

初入机器学习
最近一直在恶补机器学习的相关知识。所以今天就写篇笔记来记录自己第一次学习机器学习的相关知识。
初入机器学习
顾名思义:机器学习最初的含义是希望机器能够像人一样聪明的学习,并且能够给出相应的学习结果。举个例子,如果你需要设计一个天猫精灵系统,你不用机器学习的方法,那么你就要设置很多的if规则,这些if规则称为手工规则。假设其中有一条规则是这样的,if "开灯" then "打开灯",即你希望天猫精灵听到含义开灯的词语,就把灯打开。但是,这个是有缺陷的,比如说,你对机器说"不要开灯",机器也会帮你把灯打开。除此之外,人为创造的规则是会带来局限性:比方说,人为规则归根到底还是由人在学习,而每个人的学习都是有限的,不可能学习到所有的可能,因此你需要大量的人工去帮学习,但是人力始终是有限的,并且这样的成本会非常大,所以这个人工规则的创造是非常不可取的。
 图片来源于facebook,侵删
图片来源于facebook,侵删
这张来自facebook的漫画很形象的说明了人工规则下的学习弊端,一个人工智能机器人,它非常的智能,当有一个观众问它采用了什么神经网络的时候,把它破开来一看,全是由if规则组成的。
因此,我们真正要做的AI,并不是这种人工规则下的AI,而是让机器去真正的学习,也就是machine learning。所谓的机器学习,就是你写了一个程序,使得机器能够自动的去学习相关的知识特性。为了能够更加通俗的理解机器学习,我们引用一张图
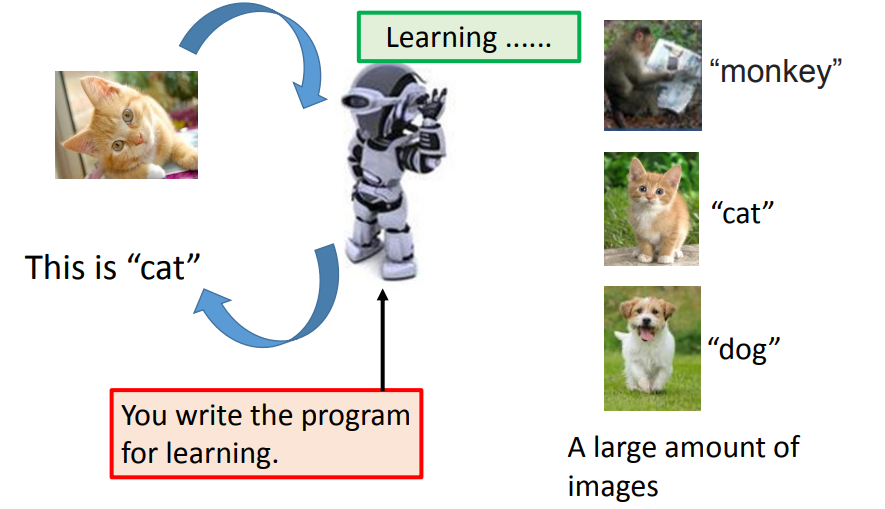
图片来源于datawhale开源官网提供,侵删
你在写的程序中,你给程序大量的图片去学习,程序学习到图片相关的特征之后,你在输入新的图片,程序就会告诉你相应的结果。那么我们该写什么样的程序呢?
