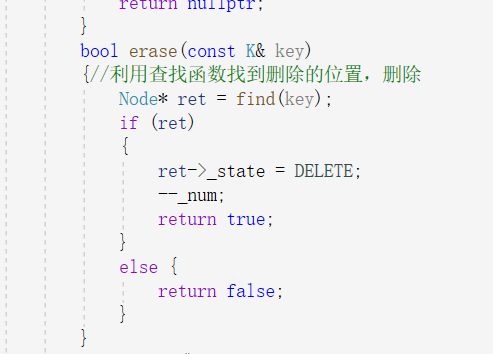
最后是删除:时最简便的:利用已经实现的查找函数找到位置将此位置的状态置为删除即可。
因为哈希表可能别map或者set复用所以数据类型应该用模板的范式编程。加入一个仿函数参数控制key的读取,若数据类型为map的pair则仿函数返回pair中的first若为set则返回本身。

开放地址法就这些,接下来主要实现哈希桶,然后复用哈希桶用实现unorderedmap
大致思路:首先用模板的范式编程实现闭散列的链地址法,在实现的过程中给这个哈希桶预留仿函数模板参数位,为后来的复用做准备。
首先定义一个vector作为类成员变量,然后定义一个struct公共类单链式结点作为vector的数据类型。struct中有一个指向像一个结点的指针变量,和要存储的数据。

首先是插入函数:
老方法用除留余数法得到vector中的位置,将此位置赋给一个临时变量,用while迭代这个临时变量检查数据是否重复,然后插入,

然后是查找:还是老方法,找到位置返回这个结点,没找到返回空;

最后时删除:这个删除和之前的开散列不一样不可以用find函数直接找到删除,因为这里是单向链表,需要保留前一个结点来保存数据然后删除
tips:这里若删除的节点是第一个结点,就需要单独处理,+_table[i}直接指向下一个然后释放空间。

储存结构时不能没有遍历函数的。然而遍历函数又少不了迭代器所以接下来是迭代器的实现:
与之前红黑树相差不多,先弄一个begin函数返回哈希表中的第一个不为空的数据。然后是end返回一个空指针构造的迭代器,
定义一个迭代器类型,里面存放结点指针,重载解引用运算符和指针访问变量箭头运算符,和不等运算符,以及自增运算符,
比较重要的是自增运算符,这个比价麻烦,因为当vector中一个结点访问完后需要vector向后移动一位,然而迭代器只有当前节点的数据,并不能访问到整个哈希表,这个比较难处理了,于是往迭代器中需要多传一个哈希表的指针,typedef哈希表,将此指针放入迭代器的类成员变量,于是当哈希表中一个链访问到底时,可以通过迭代器中的哈希表,得到下一个链的位置,这里有一个要注意的点,就是,迭代器并没有访问哈希表中私有类成员变量的权限,所以要在哈希表中给迭代器申请一个友元的权限:

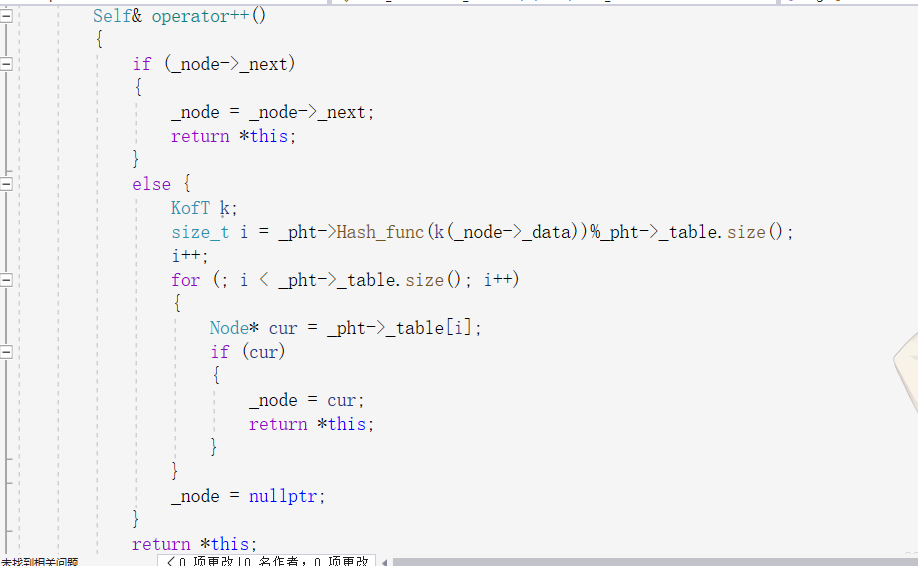
闭散列的哈希表的主要功能就差不多了除了重载方括号运算符:
unordermap的底层主要时哈希表实现的,主要是复用哈希表的容器;大概架构就是容器套用容器起到一个适配器的作用,有些差异可以用模板和仿函数以及模板的特化处理差异。

