「后缀数组」学习笔记
构造
后缀数组(Suffix Array)的定义: $sa_i$表示排名为$i$的后缀的起始位置。
思想
$Manber$ & $Mayer$倍增法,思想很好理解。由于各个后缀之间不像普通的数列,它们是有内部联系的:即后缀关系。因此我们想到每次对所有后缀的前$2^k$位排序。而后在对$2^{k+1}$排序的时候充分利用排$2^k$时的信息来完成。由于已对所有$2^k$进行了排序,也就知道了所有$2^k$的相对关系。这样在排$2^{k+1}$时相当于是在排二元组,即问题转化为了二元组的快速排序问题。而这能够利用$O(n)$的基数排序实现。因此后缀数组的构造复杂度是$O(n \log n)$
用基数排序排二元组
用一个桶$c$统计出各第一关键字的出现次数。接着统计出$c$数组的前缀和,依然保存在$c$中。因此$c$数组的意义是:第一关键字排名为前$i$(离散化意义下)的总个数。接着沿第二关键字从大到小的顺序遍历,对于每一个遍历到的,一定是对应第一关键字中排名最靠后的,因此直接得出排名,并将桶的值相应减去一。在后缀数组的构造中,会具体讲解其代码实现方法。
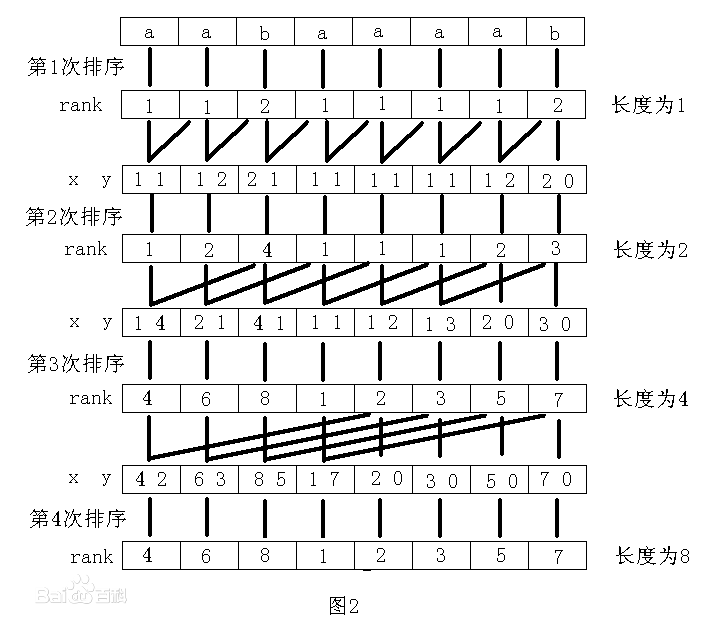
代码实现
在实现的过程中,我们用数组$x$保存上一轮(也就是$2^{k-1}$)的排名结果。其中$x_i$的意义是以位置$i$作为起始的后缀前$2^{k-1}$位的排名,这个名次是可重的,也就是相同的串名次严格相同。如上图中的rank。
如果将$x$作为第一关键字(也就是二元组的第一项),那么接下来我们要得到所有第二关键字,其等价于$x_{i+k}$。这样得到的第二关键字顺序是杂乱无章的,由于要做基数排序,我们得按照排名顺序来保存第二关键字。显然第二关键字为空(i+k出头了)的元素率先保存。其余按照之前处理出的$sa_i$(排名为$i$的起始位置,意义与$x_i$互逆)的顺序保存。我们把第二关键字保存在数组$y$内。$y_i$存的是:第$i$小的第二关键字对应的第一关键字位置。
有了$x$和$y$就可以求$sa$了。我们用一个桶$c_i$表示排名为$i$的关键字个数。然后对$c$做前缀和,依然保存在$c$中。现在$c$的意义是排名前$i$的关键字总个数。好了,按照第二关键字从大到小的顺序在桶里取出排名。具体方法是,$y_i$对应的第一关键字排名是$x_{y_i}$,由于第二关键字是从大到小的,因此这对二元组的排名一定是$c_{x_{y_i}}$。因此在代码中我们写道$sa[c[x[y[i]]]--]=y[i]$,这就是为什么我们要在$y$中保存第一关键字位置。
