
3.Spark设计与运行原理,基本操作
1.Spark生态系统的组成及各组件的功能1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能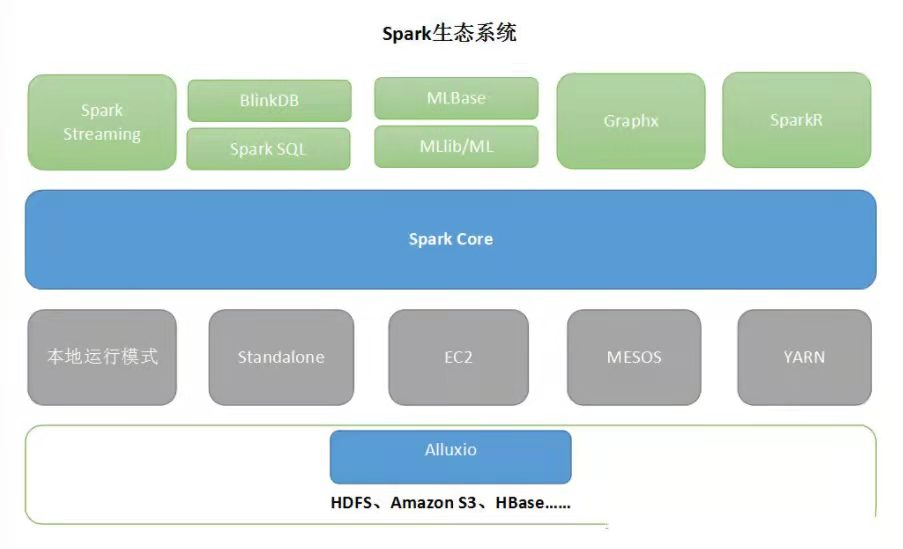
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
DAGScheduler, TaskScheduler.
RDD:是弹性分布式数据集(Resilient Distributed Dataset)的简称,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型;
