WEB缓存系统之varnish代理以及健康状态检测配置
 对于varnish来讲,对后端主机做健康状态监测的原理是请求后端主机特定的资源,如果能够在指定的超时时长内正确响应我们就认为后端主机上健康状态的,如果不能正确的响应我们就认为该后端主机上不健康的;在varnish中对后端主机做健康状态监测需要用.probe 来引入一段上下文配置,明确的说明怎么对后端做健康状态监测(或者用probe关键字+名称来引入一段公有的健康状态监测机制,后端多台主机可以用.probe +名称引用);比如请求后端主机的那个url或者用.request来指定向后端主机发送的请求的报文;对后端主机的响应多少次我们认为是健康的,监测频度,超时时长等等信息;
对于varnish来讲,对后端主机做健康状态监测的原理是请求后端主机特定的资源,如果能够在指定的超时时长内正确响应我们就认为后端主机上健康状态的,如果不能正确的响应我们就认为该后端主机上不健康的;在varnish中对后端主机做健康状态监测需要用.probe 来引入一段上下文配置,明确的说明怎么对后端做健康状态监测(或者用probe关键字+名称来引入一段公有的健康状态监测机制,后端多台主机可以用.probe +名称引用);比如请求后端主机的那个url或者用.request来指定向后端主机发送的请求的报文;对后端主机的响应多少次我们认为是健康的,监测频度,超时时长等等信息;
前文我们聊了下varnish的缓存项修剪配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12666406.html;今天我来说一下varnish作为代理服务器反向代理多主机的配置;前边的所有操作都是针对后端主机只有一台的情况来说varnish的配置;在生产环境中,我们的web站点服务器不应该只有一台;默认情况下才安装好varnish的主机,在default.vcl中只可以指定一台后端主机的地址和端口;如果我们后端主机是多台的情况下,我们需要加载varnish的模块directors;然后用backend+后端主机名称(这个名称是我们自定义的,只要是一合法名称即可),来分别把每个主机的地址和端口配置好即可;
示例:

提示:以上每个红框中的内容表示一台后端server;以上配置表示定义两台后端主机,其名称分别为webserver1和webserver2;
把主机定义好后,这里还需要用在vcl_init状态引擎中配置初始化一个组,然后把这两台主机加到对应的组中;
示例:

提示:以上配置表示用directors模块中的round_robin()方法初始化一个组对象,取名叫webserver;然后把对应两台主机加入到这个初始化组对象中;这意味着这个组里有两个成员,一个是webserver1,一个是webserver2;directors.round_robin()用这个方法初始化组对象表示往后端调度的算法是轮询,即没有权重;要想有权重,需要用directors.random()方法;如果需要做会话保持,需要用到directors.hash()方法;
示例:初始化组对象用random方法

提示:用random方法就可以在后端server名称后面加上权重;
示例:初始化组对象用hash方法来保持会话

提示:hash方法也是支持权重的;
到此我们就把两台后端主机加入到webserver组中了;现在我们可以编译加载我们的配置文件,然后用varnishadm工具连接到控制管理shell中查看后端主机列表;
[root@test_node1-centos7 ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082 200 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.10.0-693.el7.x86_64,x86_64,-sfile,-smalloc,-hcritbit varnish-4.0.5 revision 07eff4c29 Type 'help' for command list. Type 'quit' to close CLI session. varnish> vcl.list 200 active 0 boot varnish> vcl.load test default.vcl 200 VCL compiled. varnish> vcl.list 200 active 0 boot available 0 test varnish> vcl.use test 200 VCL 'test' now active varnish> backend.list 200 Backend name Refs Admin Probe webserver1(192.168.0.10,,80) 2 probe Healthy (no probe) webserver2(192.168.0.99,,80) 2 probe Healthy (no probe) varnish> quit 500 Closing CLI connection [root@test_node1-centos7 ~]#
提示:可以看到我们编写的vcl把多台主机加入到webserver组的配置生效了;从上面的配置看,后端主机有两台,一台是webserver1,一台是webserver2;
测试:用curl命令访问192.168.0.99:8000 看看是否把用户请求分别调度到后端个server上去了?