所谓的机器学习的程序,实际上就是在寻找一个函数function,该函数就是在你输入一段语音之后,能够处理并给出一段文字,你输入一张图片后,能告诉你相应的图片内容
因此,机器学习的过程就是找到这个函数。
每个函数其实是由变量和参数的线性组合形成的,参数不同,对应的函数也不同,因此我们会有大量的函数出现,我们称为函数集,也就是模型。在训练集当中,我们会将训练数据给到函数集中,然后找到函数集中效果最好的那个函数,然后将函数的参数记录下来用于接下来测试集的使用,在测试集中,我们用训练集得到的最优函数来测试函数的泛化性。如图所示
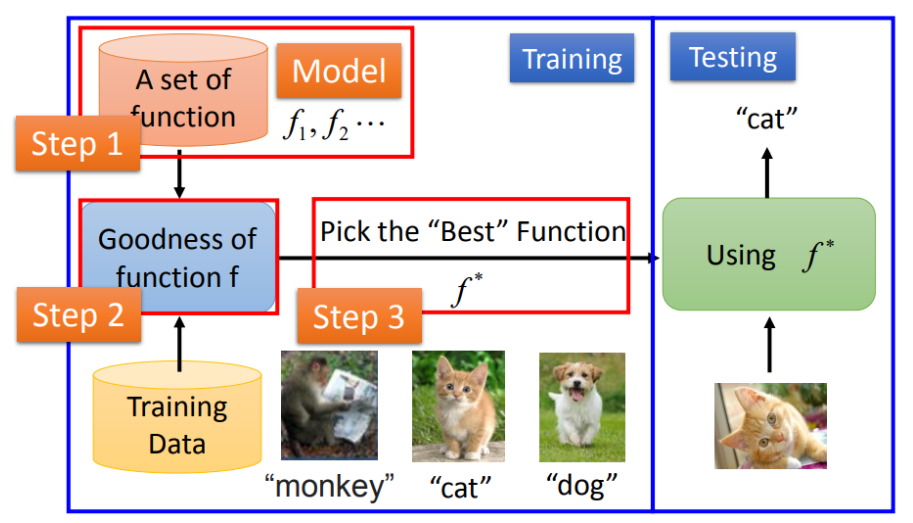
图片来源datawhale开源官网,侵删
机器学习相关技术
机器学习主要分为监督学习,无监督学习,半监督学习,迁移学习和强化学习。如下图:
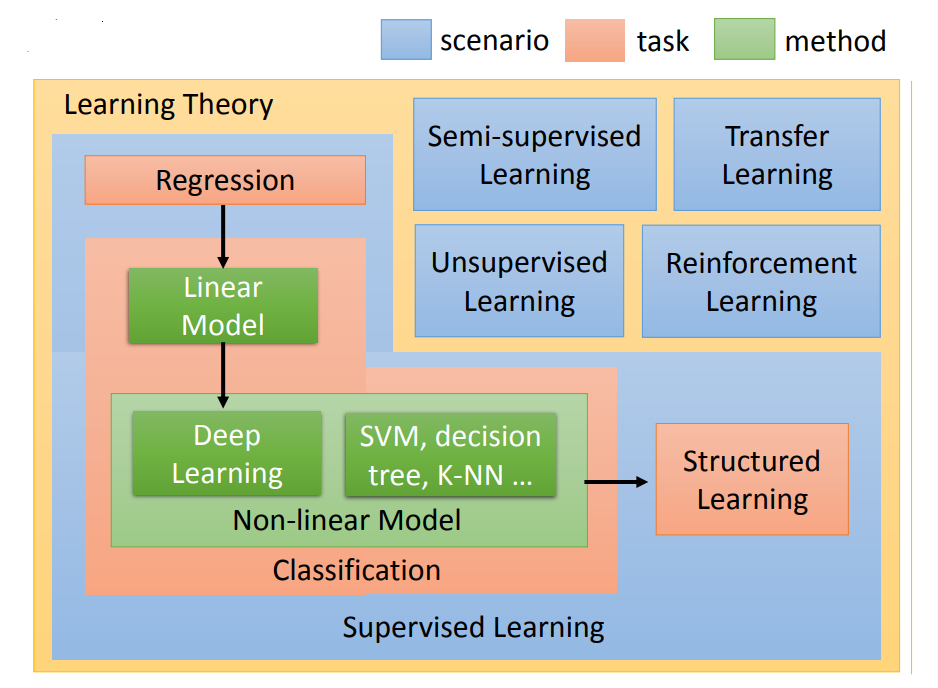
图片来源 datawhale官网开源 侵删
监督学习
监督学习又分为回归,分类学习和结构化学习。
我们首先来了解一下回归。所谓的回归就是我们在输入数据后,machine能够找到一个最优函数,该最优函数能够最大程度的拟合我的训练集数据,并且返回我输入数据对应的预测值。在最优函数的预测下,该预测值和我的真实值得误差会相对较小。
分类学习:分类学习和回归学习不一样,回归学习是返回一个数值,而分类学习返回得是一个类别。也就是当我输入一个样本的时候,machine能够在分类模型里面找到最优函数,并且返回该样本所属的类别。其中分类学习又分为二分类学习和多分类学习。其中主要差别如下图:
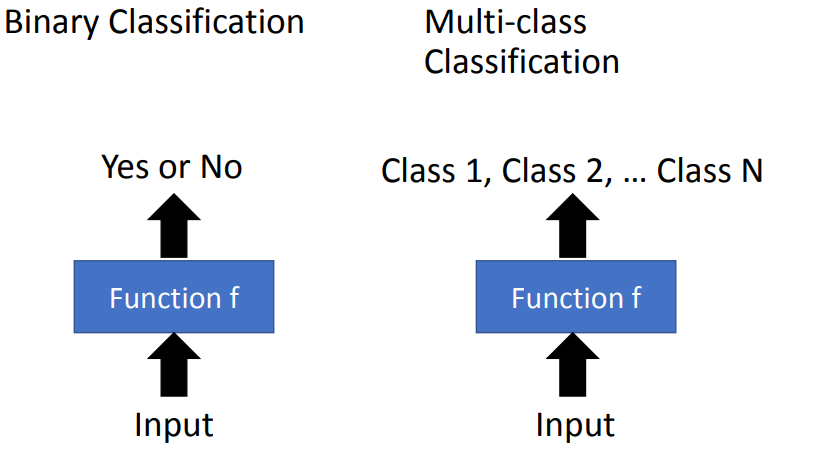
图片来源 datawhale官方开源 侵删
结构化学习
监督学习下的结构化学习,其实是人们常常忽视的一种学习模式。结构化学习就是我们输入的数据和输出的数据不是一个结构。在回归和分类学习中,我们输入的是向量,输出的也是向量,而在结构化学习中,输入的可以是序列,输出的也可以是序列。比方说,在物体检测中,我们输入的是一个图片向量,但是输出的是一个坐标边界。具体它如何实现的,我们可以后面再详细学习一下。
无监督学习