至此$2^k$的$sa$就求完了。然而还需要处理出$x$以便下一轮的求解。然而我们依然需要利用当前$x$中的信息来求排名,因此就需要一个临时数组了。而为了节省空间,我们发现$y$数组已经没用了,因此我们就把原来$x$的信息先存到$y$里面去。方法很简单:$swap(x,y)$交换指针即可。本来我们直接用$x[sa[i]]=i$来做就可以了,然而一个很重要的问题是相等时排名要求严格相同。因此我们要增加一个判断了。要判断的是排名第$i$的二元组的两个关键字各自的排名是否和排名第$i-1$的二元组的完全相同。写成代码也就是$y[sa[i]]==y[sa[i-1]]$&&$y[sa[i]+k]==y[sa[i-1]+k]$。我们可以用一个指针$p$来记录排名。每当这个条件不满足的时候就$++p$。当$p==n$的时候意味着所有后缀的名次都已经做出区分了,工作也就结束了。
数组的定义很多很奇怪,用多了也就习惯了。
inline void get_SA(int m){
int p;
for(int i = 1; i <= m; ++i) c[i] = 0;
for(int i = 1; i <= n; ++i) ++c[x[i] = s[i]];
for(int i = 1; i <= m; ++i) c[i] += c[i-1];
for(int i = n; i >= 1; --i) sa[c[x[i]]--] = i;
for(int k = 1; k <= n; k += k){
p = 0;
for(int i = n-k+1; i <= n; ++i) y[++p] = i;
for(int i = 1; i <= n; ++i) if(sa[i] > k) y[++p] = sa[i]-k;
for(int i = 1; i <= m; ++i) c[i] = 0;
for(int i = 1; i <= n; ++i) ++c[x[i]];
for(int i = 1; i <= m; ++i) c[i] += c[i-1];
for(int i = n; i >= 1; --i) sa[c[x[y[i]]]--] = y[i], y[i] = 0;
swap(x,y);
x[sa[1]] = 1, p = 1;
for(int i = 2; i <= n; ++i) x[sa[i]] = (y[sa[i]]==y[sa[i-1]] && y[sa[i]+k]==y[sa[i-1]+k]) ? p : ++p;
if(p >= n) break;
m = p;
}
}
最长公共前缀(LCP)
后缀数组在解决问题的时候几乎都要用到最长公共前缀(Longest Common Prefix)。
