
试了下ocr
pdf能看了,拓展的驱动下,想着是否可以ORC呢,识别到文字内容更有帮助。
按网搜的顺序,开始是用pytesseract,pip安装顺利,但运行不了,提示找不到pytesseract,按网上的帮助下载win安装包,选上中文包,再试,可以运行了,就是中文基本识别不了,也不知哪里改善,只得作罢。
换下一个,paddleocr,pip安装报错,按网上的帮助,按顺序requirements.txt装了一遍,卡在lmdb的patch-ng上,再网搜,还网搜,艰难的在硕硕(https://icenturyw.com)这里找到了方法,备之:
git clone https://github.com/Bye-lemon/py-lmdb.git
cd py-lmdb
pip install .
lmdb安装成功后,再如法下载安装paddleocr,
https://github.com/PaddlePaddle/PaddleOCR
一试,中文识别有效,藏在一簇簇的数字中。"pip install . "的用法对我很是新鲜,用python也算久了,不记得有这样的用法。
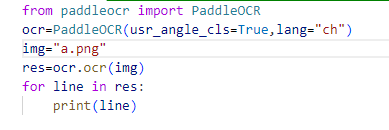
12日续:
按顺序,接着是easyocr,pip安装很顺利,识别时报错urllib.error,Loliykon说要手动下载模型文件,简体中文地址:
https://github.com/JaidedAI/EasyOCR/releases/download/pre-v1.1.6/chinese_sim.zip
跳转响应不明显,回过头来找发现下了两份了,点击的效果就是接着下第三份。把下载的pth文件解压复制到当前用户目录的.easyocr里的model文件夹里,代码就能识别了,比较之下发现效果远比不上paddleocr,和网文说的easyocr中文效果更佳截然相反,是否模型文件有待更新呢,还是paddleocr进步了,肯定的是事件总在不断变化中,实践一下至少能知道当前节点是哪一趋向......
13日续:
接着测试了muggle_ocr和dddd_ocr,按介绍这两个ocr都是用来应对登录界面的验证码,试验的效果确实如此,包括复杂图形的图片基本识别不了文字,对简单的几个字母还算有效,比较起来dddd更强,muggle会有识别不全。这俩都依赖tensorflow,这货是基于学习的视觉识别项目,前段时间试用时因没装独显就搁置了,竟然用在了验证码识别上,妥妥的野牛刀砍蜗牛。
pip install ddddocr
学习,常人哪有过目不忘的,勤为径,勉为舟,起步之初,把自己当笨鸟看,学了练,练了学,路子渐于熟稔,视野逐于开阔,不求立于名则树于己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号