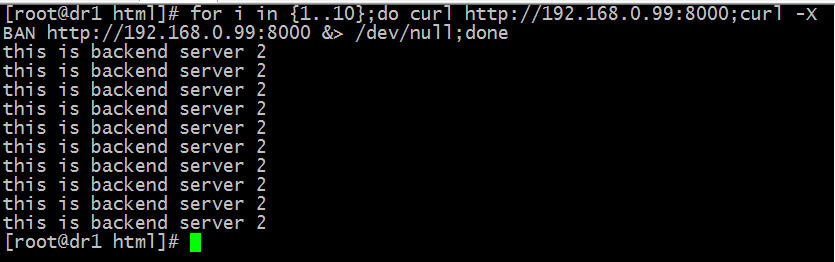
提示:从上面的结果看,好像没有把用户的请求调度到server1上去;原因是我们没有配置说明把所有未命中缓存的请求发送到后端主机上去,它默认是把第一次匹配backend 关键字+名称的配置当作默认主机;所以这里我们怎么访问都调度到192.168.0.10这台主机上去;
示例:在vcl_recv中调用我们之前定义的组,明确说明把未命中缓存的请求发送到该组上;
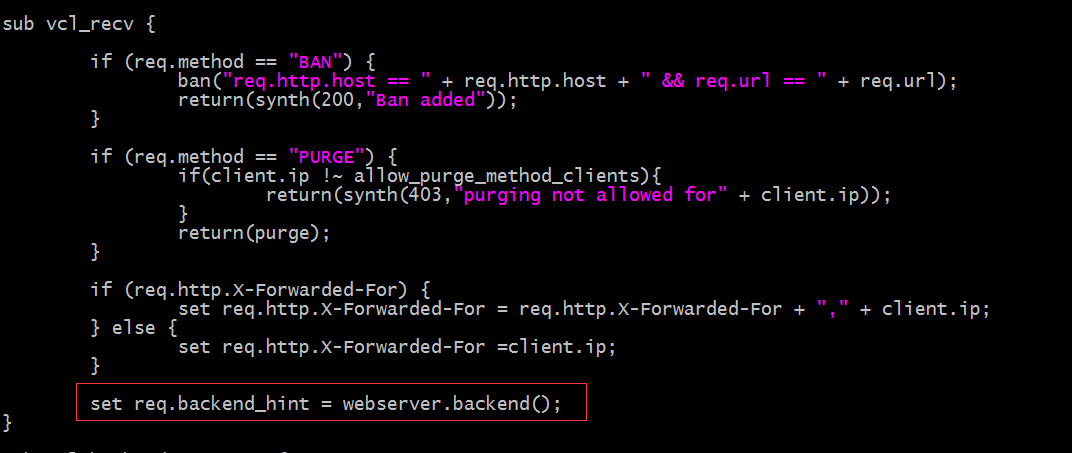
提示:以上红框中的内容表示把用户请求发送到我们定义好的组上的主机;
测试:
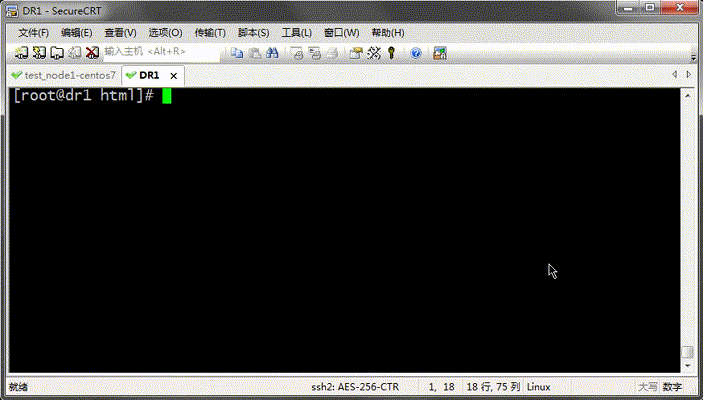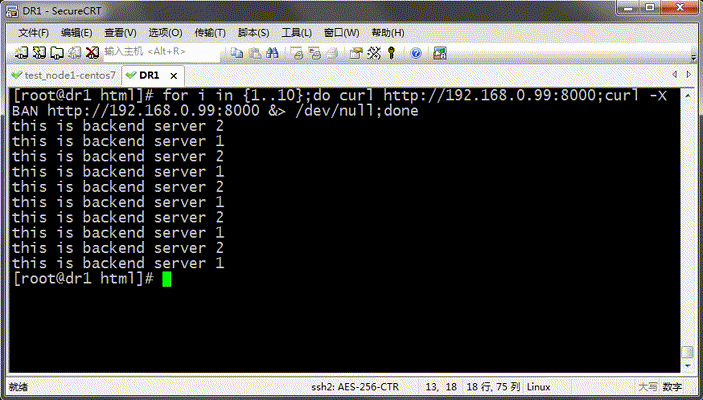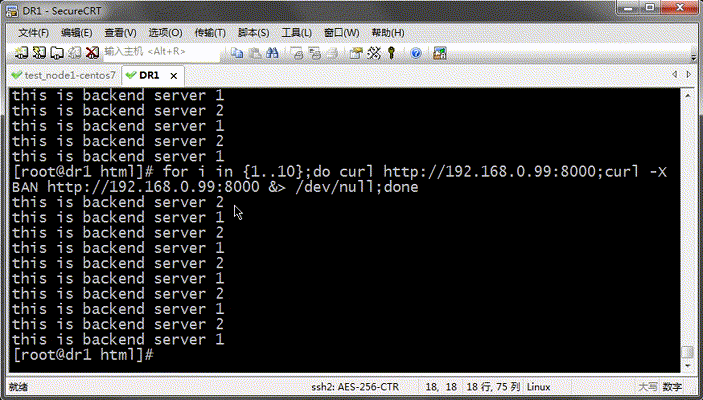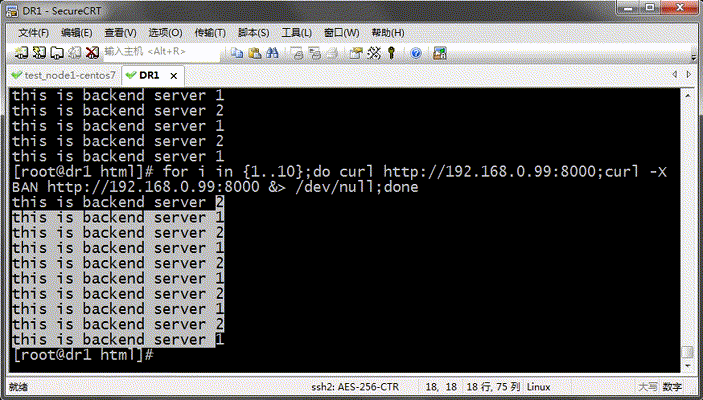
提示:从上面的结果看,我们定义的主机上基于轮询的方式在往后端调度;这里测试需要把varnish上的缓存项给修剪掉,然后再次请求才可以看到把请求调度到不同主机上;
以上就是varnish代理多主机的配置方法,总结如下:
1)首先我们要导入directors模块;
2)用backend关键字来定义后端主机,起一名称,用花括号引入一段上下文,里面用.host指定后端主机的IP地址,用.port指定后端主机端口;
3)在vcl_init状态引擎中初始化一个组对象,然后用组对象的add_backend(server)把对应主机加入到该组;
4)在vcl_recv状态引擎中使用我们初始化好的组对象;用set req.backend_hint = 组对象中的backend();表示把为能命中的用户请求发送到该组上,至于用轮询还是加权轮询还是hash,取决于我们初始化组对象用到的方法;
