信息熵、相对熵(KL散度)、交叉熵、条件熵、互信息、联合熵
下面介绍的各种熵尽管都与数据分布的混乱度相关,但是建议把相对熵(KL散度)和交叉熵单独拿出来理解。交叉熵和相对熵是针对同一个随机变量,它们是机器学习里额外定义的用来评估两个分布差异的方式,无法用韦恩图进行观察;而后面的条件熵等则是针对不同的随机变量之间的关系(可以看完本文再回来看这句话)。
信息熵
信息量和信息熵的概念最早是出现在通信理论中的,其概念最早是由信息论鼻祖香农在其经典著作《A Mathematical Theory of Communication》中提出的。如今,这些概念不仅仅是通信领域中的基础概念,也被广泛的应用到了其他的领域中,比如机器学习。
信息量用来度量一个信息的多少。和人们主观认识的信息的多少有些不同,这里信息的多少用信息的在一个语境中出现的概率来定义,并且和获取者对它的了解程度相关,概率越大认为它的信息量越小,概率越小认为它的信息量越大。用以下式子定义:
$I(x) = -\log p(x)$
信息熵用来描述一个信源的不确定度,也是信源的信息量期望。它实际上是对这个信源信号进行编码的理论上的平均最小比特数(底数为2时)。
式子定义如下(log 的底数可以取2、e等不同的值,只要底数相同,一般是用于相对而言的比较):
$\begin{aligned}H(X) &= E_{x\sim X}[I(x)]\\ &= E_{x\sim X}[-\log p(x)] \displaystyle \\&= -\sum\limits_{x\in X}[p(x)\log p(x)]\end{aligned}$
《Deep Learning》的解释是:它给出了对依据概率分布P生成的符号进行编码所需的比特数在平均意义上的下界。
我的理解:信息(符号)出现概率越高,编码理应给它少一些比特数,和有较低的信息量相符合(由上面的信息量式子算出)。信息出现概率越低,编码时可以把它的优先级放后一些,也就是给它分配更长一些的码,和有较高的信息量相符合。反应了人对信息进行编码的长度和信息的信息量是成正相关的,因为它符合这样一个事实:概率低→定义信息量高,概率低→定义编码长度长。所以信息的信息量就可以在一定程度上度量信息需要编码的长度,信源分布的信息量期望(信息熵)也就度量了一个信源平均需要的编码长度。
当然能发出信号的信源只是信息的一个语境而已。信息熵可以在很多语境下定义。
比如:一篇文章的字母的信息熵,那语境$X$就是在这篇文章下的所有字母,$x$就是每个字母,$p(x)$就是每个字母在这篇文章(而不是整个英语体系中每个字母的频率)中出现的频率。
又比如:小王在盒子里放了一个红球。小明知道盒子里的球色可能是红、黑、蓝三者之一,小红知道盒子里的球色是红、黑二者之一。那小明在这个游戏中所知道的信息的信息熵的语境$X$就是这三种可能性,得$H(X) = 1.584$(以2为底)。同理,小红是二种可能性,得$H(X) = 1.0$。如果这时候小王告诉他们:盒子里放的不是黑球。对于小明来说,可能性变成了二种,$H(X) = 1.0$,和之前相比信息熵减少了,获得的信息量就是$1.584 - 1.0 = 0.584$。而对于小红,$H(X)$变为了0,获得信息量就是1.0。
值得一提的是,这里将信息熵与信息量概念连接了起来。实际上,系统信息熵的熵减(信息熵减少的大小)就是这个系统获得的信息量。
另外,接近确定的分布有较低的熵;接近均匀分布的概率分布有较高的熵。如图:
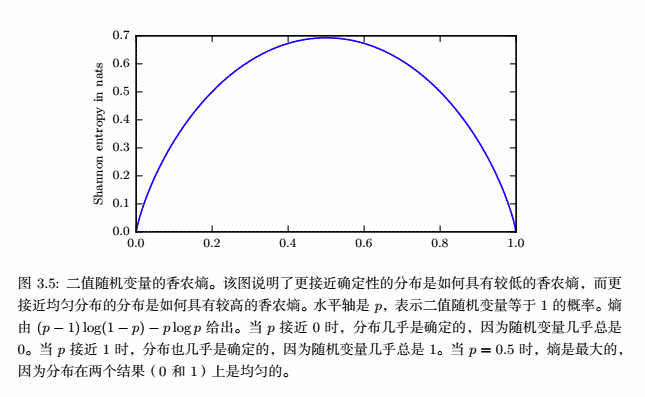
可以看出,在信源中出现的消息的种数一定时,这些消息出现的概率全都相等时,有信源的信息熵最大。推出信息熵的范围:
$\displaystyle 0\le H(X) \le -\sum\limits^{n}\frac{1}{n}\log(\frac{1}{n}) = \log(n)$,$n$是不同信息数
请注意!本文主要针对离散随机变量场景下的信息熵,连续随机变量对应微分熵,理解有所不同。尽管微分熵也是类似将求和替换为积分进行计算,但计算结果可能是负数。
微分熵举例
对于在$[a,b]$上的均匀分布,有微分熵:
