| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/ |
|---|---|
| 这个作业要求在哪里 | 个人项目 - 作业 - 计科23级34班 - 班级博客 - 博客园 |
| 这个作业的目标 | <编写项目实现论文查重,并进行异常测试和性能分析> |
-
github仓库链接
-
PSP表格如下
Process Stages Process Stages (中文) 预估耗时(分钟) 实际耗时(分钟) Planning 计划 20 15 · Estimate · 估计这个任务需要多少时间 150 251 Development 开发 100 120 · Analysis · 需求分析 (包括学习新技术) 130 144 · Design Spec · 生成设计文档 25 13 · Design Review · 设计复审 15 27 · Coding Standard · 代码规范 (为目前的开发制定合适的规范) 10 9 · Design · 具体设计 30 69 · Coding · 具体编码 60 67 · Code Review · 代码复审 20 65 · Test · 测试(自我测试,修改代码,提交修改) 10 29 Reporting 报告 60 87 · Test Report · 测试报告 35 53 · Size Measurement · 计算工作量 10 17 · Postmortem & Process Improvement Plan · 事后总结, 并提出过程改进计划 40 31 · 合计 715 997 -
设计与实现过程
代码架构(4个类)
![af6190ad6f0a1b65278e5fe4e6ef67d2]()
-
CopyDetection
封装了论文查重的算法函数
calculateSimilarity,cosineSimilarity,getWordFrequency,segment -
FileOperation:封装了文件操作的函数
-
Main:主函数,用于调用函数和测试
-
TestFunction:单元测试
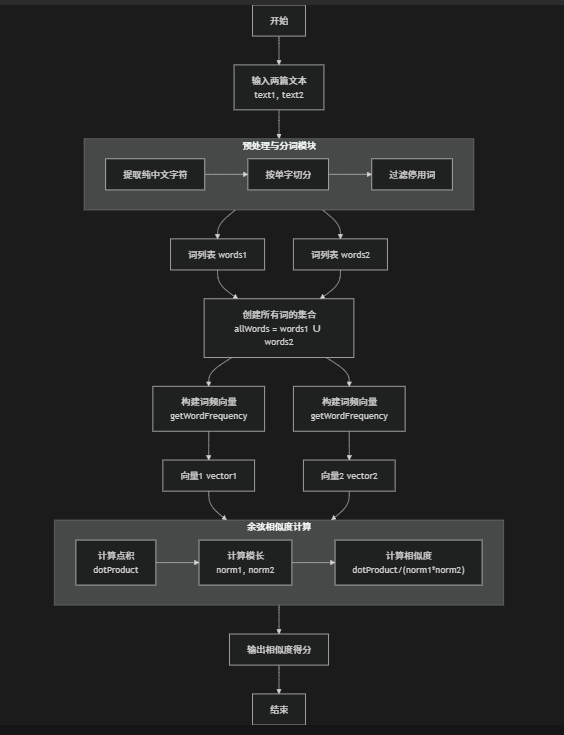
流程图
![1da91b35fb030c0abbffe951fe2cbbaf]()
-
-
性能改进
-
改进计算模块性能上所花费的时间:31
-
改进的思路:
- 当前的单字分词虽然简单,但损失了词语信息,可采用二元语法或者集成专业分词器,能在不依赖词典的情况下,一定程度上捕捉词语组合信息,准确识别实体、新词。
- 当前的词频向量过于简单,可在计算前将同义词归一化为同一个词,直接提升对“换词不换意”这种情况的识别能力
-
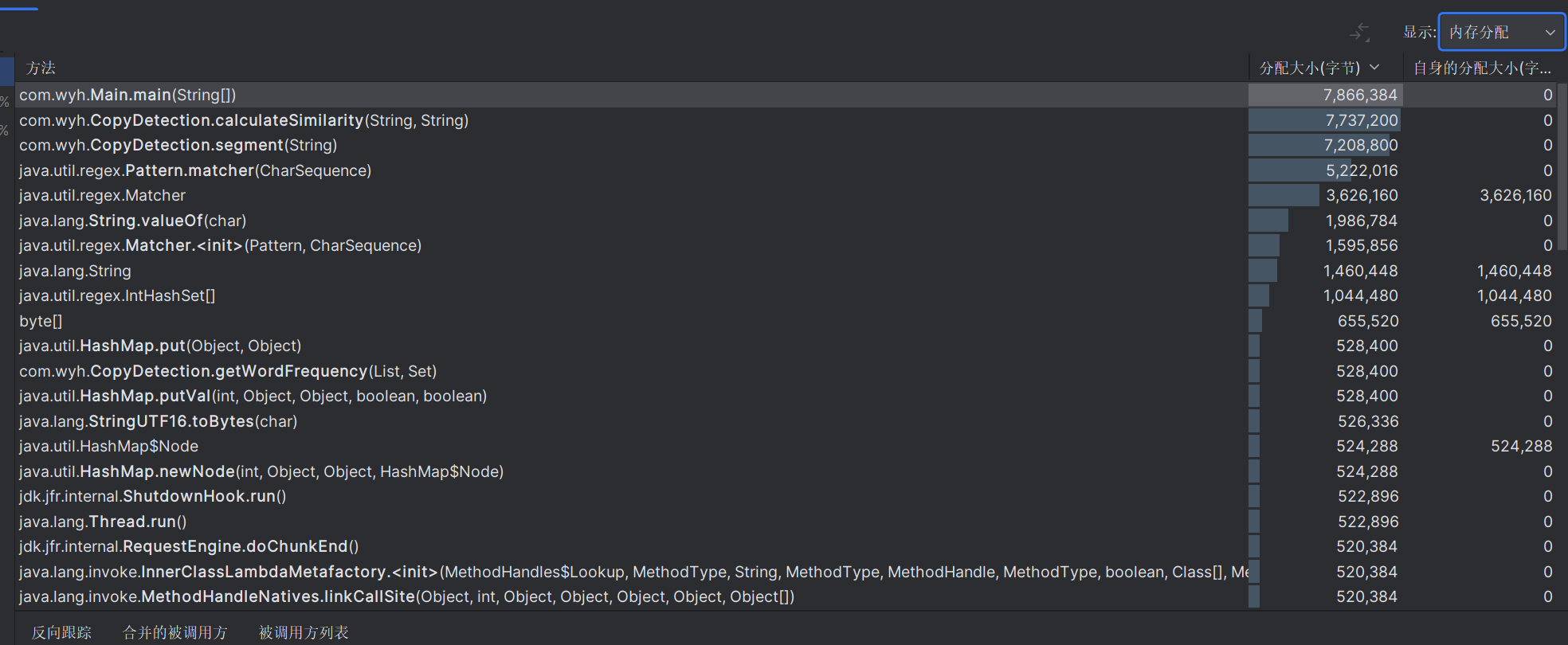
性能分析图:
程序中消耗最大的函数如图
![665129c30cfd5ba03814af99cb854ef3]()
-
-
部分单元测试展示
-
单元测试代码
验证算法在不同语义相似但表达不同的文本对上的表现
