配置Spark
参考《深入理解Spark:核心思想与源码分析》
Spark使用Scala进行编写,而Scala又是基于JVM运行,所以需要先安装JDK,这个不再赘述。
1.安装Scala
安装获取Scala:
wget http://download.typesafe.com/scala/2.11.5/scala-2.11.5.tgz
将下载的文件移动到自家想要放置的目录。
修改压缩文件的权限为755(所有者读写执行,同组成员读和执行,其他成员读和执行)
chmod 755 scala-2.11.5.tgz
解压缩:
tar -xzvf scala-2.11.5.tgz
打开/etc/profile,添加scala的环境变量
vim /etc/profile

查看scala是否安装成功:
scala

2.安装完scala后,就要安装spark了
只接从网站上下载了spark安装包:
http://spark.apache.org/downloads.html
将安装包移动到自己指定的位置,解压缩。
配置环境变量:
vim /etc/profile
添加spark环境变量

使环境变量生效:
source /etc/profile
进入spark的conf文件目录,
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/conf cp spark-env.sh.template spark-env.sh
在spark-env.sh目录中添加java hadoop scala的环境变量

启动spark:
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/sbin ./start-all.sh
打开浏览器,输入http://localhost:8080
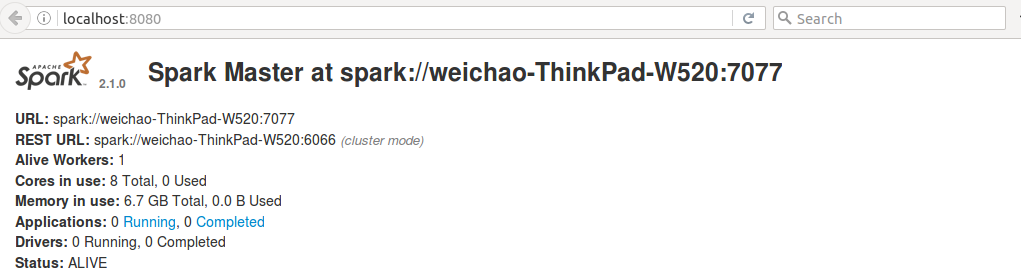
可见Spark已经运行了。
http://blog.csdn.net/wuliu_forever/article/details/52605198这个博客写的很好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号