了解了varnish代理多台主机的配置后,接下来我们再来说说varnish对后端主机做健康状态监测的配置;对于varnish来讲,对后端主机做健康状态监测的原理是请求后端主机特定的资源,如果能够在指定的超时时长内正确响应我们就认为后端主机上健康状态的,如果不能正确的响应我们就认为该后端主机上不健康的;在varnish中对后端主机做健康状态监测需要用.probe 来引入一段上下文配置,明确的说明怎么对后端做健康状态监测(或者用probe关键字+名称来引入一段公有的健康状态监测机制,后端多台主机可以用.probe +名称引用);比如请求后端主机的那个url或者用.request来指定向后端主机发送的请求的报文;对后端主机的响应多少次我们认为是健康的,监测频度,超时时长等等信息;
示例:
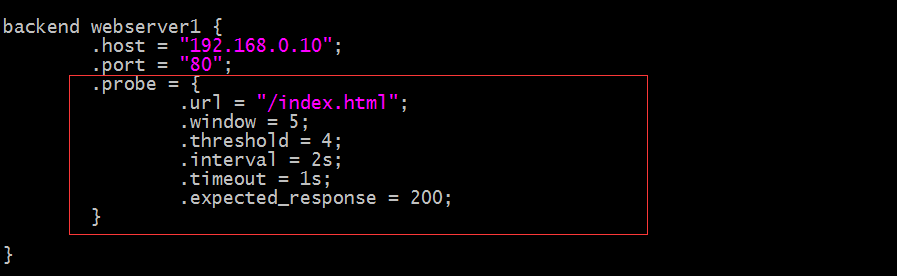
提示:以上红框中的配置就表示对webserver1这台主机做健康状态监测;其中.window表示基于最近的多少次检查来判读其健康状态;.threshold表示最近.window中定义的检查次数至少有多少次是成功的,我们就认为后端主机上健康的;.interval表示检查的频度,多久检查一次;.timeout表示超长时长;综上所述,该配置就表示对webserver1这台主机做健康状态监测,如果每隔2秒,超时时长为1秒,请求该主机上的/index.html资源,在最近5次中有4次是成功的,我们就认为后端主机上健康的;
当然以上是对一台主机做健康状态检查的配置。如果是多台主机,监测的方式都是一样的,我们可以把对健康状态监测的配置单独用probe + 名称来定义监测机制;然后在个server中用.probe +名称来应用我们定义的健康状态监测的配置;
示例:
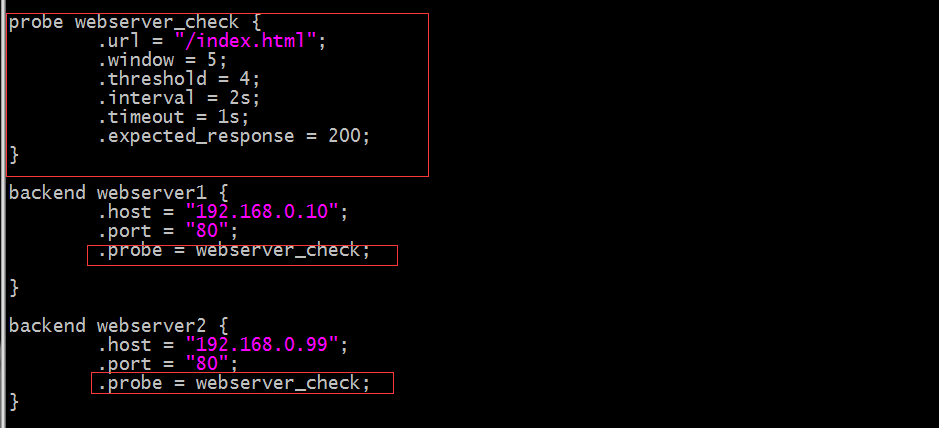
提示:以上配置就表示定义了一个健康状态监测的配置其名称为webserver_check,然后在个后端server的配置中用.probe来对webserver_check调用;意思就表示两台主机都用同样的监测配置;
当然除了以上对rul请求外,我们也可使用向后端主机发送指定一的请求报文的形式来定义健康状态监测机制;
示例:

提示:以上配置表示对于server1的健康状态监测是向server1发送特定的请求首部,如果每隔2秒超时时长为1秒,在5次请求中有4次是200的响应码,我们就认为该主机上健康的,否则不健康;对于server2主机的健康状态监测是通过项该主机上的特定资源/index.html发起请求,如果每个2秒超时1秒的情况下,5次请求中有4次都是200的响应码,我们就认为该主机上健康的,否则不健康;如果不指定.expected_response默认值就是200;
测试:编译加载default.vcl 看看我们配置的健康状态监测是否正确
[root@test_node1-centos7 ~]# varnishadm -S /etc/varnish/secret -T 127.0.0.1:6082 200 ----------------------------- Varnish Cache CLI 1.0 ----------------------------- Linux,3.10.0-693.el7.x86_64,x86_64,-sfile,-smalloc,-hcritbit varnish-4.0.5 revision 07eff4c29 Type 'help' for command list. Type 'quit' to close CLI session. varnish> vcl.load check_cfg default.vcl 200 VCL compiled. varnish> vcl.use check_cfg 200 VCL 'check_cfg' now active varnish>
提示:上面load过程没有保存,说明我们配置后端服务器健康状体检查的配置没有问题;接下来测试把后端主机服务宕机,在管理shell中使用backend.list查看对应主机是否会变为sick?

提示:通过上面的测试结果看,我们把后端主机192.168.0.10这台主机的httpd服务给停了,然后在看后端主机情况,立刻webserver1的状态就变为了sick,我们接着又把服务给启动起来,再看后端服务器状态,可看到当检查到第四次是正常的响应后,状态就变成health;说明我们配置后端主机健康状态监测是没有问题的;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号