分别测试对同义词和近义词的识别能力、对句式结构调整的的鲁棒性、细节信息一致性的捕捉包括同义表达 信息重组 信息压缩、用词差异大但场景高度相似。
public class TestFunction { CopyDetection copyDetection = new CopyDetection(); FileOperation fileOperation = new FileOperation(); String outputPath = "D:\\YTUniversity\\result.txt"; /** * 写入文件 * @param similarity */ public void calculateSimilarity(double similarity) throws IOException { String result = String.format("%.2f%%", similarity * 100); fileOperation.writeFile(outputPath, result); } public void testBasicFunction1() throws IOException { String originalText = "今天是星期天,天气晴,今天晚上我要去看电影。"; String copyText = "今天是周天,天气晴朗,我晚上要去看电影。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction2() throws IOException { String originalText = "我明天要去公园散步,如果不下雨的话。"; String copyText = "明天我要去公园散步,只要天气不下雨。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction3() throws IOException { String originalText = " 我今天非常忙碌,连午饭都没时间吃。"; String copyText = "我今天很忙,连吃午饭的工夫都没有。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction4() throws IOException { String originalText = "今天晚上我们吃面条,是我妈妈做的。"; String copyText = "今晚我们吃妈妈做的面条。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction5() throws IOException { String originalText = "我最近在学英语,感觉还挺有意思的。"; String copyText = "最近我在学习英语,觉得挺有趣的。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction6() throws IOException { String originalText = "我每天坐地铁上班,大概需要四十分钟。"