后缀数组已经将一个字符串所有的后缀处理好了,那么后缀之间的前缀关系就非常重要。比如说经典的字符串匹配问题(KMP可以$O(n)$解决),如果用后缀数组来做,我们就要把文本串和模式串接在一起(模式串接在后面),然后做后缀排序。如今模式串成为了整个大串的一个后缀了,要找与模式串相等的子串,等价于在大串的所有后缀中寻找一个后缀,使得它与模式串的LCP长度等于模式串长度。
而我们发现后缀排序后相同的前缀肯定排在一起。因此很多时候通过LCP,字符串的问题能够转化为区间问题,因此并查集、线段树、莫队等数据结构就有了用武之地。
由于LCP那么有用,那么就有必要高速地来求解。
首先是定义:
定义$LCP(j,k)$表示后缀$j$与后缀$k$的最长公共前缀长度。
定义$height$数组表示两个排名相邻的后缀的LCP。$height_i=LCP(sa_{i-1},sa_{i})$
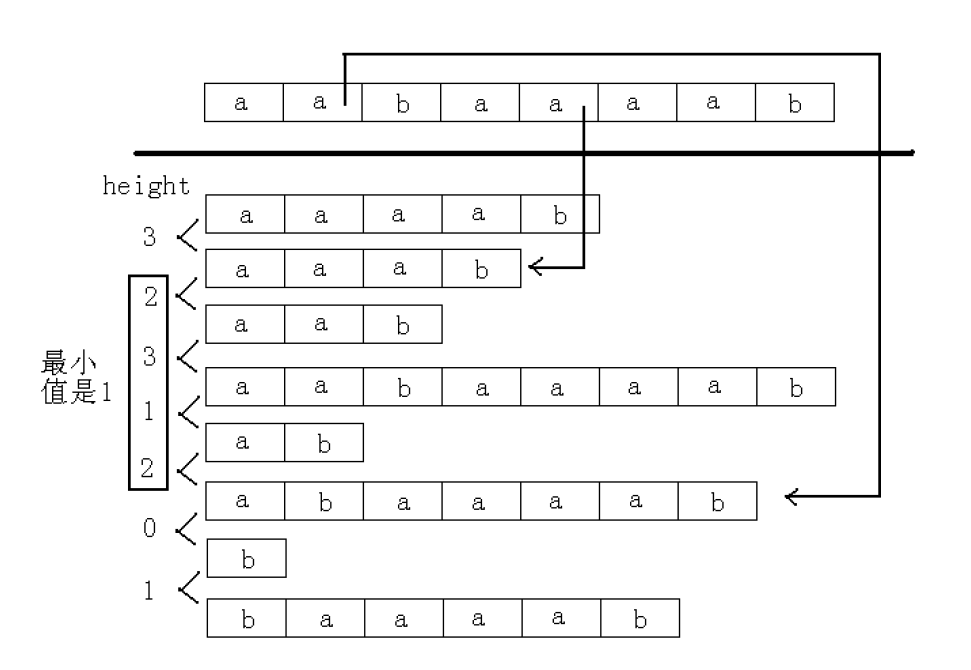
我们发现如果找到两个后缀在后缀数组中的名次,其LCP一定是这段$height$中的最小值。这就是刚才所说的区间问题。因此只要高效地求出$height$数组就能利用$ST$表来求得LCP了。
我们不按后缀数组的顺序来求,而是按照后缀的位置从前到后来求$height$。
以下“后缀x”代表x位置的后缀。
假设我们已经求得后缀$i-1$与排在它前面的后缀$k$的$height$,即$height_{rnk_{i-1}}$
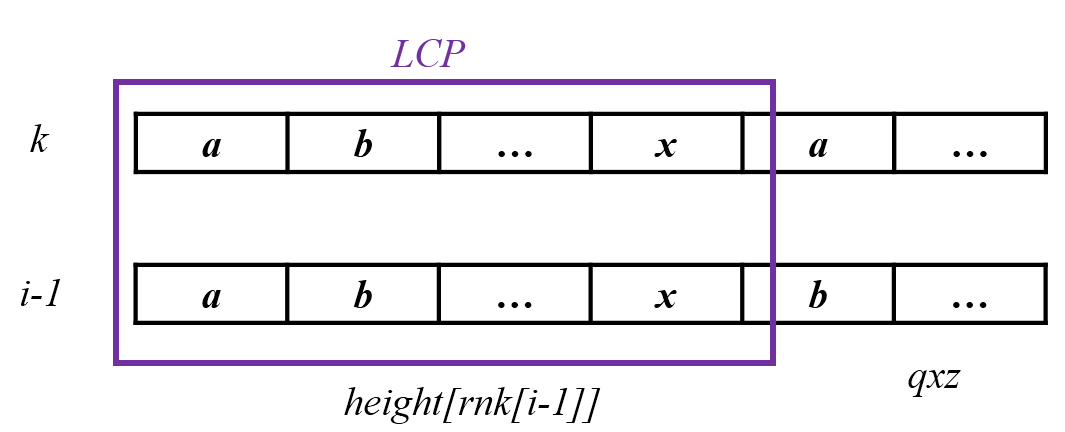
接下来要考虑后缀$i$和排在它前面的后缀$p$。
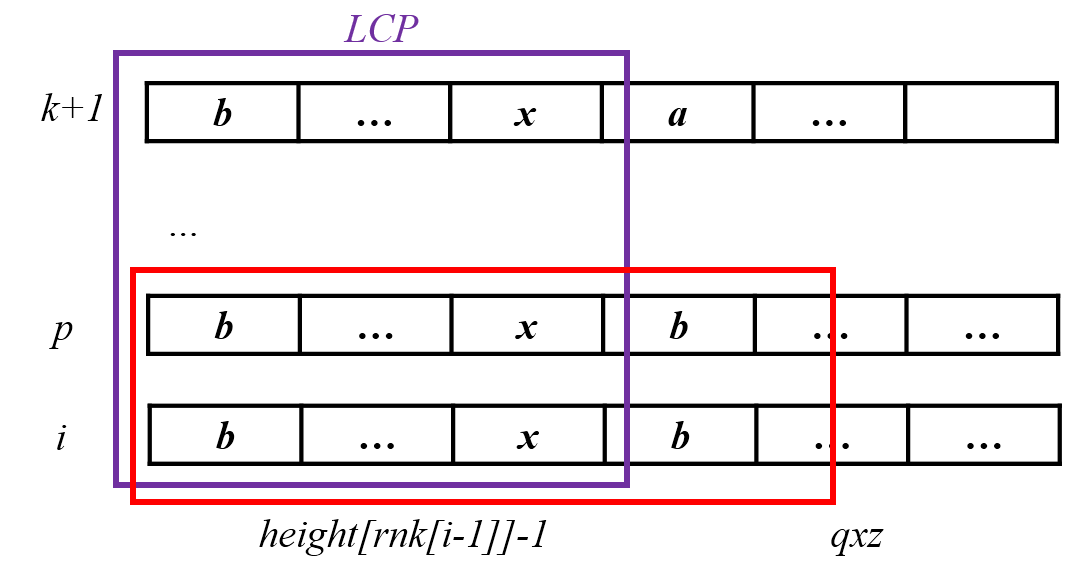
后缀$i$相对于后缀$i-1$只少了第一个字符。而既然肯定的是后缀$k+1$与后缀$i$的LCP为$height_{rnk_{i-1}}-1$,那么$LCP(p,i)$的长度至少会等于$height_{rnk_{i-1}}-1$。因此有$height_{rnk_{i}} \geq height_{rnk_{i-1}}-1$。
接下来,暴力往后匹配即可。
由此我们的$height$近乎于单调递增,也就保证了求$height$数组的复杂度为$O(n)$。
POJ 2774 Long Long Message
给出两个字符串($n \leq 10^4$),求两者的最长公共子串(连续)
将两个字符串拼接在一起,求出$\max\{height_i\}$就是答案,注意要满足两个后缀的要分别存在于各自的字符串内。
这里将公共子串转化为了公共前缀来求解。
luogu 3763 DNA
给出两个字符串$s_1,s_2$,问$s_1$中有多少个长度和$s_2$相同的连续子串只与$s_2$相差不超过三个字符。