$\displaystyle \int_a^b\frac{1}{b-a}\log(b-a)dx = \log(b-a)$
当$b-a\leq1$时,有微分熵小于等于0。对于正态分布$\mathcal{N}(\mu;\sigma)$,有微分熵:
\begin{align*} &\int_{-\infty}^\infty -\frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}} \ln\left(\frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}}\right) dx\\ =& \int_{-\infty}^\infty -\frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}} \left(-\ln\left(\sqrt{2\pi}\sigma\right) - \frac{x^2}{2\sigma^2}\right) dx \\ =& \ln(\sqrt{2\pi}\sigma) \int_{-\infty}^\infty \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}} dx + \int_{-\infty}^\infty \frac{1}{\sqrt{2\pi}\sigma} e^{-\frac{x^2}{2\sigma^2}} \frac{x^2}{2\sigma^2} dx\\ =& \ln(\sqrt{2\pi}\sigma)+\frac{1}{2} \;\; (第一项概率密度积分为1,第二项计算E(X^2)得到)\\ =& \frac{1}{2}\ln 2\pi e\sigma^2 \\ \end{align*}
相对熵(KL散度)
相对熵原本在信息论中度量两个信源的信号信息量的分布差异。
而在机器学习中直接把其中的信息量等概念忽略了,当做损失函数,用于比较真实和预测分布之间的差异。我感觉用别的式子来比较分布之间的差异也行,因为损失函数的目的只是为了减小模型预测分布和真实分布的差异而已。只要符合分布差异越大,函数值越大的式子应该都行。
定义
式子定义如下(这里用期望的形式定义,底数用e):
$\displaystyle D_{KL}(P||Q) = E_{x\sim P}[\log \frac{P(x)}{Q(x)}] = E_{x\sim P}[\log P(x) - \log Q(x)]$
《Deep Learning》中的解释是:KL散度衡量的是,当我们用一种能使概率分布Q产生的消息的长度最小的编码,发送由分布P产生的消息时,所需要的额外信息量。
我的理解:
1、用使得P分布产生的消息长度最小的编码,来发送P分布产生的消息时。对于某个符号$x$,它的编码的信息量是$-\log P(x)$,它的概率是$P(x)$,则P分布平均每个符号要编码的信息量就是$\sum\limits_{x\in P}[-P(x)\log P(x)] = H(P)$,就是P分布的信息熵。
2、用使得Q分布产生的消息长度最小的编码,来发送P分布产生的消息时。对于某个符号$x$,它的编码的信息量是$-\log Q(x)$,它的概率是$P(x)$,则P分布平均每个符号要编码的信息量就是$\sum\limits_{x\in P}[-P(x)\log Q(x)] = H(P, Q)$,实际上是P和Q的交叉熵(后面提到)。
3、那么额外信息量就是2和1之差了,所以有:
$\begin{aligned}\displaystyle D_{KL}(P||Q) &= \sum\limits_{x\in P}[-P(x)\log Q(x)] - \sum\limits_{x\in P}[-P(x)\log P(x)]\\&= E_{x\sim P}[\log P(x) - \log Q(x)] \\&= E_{x\sim P}[\log \frac{P(x)}{Q(x)}] \end{aligned}$
显然当两个分布相同时,它们的KL散度为0.