; String copyText = "每天我乘地铁去公司,大约要花四十分钟。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction7() throws IOException { String originalText = "我哥哥下个月要回国,从美国回来。"; String copyText = "下个月我哥哥要从美国回来了。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction8() throws IOException { String originalText = "我哥哥下个月要回国,从美国回来。"; String copyText = "下个月我哥哥要从美国回来了。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction9() throws IOException { String originalText = "下午两点有个会议,在第三会议室。"; String copyText = "下午两点在第三会议室开会。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } public void testBasicFunction10() throws IOException { String originalText = "他沿着河岸慢跑,清晨的微风轻轻拂过他的面颊。"; String copyText = "早晨,他在河边跑步,感受着凉爽的微风迎面吹来。"; double similarity = copyDetection.calculateSimilarity(originalText, copyText); calculateSimilarity(similarity); } }-
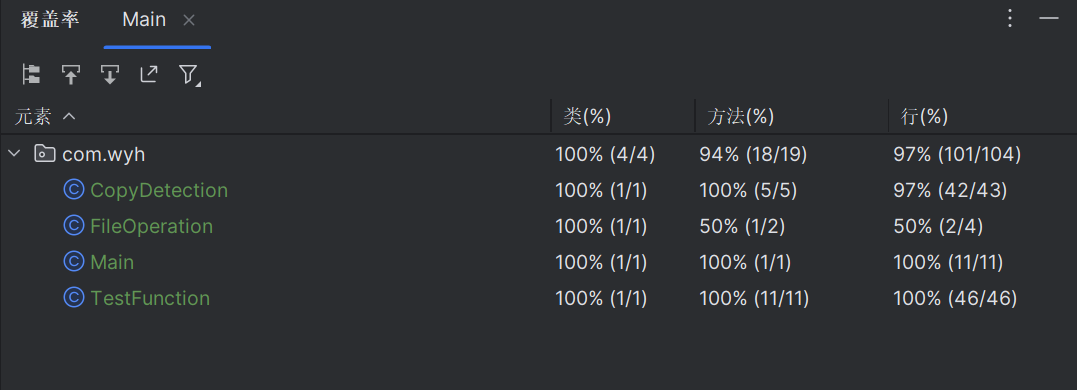
测试覆盖率截图
![c6f3b182f215215691ddc8e3a89b15fc]()
-
-
部分异常处理说明
处理文件时出错使用try-catch语句,只捕获
IOException将可能抛出IO异常的操作集中在一个try块中,覆盖文件读写操作,防止因文件操作失败导致程序崩溃![ec7d9d2c-2d5c-49ce-a41a-e699b044e2a3]()
-
总结与改进
- 总结:实现简洁依赖任何外部库,内存占用小,适合资源受限环境,专门针对中文特点设计,单字分词绕过传统分词器的准确性问题。技术方面拥有于词袋模型 + 余弦相似度的基础模型;简单但有效的分词策略;有预处理,比如中文停用词过滤、非中文字符去除。适用于短文本相似度计算、资源受限环境下的文本去重等场景。
- 改进:受限于技术与功能,可改进识别同义词语义理解的功能;增强词序敏感性和段落结构分析能力;可以增加繁体字、全角半角等字符的预处理;使用稀疏向量等优化技术,优化性能。