

python基础入门---字符编码转换
UTF-8:Unicode TransformationFormat-8bit,允许含BOM,但通常不含BOM。是用以解决国际上字符的一种多字节编码,它对英文使用8位(即一个字节),中文使用24为(三个字节)来编码。UTF-8包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8编码的文字可以在各国支持UTF8字符集的浏览器上显示。如,如果是UTF8编码,则在外国人的英文IE上也能显示中文,他们无需下载IE的中文语言支持包。
GBK:是国家标准GB2312基础上扩容后兼容GB2312的标准。GBK的文字编码是用双字节来表示的,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1。GBK包含全部中文字符,是国家编码,通用性比UTF8差,不过UTF8占用的数据库比GBD大。
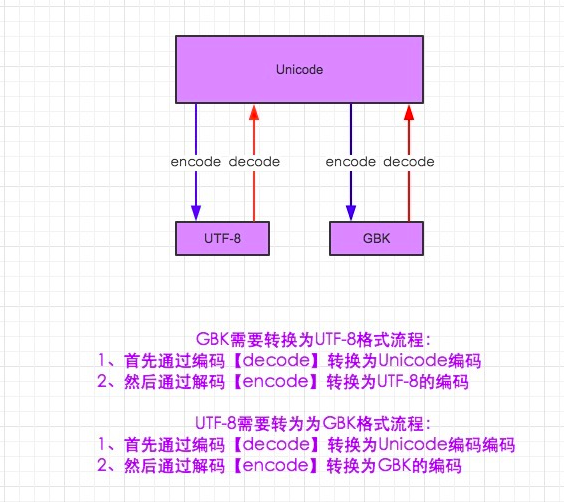
GBK、GB2312等与UTF8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
import sys
print(sys.getdefaultencoding())#默认是utf-8
s = "你好"
s_gbk = s.encode("gbk")
print(s_gbk)
print(s.encode())
gbk_to_utf8 = s_gbk.decode("gbk").encode("utf-8")
print("utf8",gbk_to_utf8)
结果显示:
utf-8
b'\xc4\xe3\xba\xc3'
b'\xe4\xbd\xa0\xe5\xa5\xbd'
utf8 b'\xe4\xbd\xa0\xe5\xa5\xbd'
#-*-coding:gb2312 -*-
import sys
print(sys.getdefaultencoding())
msg = "武汉加油,中国加油"
#msg_gb2312 = msg.decode("utf-8").encode("gb2312")
msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
gb2312_to_unicode = msg_gb2312.decode("gb2312")
gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8")
print(msg)
print(msg_gb2312)
print(gb2312_to_unicode)
print(gb2312_to_utf8)
结果显示:
utf-8
武汉加油,中国加油
b'\xce\xe4\xba\xba\xbc\xd3\xd3\xcd\xa3\xac\xd6\xd0\xb9\xfa\xbc\xd3\xd3\xcd'
武汉加油,中国加油
b'\xe6\xad\xa6\xe6\xb1\x89\xe5\x8a\xa0\xe6\xb2\xb9\xef\xbc\x8c\xe4\xb8\xad\xe5\x9b\xbd\xe5\x8a\xa0\xe6\xb2\xb9'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号