

Docker的方式安装elasticsearch和kibana 使用
安装elasticsearch、kibana:
#docker pull elasticsearch:7.7.0 docker run --detach \ --name elasticsearch \ --publish 19200:9200 --publish 19300:9300 \ --restart always \ --env "node.name=elasticsearch" \ --env "cluster.name=test-elasticsearch" \ --env "bootstrap.memory_lock=true" \ --env "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ --env "discovery.type=single-node" \ --env "script.painless.regex.enabled=true" \ --volume /data/elasticsearch/elasticsearchdata:/usr/share/elasticsearch/data \ --volume /data/elasticsearch/elasticsearchplugins:/usr/share/elasticsearch/plugins \ --volume /data/elasticsearch/elasticsearchconfig/stopwords.txt:/usr/share/elasticsearch/config/stopwords.txt \ --volume /data/elasticsearch/elasticsearchconfig/synonyms.txt:/usr/share/elasticsearch/config/synonyms.txt \ --volume /etc/localtime:/etc/localtime \ elasticsearch:7.7.0 #chmod -R 777 /data/elasticsearch 安装Elasticsearch时提示权限不够,更改权限即可(chmod -R 777 els) # --env cluster.initial_master_nodes=elasticsearch \ #7.7.0 不需要加 --env "discovery.type=single-node" \ #7.7.0 需要加上 #docker pull kibana:7.7.0 #连接当前机器的docker里面的es #docker run --detach \ --name kibana \ --publish 15601:5601 \ --link elasticsearch:es \ #--link --env "ELASTICSEARCH_HOSTS=http://es:19200" \ --env "LS_JAVA_OPTS=-Xmx256m -Xms256m" \ --volume /etc/localtime:/etc/localtime \ kibana:7.7.0 #连接另外一台机器的docker里面的es,端口也换了 #docker run --detach ` --name kibana-dev ` --publish 15601:5601 ` --add-host=elasticsearch:192.168.0.119 ` #--add-host --env "ELASTICSEARCH_HOSTS=http://elasticsearch:32607" ` --env "LS_JAVA_OPTS=-Xmx256m -Xms256m" ` kibana:7.7.0

ElasticSearch(四)查询、分词器和安装IK插件
安装之后,注意需要重启ES服务期。
curl -XPOST http://localhost:9200/index/_mapping -H 'Content-Type:application/json' -d' { "properties": { "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" } } }'
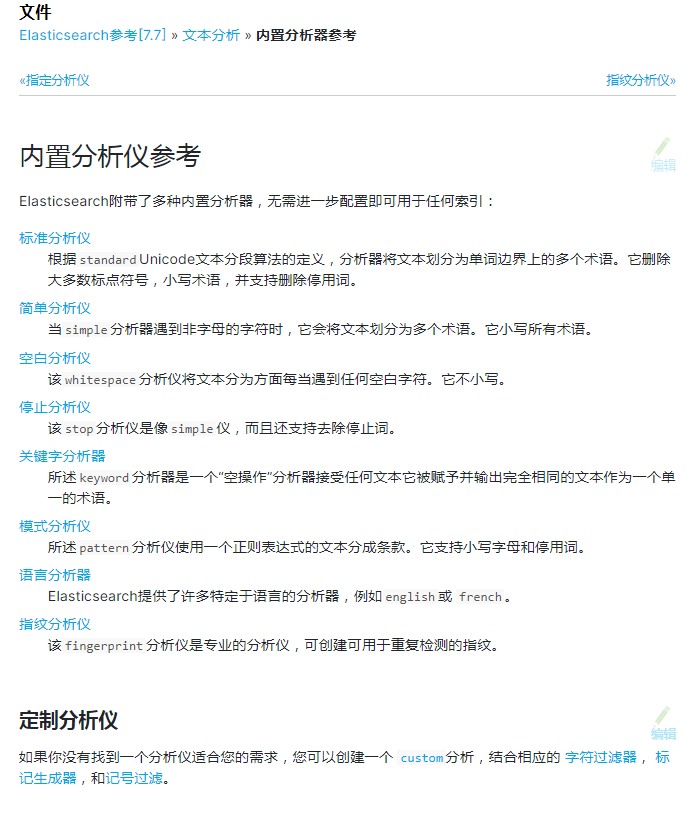
进入容器里,显示所有插件的名称
./bin/elasticsearch-plugin install -h
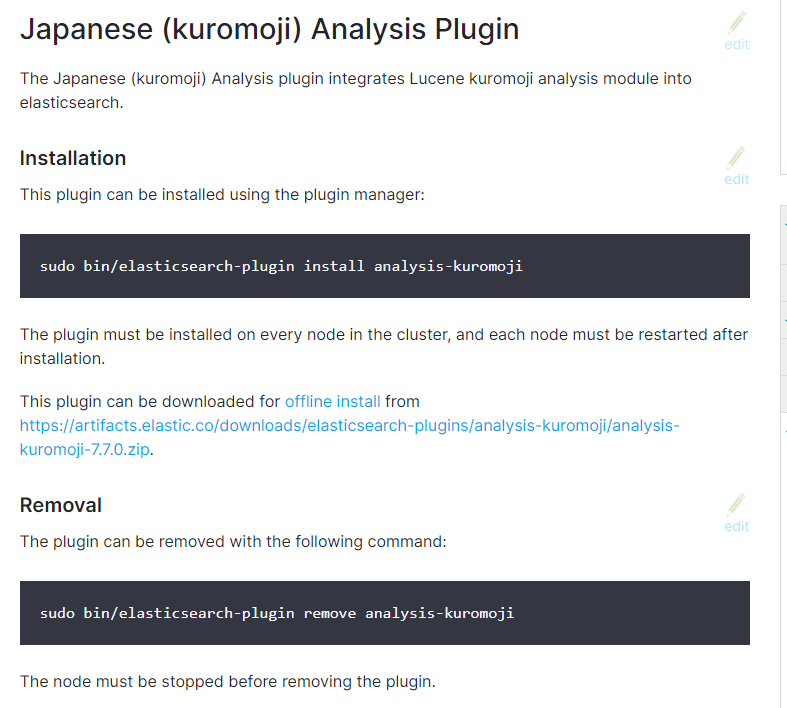
进入容器,在容器里安装日语插件:安装成功之后不需要重启ES服务器
#./bin/elasticsearch-plugin install analysis-kuromoji

安装成功之后的目录结构和IK的相似
# 使用标准分词器 statndard GET _analyze { "analyzer": "standard", "text": "奥迪a4l" } # 使用IK分词器 ik_smart GET _analyze { "analyzer": "ik_smart", "text": "奥迪" } # 使用日语分词器 kuromoji GET _analyze { "analyzer": "kuromoji", "text": "東京都は22日、緩和の行程を3段階で示す「ロードマップ」の詳細を発表した。最初の「ステップ1」で、飲食店の営業時間。" }
1、创建名为 tlz_es 的索引库:
PUT tlz_es
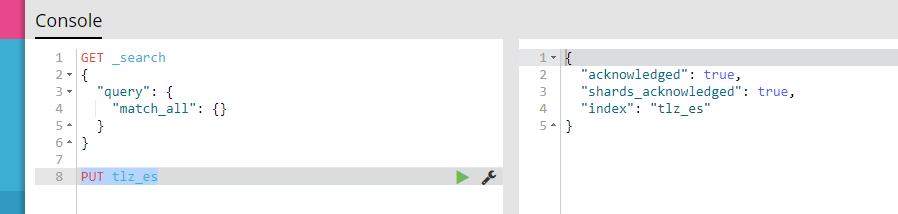
2、往索引库添加文档,created:true表示添加文档成功:
POST tlz_es/article { "title":"Java是世界上最好的语言", "content":"Java是世界上最好的语言,不接受反驳" }