非对称
KL散度不是一个对称量,即对于某些$P$和$Q$:$D_{KL}(P||Q) \not= D_{KL}(Q||P)$。所以使用它们来做损失函数,最小化后的效果是不一样的。
如下是《Deep Learning》中,使用$D_{KL}(P||Q)$ 和 $D_{KL}(Q||P)$最小化后拟合真实分布的比较图:

直观理解上图(其实下面的理解是错的2020年10月12日,但我还是想不出实际原因,先不删了):
1、对于$D_{KL}(p||q)$,因为优化的分布是$q$而:
$\displaystyle D_{KL}(p||q) = \sum\limits_{x\in p}[-p(x)\log q(x)] - \sum\limits_{x\in p}[-p(x)\log p(x)]$
其中后一项不变化,所以$q$需要尽可能地靠近$p$,就产生了一个平均,得到左图。
2、对于$D_{KL}(q||p)$,因为优化的分布是$q$而:
$\displaystyle D_{KL}(q||p) = \sum\limits_{x\in q}[-q(x)\log p(x)] - \sum\limits_{x\in q}[-q(x)\log q(x)]$
其中后一项会变化,所以$q$不但需要尽可能地靠近$p$,而且$q$分布的交叉熵也要尽可能地小,就使得$q$分布更加不平均(概率尽可能集中到一点),得到右图。
非负
由Jenson不等式可证明KL散度非负。在KL散度中,由于$-\log (x)$是严格下凸函数,且$\int p(x)dx = 1, \int q(x)dx = 1$,所以有:
\begin{aligned} D_{KL}(p||q) &= - \int p(x)\log \frac{q(x)}{p(x)}dx\\ &\leq -\log\int p(x)\frac{q(x)}{p(x)}dx\\ &= -\log\int q(x)dx = - \log 1 = 0 \end{aligned}
JS散度
JS散度同样度量两个概率分布的相似度,是基于KL散度的变体,解决了KL散度非对称的问题。JS散度是对称的,取值是0到1之间。定义如下:
$\displaystyle D_{JS}(P_1||P_2) = \frac{1}{2}D_{KL}(P_1||\frac{P_1+P_2}{2}) + \frac{1}{2}D_{KL}(P_2||\frac{P_1+P_2}{2}) $
交叉熵
如上面提到过,交叉熵式子定义:
$H(P, Q) = -E_{x\sim P(x)}\log Q(x)$
由上面可知,假如$P$是真实分布,当使用$D_{KL}(P||Q)$作为损失函数时,因为只含$P$的那一项并不会随着拟合分布$Q$的改变而改变。所以这时候损失函数可以使用$H(P, Q)$来代替简化。
另外,由于$H(P, Q) = D_{KL}(P||Q) + H(P)$,可看出$H(P, Q)$非负且比$H(P)$大。
条件熵
为了便于表达,和前面的交叉熵、相对熵等不太一样,条件熵$H(Y|X)$中的$X$和$Y$并不是分布,而是随机变量。$H(Y|X)$表示在已知随机变量 $X$的条件下随机变量 $Y$的不确定性。注意,这里的$X$并不是某个确定值,而是随机变量,所以在计算熵的时候要对所有$H(Y|X=x)$进行求和。所以条件熵定义如下:
$\begin{aligned}H(Y|X)&=\displaystyle\sum\limits_{x}P(X=x)H(Y|X=x)\\ &=\sum\limits_{x} P(X=x)\sum\limits_{y}P(Y=y|X=x)\log \frac{1}{P(Y=y|X=x)}\\ &=-\sum\limits_{x} \sum\limits_{y}P(X=x)P(Y=y|X=x)\log P(Y=y|X=x)\\ &=- \sum\limits_{x,y}P(Y=y,X=x)\log P(Y=y|X=x)\end{aligned}$