由上图可以看到哈希表中有四个模板参数:第一个作为key——value类型中的K主要作用在查找函数里作为传入的一个参数用来找到v,第二个参数就是map中的键值对了,是主要存储的数据,第三个参数是根据适配不同的容器实现不同的仿函数,如下:

可以看到map中将此函数实现成为了取到键值对中的键,因为map需要取到键值对中的键来进行比较访问,因为而擦函数中的key不可以修改,所以这里的key也是用常量来修饰的,前三个模板参数在实现底层为红黑树的map是也都用过但是第四个模板参数就是哈希因为独有的结构来实现的了,因为哈希表需要用到楚留余数法操作key来得到数据在哈希表中的映射位置,但是并不是所有的key都是支撑取余的整形数据,比如字典,他可能键值对中所有的数据都是字符串,这里就不能用除留余数法来取余,就需要将字符串转化为整形数据使其满足取余的条件,但是也不能忽略本来就是整形是的默认条件,这个仿函数参数就是为此做准备的,需要用到字符串类型取余时,传入写好的字符串仿函数,需要用到整形时用整形,但是这很繁琐,不想stl库里面map无论是字符串还是数字都可以处理,不需要传入多余的仿函数控制,这个不像优先级队列那样需要根据需求多传一个参数调整大小优先级,所以特化可以解决这个问题,先对这个模板给一个缺省值为默认的整形,人后给这个整形进行同名特化,就可以自动识别字符串和数字了,就像下图所示
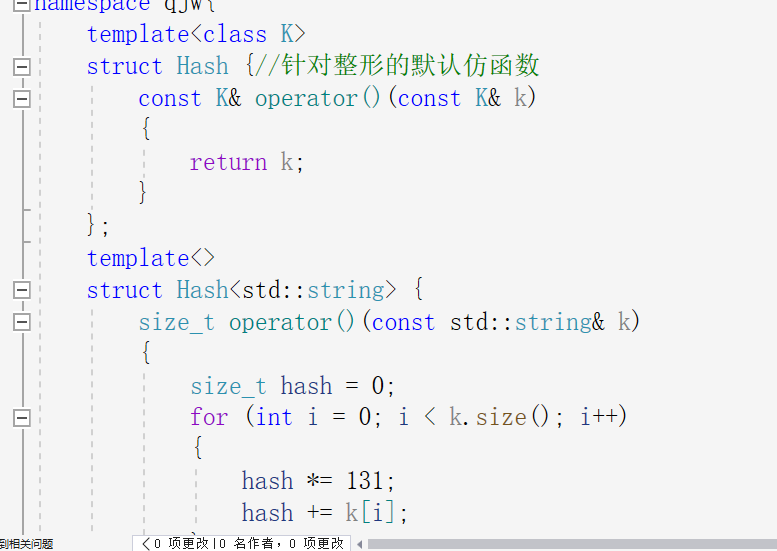

tips:在转字符串时可以将字符串的每一个ascii码值加起来,这样有一个缺点,可能会不同的字符串有相同的key,于是有些大佬用数学给个一个比较优的优化方式,每次相加后*131,可以避免key相同的同时优化速率。
最后就是重载方括号运算符:
方括号运算符传入一个key若容器类没有寻找到这个key就将其插入,并返回这个键值对的value,若找到了也返回这个键值对的value,所以由现象可以得知重载[]肯定涉及到了插入,其实要满足这个就得稍微修改之前的插入函数,使插入函数的返回值为一个pair类型的变量,其中ky1是一个迭代器,就是当前位置的迭代器,是插入失败时的结点或者插入成功时的位置结点迭代器,second是一个布尔值返回插入成功或者失败,然后在重载【】时用一个pair值接受insert的返回值,再将接收到的结果的value返回如此重载【】就完成了