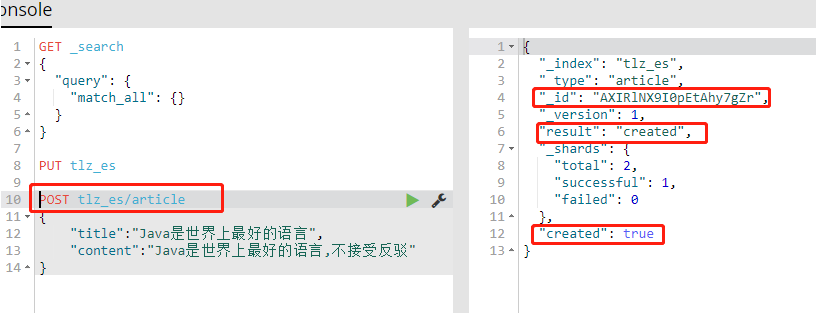
3、查询所有文章
GET tlz_es/article/_search
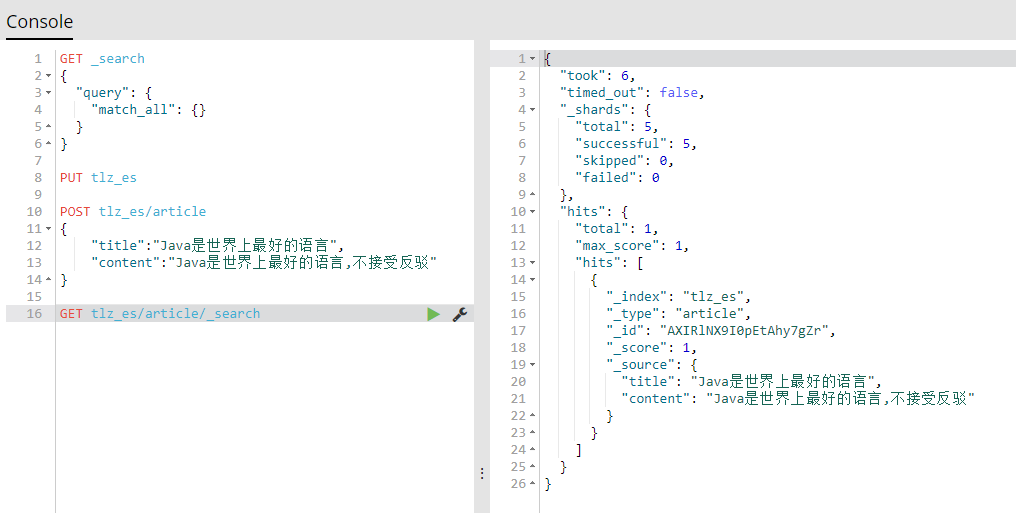
4、修改某一篇文章,复制好_id。此时created:false.如果后面跟一个不存在的id,则为创建操作。
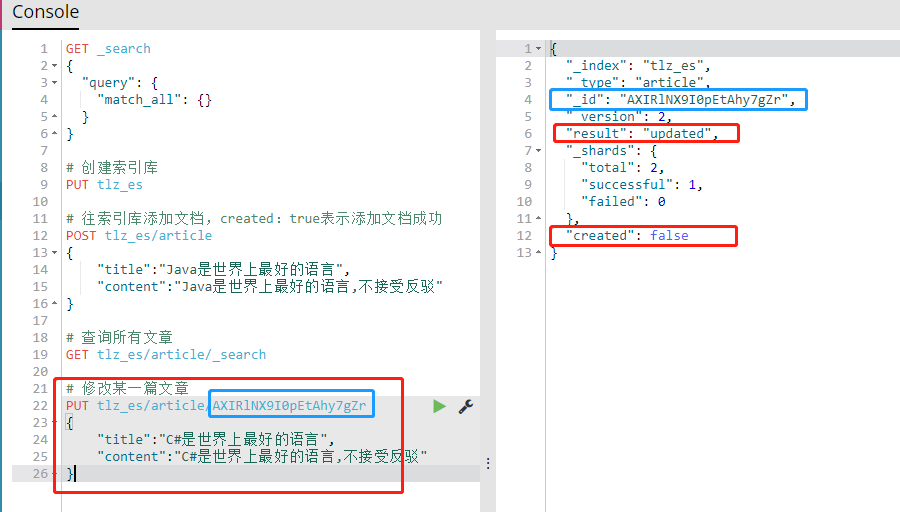
5、条件查询,*表示模糊查询
GET tlz_es/article/_search?q=title:*C*
kibana使用:
GET _search
{
"query": {
"match_all": {}
}
}
# 创建索引库
PUT tlz_es
# 往索引库添加文档,created:true表示添加文档成功
POST tlz_es/article
{
"title":"Java是世界上最好的语言",
"content":"Java是世界上最好的语言,不接受反驳"
}
# 查询所有文章
GET tlz_es/article/_search
# 修改某一篇文章
PUT tlz_es/article/AXIRlNX9I0pEtAhy7gZr
{
"title":"C#是世界上最好的语言",
"content":"C#是世界上最好的语言,不接受反驳"
}
#条件查询,*表示模糊查询
GET tlz_es/article/_search?q=title:*C*
# 查看所有索引
GET _cat/indices
# 查看所有字段映射
GET lucenespumodel/_mapping/
# 查询全部
GET lucenespumodel/_search
# 查询全部,只返回五条记录
GET lucenespumodel/_search
{
"query": {
"match_all": {}
},
"size":5
}
# 聚合字段
GET lucenespumodel/_search
{
"query": {
"match_all": {}
},
"size":5,
"aggs" : {
"PropertyTextFacet" : {
"terms" : { "field" : "PropertyTextFacet" }
}
}
}
# 动态列
GET lucenespumodel/_search
{
"query": {
"query_string": {
"default_field": "SPUID",
"query": "578123"
}
},
"size":5,
"_source": {
"includes": ["SPUID","TopicLeiMuMaxSort","TopicLeiMuMaxSort_1223"]
}
}
GET lucenespumodel/_mapping/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号