DAG:是Directed Acyclic Graph(有向无环图)的简称,反映RDD之间的依赖关系;
Executor:某个Application运行在worker节点上的一个进程,该进程负责运行某些Task,并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor,在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象,负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task,这个每一个CoarseGrainedExecutor Backend能并行运行Task的数量取决于分配给它的cup个数
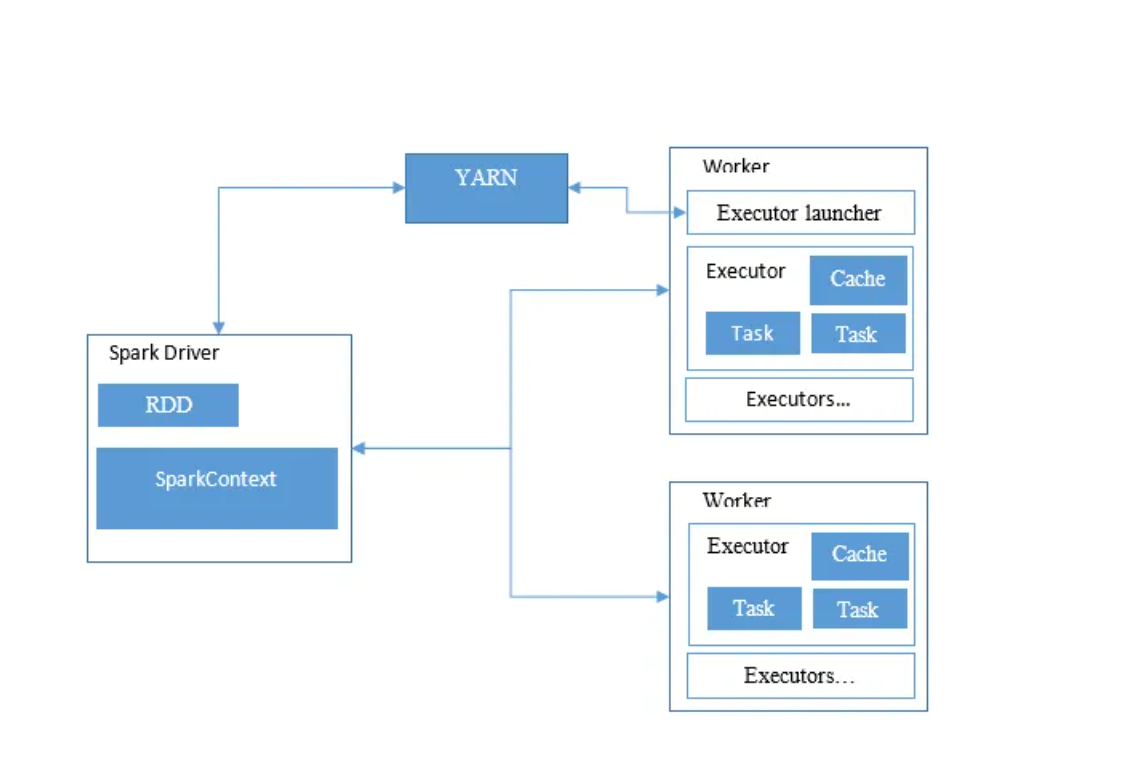
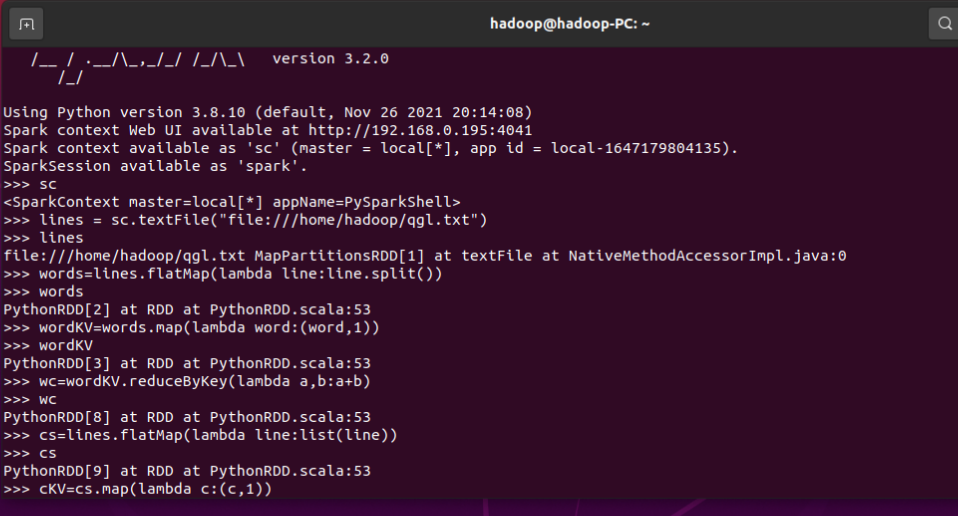
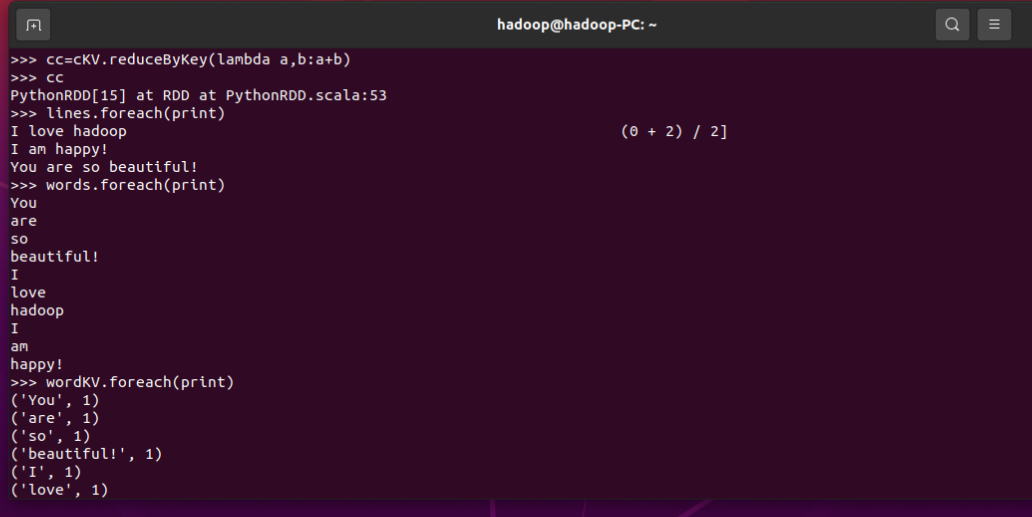
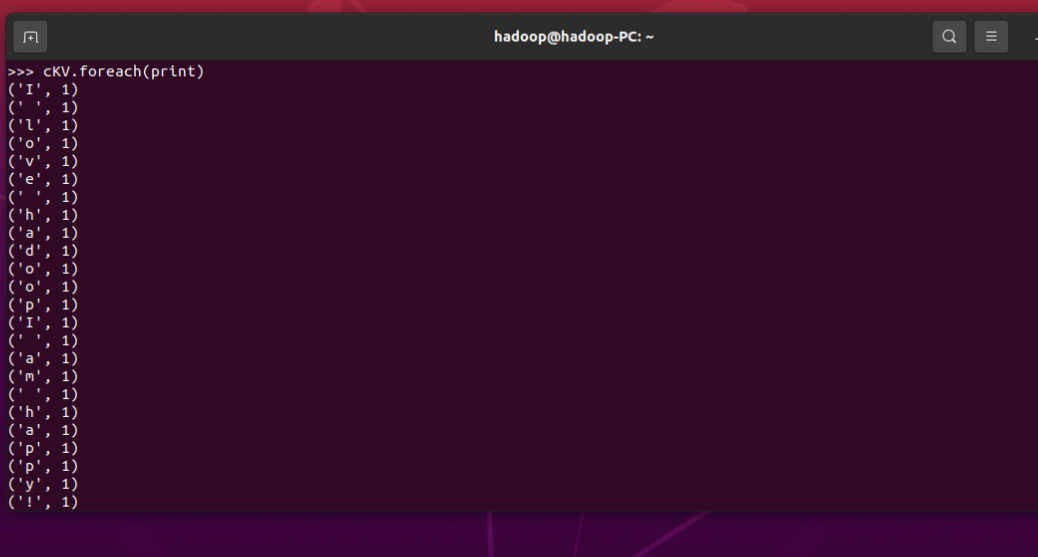
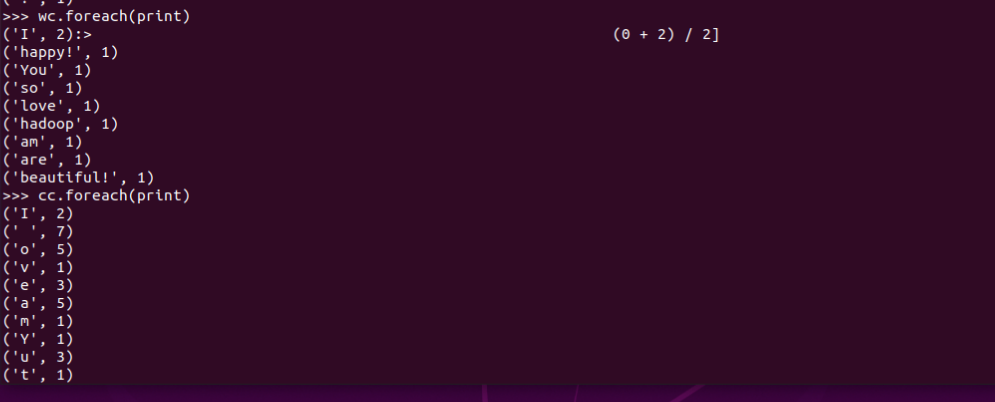
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号