

机器学习sklearn(78):算法实例(三十五)回归(七)线性回归大家族(五)多重共线性:岭回归与Lasso(二)Lasso
3 Lasso
3.1 Lasso与多重共线性




3.2 Lasso的核心作用:特征选择

import numpy as np import pandas as pd from sklearn.linear_model import Ridge, LinearRegression, Lasso from sklearn.model_selection import train_test_split as TTS from sklearn.datasets import fetch_california_housing as fch import matplotlib.pyplot as plt housevalue = fch() X = pd.DataFrame(housevalue.data) y = housevalue.target X.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目" ,"平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"] X.head() Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420) #恢复索引 for i in [Xtrain,Xtest]: i.index = range(i.shape[0]) #线性回归进行拟合 reg = LinearRegression().fit(Xtrain,Ytrain) (reg.coef_*100).tolist() #岭回归进行拟合 Ridge_ = Ridge(alpha=0).fit(Xtrain,Ytrain) (Ridge_.coef_*100).tolist() #Lasso进行拟合 lasso_ = Lasso(alpha=0).fit(Xtrain,Ytrain) (lasso_.coef_*100).tolist()



#岭回归进行拟合 Ridge_ = Ridge(alpha=0.01).fit(Xtrain,Ytrain) (Ridge_.coef_*100).tolist() #Lasso进行拟合 lasso_ = Lasso(alpha=0.01).fit(Xtrain,Ytrain) (lasso_.coef_*100).tolist()
这样就不会报任何错误了。
#加大正则项系数,观察模型的系数发生了什么变化 Ridge_ = Ridge(alpha=10**4).fit(Xtrain,Ytrain) (Ridge_.coef_*100).tolist() lasso_ = Lasso(alpha=10**4).fit(Xtrain,Ytrain) (lasso_.coef_*100).tolist() #看来10**4对于Lasso来说是一个过于大的取值 lasso_ = Lasso(alpha=1).fit(Xtrain,Ytrain) (lasso_.coef_*100).tolist() #将系数进行绘图 plt.plot(range(1,9),(reg.coef_*100).tolist(),color="red",label="LR") plt.plot(range(1,9),(Ridge_.coef_*100).tolist(),color="orange",label="Ridge") plt.plot(range(1,9),(lasso_.coef_*100).tolist(),color="k",label="Lasso") plt.plot(range(1,9),[0]*8,color="grey",linestyle="--") plt.xlabel('w') #横坐标是每一个特征所对应的系数 plt.legend() plt.show()

3.3 选取最佳的正则化参数取值



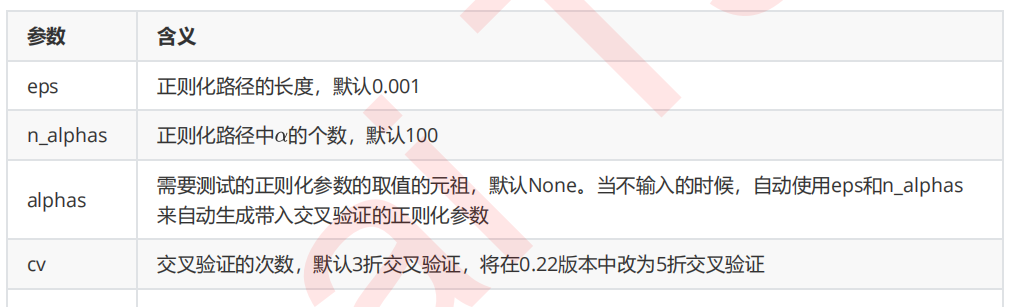

来看看将这些参数和属性付诸实践的代码:
from sklearn.linear_model import LassoCV #自己建立Lasso进行alpha选择的范围 alpharange = np.logspace(-10, -2, 200,base=10) #其实是形成10为底的指数函数 #10**(-10)到10**(-2)次方 alpharange.shape Xtrain.head() lasso_ = LassoCV(alphas=alpharange #自行输入的alpha的取值范围 ,cv=5 #交叉验证的折数 ).fit(Xtrain, Ytrain) #查看被选择出来的最佳正则化系数 lasso_.alpha_ #调用所有交叉验证的结果 lasso_.mse_path_ lasso_.mse_path_.shape #返回每个alpha下的五折交叉验证结果 lasso_.mse_path_.mean(axis=1) #有注意到在岭回归中我们的轴向是axis=0吗? #在岭回归当中,我们是留一验证,因此我们的交叉验证结果返回的是,每一个样本在每个alpha下的交叉验证结果 #因此我们要求每个alpha下的交叉验证均值,就是axis=0,跨行求均值 #而在这里,我们返回的是,每一个alpha取值下,每一折交叉验证的结果 #因此我们要求每个alpha下的交叉验证均值,就是axis=1,跨列求均值 #最佳正则化系数下获得的模型的系数结果 lasso_.coef_ lasso_.score(Xtest,Ytest) #与线性回归相比如何? reg = LinearRegression().fit(Xtrain,Ytrain) reg.score(Xtest,Ytest) #使用lassoCV自带的正则化路径长度和路径中的alpha个数来自动建立alpha选择的范围 ls_ = LassoCV(eps=0.00001 ,n_alphas=300 ,cv=5 ).fit(Xtrain, Ytrain) ls_.alpha_ ls_.alphas_ #查看所有自动生成的alpha取值 ls_.alphas_.shape ls_.score(Xtest,Ytest) ls_.coef_

本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14965128.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号