高性能集群系统slurm使用简易记录
校园或企业的高性能算力集群通常使用SLURM作业调度系统来统一实现用户作业的提交、查看、修改等操作。以下记录SLURM系统中作业提交脚本与命令的使用。
常用命令
首先介绍常用命令:
squeue # 查看用户当前执行的作业 sinfo # 查看集群中所有算力分区的情况 sacct # 查看24小时内的历史任务 scancel [id] # 取消相应id的任务 scontrol show node # 列举所有节点信息 scontrol show node [node_name] # 显示某个节点的信息
其中,一个节点可以简单理解为一台机器;通常用户登录集群slurm系统后,默认在登录节点。一个算力分区可以简单理解为将多个有相似功能的节点划分为一组,从而便于识别和管理。
作业提交
当用户要运行一个程序,需编写相应的作业脚本来指定程序运行所需的硬件资源。以下展示了一个作业脚本demo,命名为test.job:
#!/bin/bash #SBATCH --job-name=Helloworld ##作业的名称 #SBATCH --ntasks=1 ##总进程数,就是同样的作业要一起跑几个,一般炼丹一个就行了 #SBATCH --nodes=1 ##指定节点数量,一个进程只能分配给一个节点,不能分配给多节点多CPU运行 #SBATCH --ntasks-per-node=1 ##每个结点的进程数,一个进程那么每个结点进程数一定是1,不填也没事 #SBATCH --cpus-per-task=2 ##每个进程使用的CPU核心数,炼丹当然是越多越好,但是要的多分配的也慢 #SBATCH --partition=low ##使用哪个分区,可以sinfo看看有哪些分区 ##SBATCH --gres=gpu:1 ##指定GPU,不写就不分配。要用的话,注意把注释##改为# ##SBATCH --nodelist=node56 ##使用指定的节点,自己指定的话通常优先度会高一些,缺点就是即使别的节点空闲了也不会分配给你。当然节点要在上面指定的分区内部才行 #SBATCH --output=test.out ##标准输出的存放的文件,可以用%j表示任务ID #SBATCH --error=test.err ##错误提示的存放的文件 #SBATCH --qos=debug ##服务质量,debug就是交互式模式,分配资源少些,但是优先度高,另外还有normal普通模式,资源多但优先度低 source /public/home/chenqz/.bashrc ##要用软件的环境变量 python3 test.py ##要执行的任务,看你终端所在的位置,如果已经在任务的文件夹中就不需要完整路径了,上面的123.out和.err也一样,都是输出到这一位置。
通过sbatch命令提交作业脚本,slurm将为程序动态分配硬件资源,并运行相应程序:
sbatch test.job
如果作业提交了想更改作业属性,当作业还没开始时(比如在排队),可以这样修改:
scontrol update jobid=56407 cpus-per-task=8 gres=gpu:1
交互式计算
可使用salloc申请算力节点,slurm系统会为用户在相应节点分配独占的硬件资源。之后即可进入申请的算力节点,利用命令行的方式运行交互式代码。salloc命令demo如下:
salloc -J GoodJob -N 1 --cpus-per-task=8 -p low --qos=normal
各种参数格式如下(和上面的任务提交脚本类似,就是少了#SBATCH):
-J <任务名> #--job-name=<任务名> 的简写,下面一条-的都是简写,而且不用= -N <节点数量> #炼丹一般也就一个节点 --ntasks=<进程数> #炼丹就不需要了定义了,默认一个进程就够了 --ntasks-per-node=<单节点进程数> #一个进程的话也不需要定义这个了 --cpus-per-task=<单进程CPU核心数> --gres=gpu:<单节点 GPU 卡数> -p <使用的分区> --qos=<使用的 QoS>
申请后的资源也是以作业的形式占用,可squeue查看:

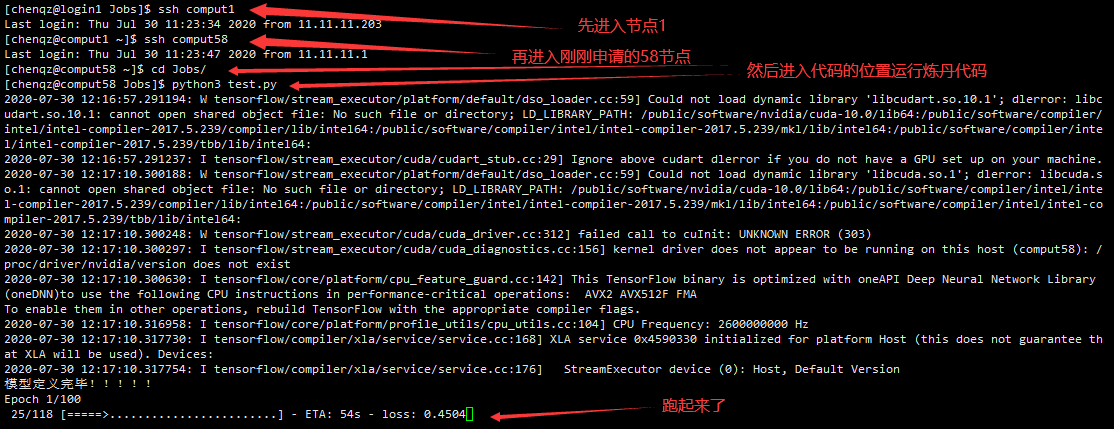
看到申请的节点是58,然后进入这个节点,运行代码:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号