无监督学习就是输入数据没有任何标签的情况下,让机器去学习训练集的特征。举个很简单的例子,当我给机器输入了大量的数据,但是每个数据并不知道是什么图片,当machine学习到这些图片之间的关联性之后,我输入一个新的图片,能够识别出相应的图片内容并输出。
半监督学习
半监督学习是结合了监督学习和无监督学习。它拥有少量的带标签数据和大量的无标签数据。常用的做法是先用带标签的数据去学习,然后通过少量的带标签数据学习的模型后,用模型去训练无标签数据,之后扩充标签数据集,这个就是半监督中的自训练方法。当然,半监督学习还有很多方法,比如协同训练,帮助训练等等
迁移学习
半监督学习能够减少标签数据的使用,无监督学习完全不需要标签数据。除这两个之外,迁移学习也是减少带标签数据的一种方法。迁移学习的思想在于:我们有少量的带标签数据,和大量的其他数据,其他数据中可能有标签,可能无标签,并且其他数据集中的数据可能和带标签的数据并不相关,而如何通过一堆其他的数据来帮助我们去训练模型,这个是迁移学习要解决的问题。
强化学习
在监督学习和无监督学习中,当我们输入一个样本,machine会返回一个向量给我们,或者返回一个值。但是在强化学习中,你输入一个向量给机器,机器只会返回一个数字,该数值表示的意思是machine对于该数据的一个评价值,即机器对于这个样本处理是做的好还是不好。强化学习有些类似于生活中的工作,你对于工作的完成情况,领导只会告诉你做的不好,但是领导并不会告诉你哪里做的不好。但是监督学习和无监督学习就像学生在学校一样,当你完成的不好的时候,你的老师或者同学会告诉你哪里做的不好,并帮你改正。
我们之前看到的Alpha Go就是监督学习+强化学习的结合,监督学习用来不断的学习过去的历史棋谱样本,使得Alpha Go能够再自动的学习到下次的特征,使得每一步下在都能够定位,而强化学习能够在Alpha Go下棋失败的时候,告诉机器,它这次做的不好,但是并不会告诉它哪里不好,因此需要重新再次监督学习。
最后总结一下
本篇文章关于机器学习的介绍来自于李宏毅老师的机器学习相关介绍,本人只是在学习的基础上进行的总结,后面知识扩充之后,会再次进行填补的。本人小白一个,如果存在一些问题,希望大佬们提出来,我会尽量改正的。最后请大家文明评论发言,我是五毛,一个爱科研的小白研究生。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号