实际上定义的就是在所有$X$的条件下,$Y$的混乱度的平均值。
与信息熵中例子关系
前面在介绍信息熵时,举了从盒子中拿小球的例子。其中 $H(X)=3\times\frac{1}{3}\times\log(3)=1.584$ 为小明对盒子中球放置情况的信息熵,当小明知道“盒子里放的不是黑球”时,其信息熵实际上可被表达为:
$H(X|Y=盒子里放的不是黑球)=\frac{1}{2}\log(2)+\frac{1}{2}\log(2)=1$
注意,这和条件熵有点类似,但并不同。条件熵的条件是随机变量,而这里的条件是某一确定的事件。
互信息
互信息用来度量两个随机变量之间的相互依赖程度(依赖的反义词是独立),或者说度量能从一个随机变量中获取的另一个随机变量的信息量。又或者直观地理解为,当一个随机变量已知时,另一个随机变量的不确定性的减少程度。互信息越大,两个变量之间的依赖度越大,相互独立的可能性越小。
下面举个例子比如:
1、明天是否下雨的信息熵$H(X)$。
2、在知道今天是否有晚霞的情况下,明天是否下雨的信息熵$H(X|Y)$。
这二者信息熵之差就是明天下雨与今天的晚霞这两个变量之间的依赖程度。如果把明天是否下雨设为$X$,今天是否有晚霞设为$Y$,那么二者的互信息定义如下:
\begin{aligned} I(X;Y) &= H(X) - H(X|Y)\\ & = -\sum\limits_{x\in \mathbb{X}}P(x)\log P(x) - \sum\limits_{y\in \mathbb{Y}}P(y)H(X|y)\\ & = -\sum\limits_{x\in \mathbb{X}}P(x)\log P(x) + \sum\limits_{y\in \mathbb{Y}}P(y)\sum\limits_{x\in\mathbb{X}}P(x|y)\log P(x|y)\\ & = -\sum\limits_{x\in \mathbb{X}}P(x)\log P(x) + \sum\limits_{y\in \mathbb{Y}}\sum\limits_{x\in\mathbb{X}}P(x,y)\left[\log P(x,y) - \log(y)\right]\\ & = -\sum\limits_{x\in \mathbb{X}}P(x)\log P(x) + \sum\limits_{y\in \mathbb{Y}}\sum\limits_{x\in\mathbb{X}}P(x,y)\log P(x,y) - \sum\limits_{y\in \mathbb{Y}}P(y)\log P(y) \\&= H(X)-H(X,Y)+H(Y) \\ & = H(Y) - H(Y|X) \end{aligned}
从倒数二式可以看出互信息是两个熵之和减去它们的联合熵,是对称的,所以互信息值也等于$Y$的信息熵减去$X$和$Y$的条件熵。实际上,我们可以把互信息直观理解为:当一个系统已知时,另一个系统的不确定程度的减少量。我们又可以联想到前面提到的信息量的减少,信息量的减少是基于某个信息的输入,系统不确定程度的减少量,用于衡量信息的价值。而互信息则是用于衡量两个系统之间的相关性。下图是各个量的关系图:

联合熵
联合熵也是用随机变量而不是分布来表示,定义如下:
\begin{aligned} H(X,Y) = -\sum\limits_x\sum\limits_yP(x,y)\log_2P(x,y) \end{aligned}
衡量随机变量$X$和随机变量$Y$的联合概率密度的信息熵大小。
互信息和信息量
互信息是两个随机变量之间分布的差异,信息量可以用来度量获知分布的某个变量为特定值是,获得的信息。
信息量是在一个变量条件下,另一个变量的熵。
参考资料
1. 信息量和信息熵的理解
4. 一分钟看懂各种熵

 浙公网安备 33010602011771号
浙公网安备 33010602011771号