最后就是测试成果:
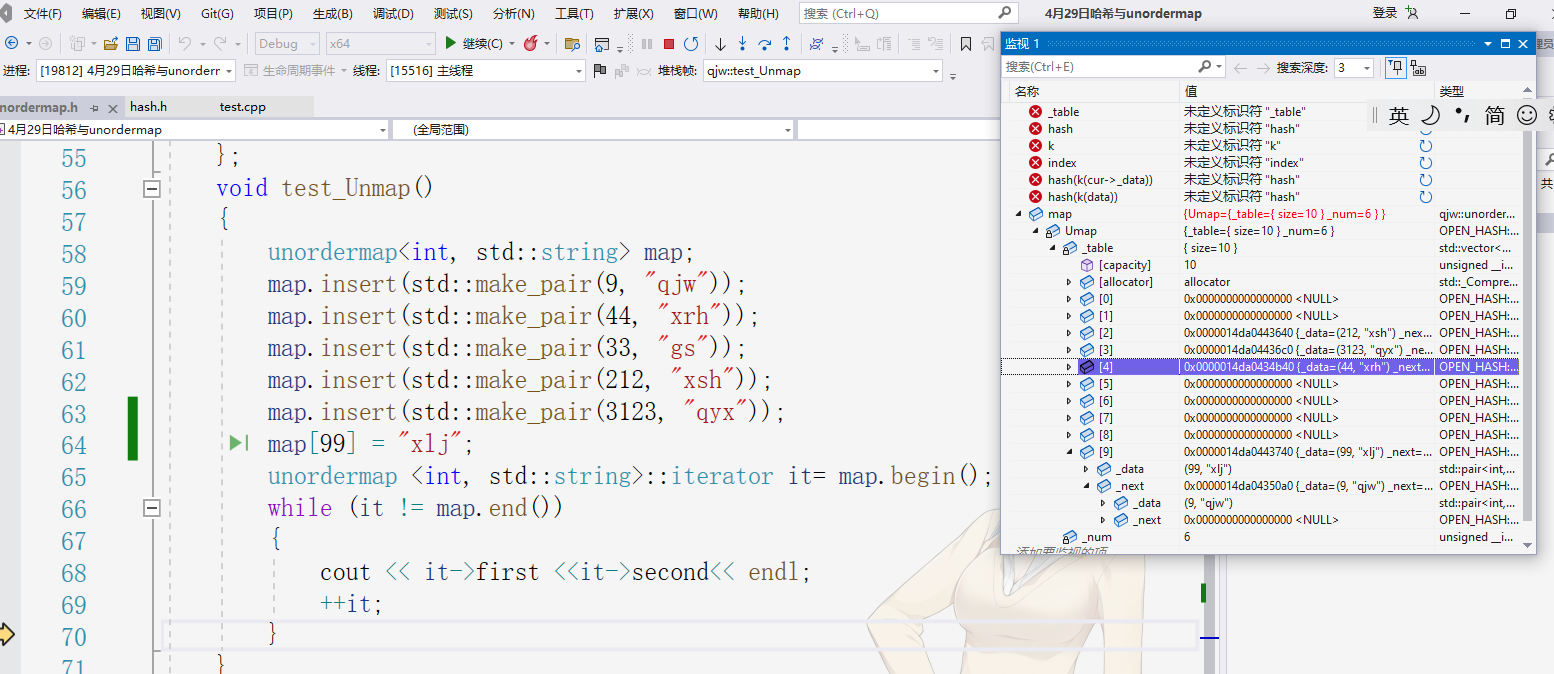
从调试窗口可以看出测试成功
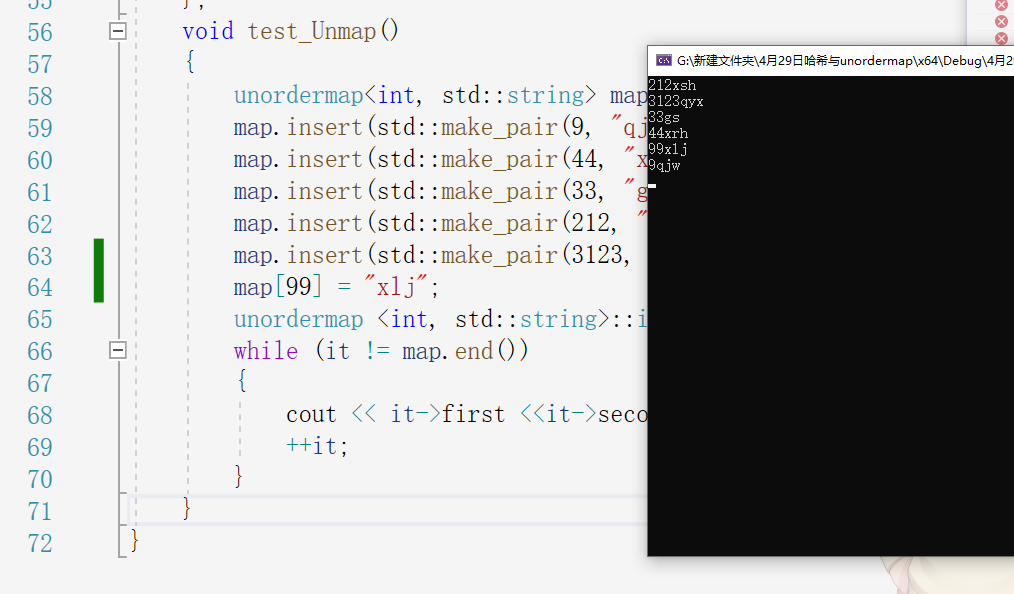
迭代器也输出正常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号