依然拼在一起,用ST表维护出LCP。在$s_1$中枚举起点,每次跳LCP,停下时判断字符是否相等,不相等记录+1。然后再跳LCP……这样保证了判断一个起点的复杂度是常数。预处理的复杂度为$O(nlogn)$。
luogu 2852 Milk Patterns
给出一个字符串,求出其中至少出现$k$次的最长子串。($1 \leq n,k \leq 2 \cdot 10^4$)
预处理后缀数组与$height$数组。出现$k$次的串在后缀数组中一定是排在一起的,于是问题转化为在$height$数组中长度为$k-1$的区间的最小值最大为多少。可以二分,也可以单调队列。
luogu 3975 弦论
给出一个字符串,求字典序第$k$小的子串(分两种情况,一为不同位置的相同子串算一个,二为不同位置的相同子串算多个)
子串就是每一个后缀的所有前缀。对于不同位置算一个的情况,显然对后缀进行排序之后除了$LCP$部分其余部分每一行都是单调递增的,并且前一行的全部比后一行的小。因此我们预处理$height$数组,$LCP$是重复部分,每一次除掉重复部分进行排名的累加,直到第$k$个即可。
对于不同位置算多个的有些棘手。我们可以考虑去暴力构造答案——二分最后答案的子串中每一位的字母。预处理前缀和方便$judge$。细节很多很恶心。复杂度看似是$O(nlogn)$还带$26$的常数过不去,但实际上我们的区间是在快速缩小的,也就是说我们的$log$根本没那么多,而且一旦找到字母就会跳出,常数一般也不会到达$26$。跑得飞快。
luogu 4051 字符加密
给出一个字符串,排成环状,对环上每个起点绕一圈的串(每个长度都为n)按字典序排序。依次输出排序后每个串的末尾。
字符串后面再拼一个自己,做后缀排序。没想到,想了个极复杂的做法错了……
luogu 3966 单词
多模匹配,AC自动机板子
后缀排序后枚举即可。在构造SA的过程中,$m$是会逐渐变大的,因此m=p是必须要写的。
luogu 4248 差异
求$\sum\limits_{1 \leq i < j \leq n} lcp(i,j)$
这个问题等价于求出height之后,以区间最小值作为区间值的所有区间和。我们考虑一个区间最小值对整个区间的贡献,是以这个最小值靠左作为起点,靠右作为终点的所有区间。因此问题转化为求解每个最小值对多大的区间产生贡献。利用单调栈维护。
luogu 3181 找相同字符
给出两个字符串,求相同子串个数
两串合并后(中间插入#)等价于上一题,只不过两个子串必须分开一个在第一个,一个在第二个。这里需要一个容斥思想,即整个答案减去两个串的子答案。
我还考虑了一种维护前缀和然后单调栈维护的方法,但是细节很多。
学了SAM之后做这种题会简单点吧?
</font>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号