

ALINK(七):ALINK使用技巧(二)
4 Alink如何读写文本数据【Alink使用技巧】
Alink文本读写组件使用起来非常简单,每个换行符对应一条数据,只需指定文件的路径即可。譬如,我们想看一下iris数据,但不想花时间详细定义其数据列名及类型,就可以将其每条数据简单地看作一行文本,使用TextSourceBatchOp,并设置文件路径的参数。
iris_text = TextSourceBatchOp().setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data") iris_text.firstN(5).print()
输出结果为:

再举一个例子,在机器学习中经常需要将打好标签的数据拆分为训练集和验证集,由于拆分操作中每条记录的内容没有被改变,我们还是可以将每条记录都看作单行文本,并按文本的方式保存数据集。从而用更简洁的脚本,完成数据拆分的任务。运行脚本如下,SplitBatchOp为数据拆分算子,其参数Fraction即为拆分比例,
spliter = SplitBatchOp().setFraction(0.9) spliter.linkFrom(iris_text) spliter.link( TextSinkBatchOp().setFilePath("/Users/yangxu/flinkml/data/iris/iris_part1.data") ) spliter.getSideOutput(0).link( TextSinkBatchOp().setFilePath("/Users/yangxu/flinkml/data/iris/iris_part2.data") ) BatchOperator.execute()
执行完成后,我们还可以通过TextSourceBatchOp,读取打印一下iris_part2.data的数据,检查一下效果。
TextSourceBatchOp().setFilePath("/Users/yangxu/flinkml/data/iris/iris_part2.data").print()
输出结果如下,刚好15条数据,占iris数据集的10%

5 Alink如何读写Libsvm格式数据【Alink使用技巧】
LIBSVM数据格式就是LIBSVM(https://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html)使用的数据格式,是机器学习领域中比较常见的一种形式。其格式定义如下:
<label> <index1>:<value1> <index2>:<value2> ...
第一项<label> 是训练数据集的目标值,对于分类问题,用整数做为类别的标识(对于2分类,多用{0,1}或者{-1,1}表示;对于多分类问题,常用连续的整数,譬如用{1,2,3}表示3分类的各个类别);对于回归问题,目标值是实数。其后是由若干索引<index>和数值<value>对(以冒号“:”作为分隔符)构成,各项以空格作为分隔符。索引<index>是以1开始的整数,可以是不连续的;数值<value>为实数。
下面是几条符合LIBSVM格式的数据。
1 1:-0.555556 2:0.5 3:-0.79661 4:-0.916667 1 1:-0.833333 3:-0.864407 4:-0.916667 1 1:-0.444444 2:0.416667 3:-0.830508 4:-0.916667 1 1:-0.611111 2:0.0833333 3:-0.864407 4:-0.916667 2 1:0.5 3:0.254237 4:0.0833333 2 1:0.166667 3:0.186441 4:0.166667 2 1:0.444444 2:-0.0833334 3:0.322034 4:0.166667
注意这条数据:
2 1:0.5 3:0.254237 4:0.0833333
没有索引值为2的项,表明第2个特征值为0。
我们将https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/multiclass/iris.scale下载到本地,命名为iris.scale.libsvm。通过调用LibSvmSourceBatchOp读取数据,只需指定一个参数,即文件的路径。并取其前3条数据进行打印显示。
iris_libsvm = LibSvmSourceBatchOp()\
.setFilePath("/Users/yangxu/alink/data/iris/iris.scale.libsvm")
iris_libsvm.firstN(3).print()
iris_libsvm = LibSvmSourceBatchOp()\ .setFilePath("/Users/yangxu/alink/data/iris/iris.scale.libsvm") iris_libsvm.firstN(3).print()
输出结果如下,最左边为打印显示的数据索引号,接下来是数据的标签列(列名自动命名为label),然后是数据的特征数据列(列名自动命名为features)。

下面,我们对原始的数据采样10条数据,然后使用LibSvmSinkBatchOp保存采样的结果,注意,这里除了保存的路径还要指定三个参数,前两个是数据的标签列名称和特征数据列名称,最后一个参数OverwriteSink,表示保存操作执行时,如果目标文件已经存在,是否进行覆盖。在脚本的最后,调用BatchOperator.execute(),执行任务。
iris_libsvm \ .sampleWithSize(10) \ .link( LibSvmSinkBatchOp()\ .setFilePath("/Users/yangxu/alink/data/iris/iris.scale.sample.libsvm")\ .setLabelCol('label')\ .setVectorCol('features')\ .setOverwriteSink(True) ) BatchOperator.execute()
最后,我们验证一下保存的结果文件,即读取iris.scale.sample.libsvm并打印输出。
LibSvmSourceBatchOp().setFilePath("/Users/yangxu/alink/data/iris/iris.scale.sample.libsvm").print()

6 批式CSV数据读取【Alink使用技巧】
基本操作
我们先下载个csv文件用作后面的测试数据。 将数据文件 http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data下载到本地,文件路径为 /Users/yangxu/flinkml/data/iris/iris.data,使用文本编辑器打开如下所示,每行为一条数据,每条数据包括4个数值字段和一个字符串字段,各字段间使用逗号分隔。

读取本地数据
使用CsvSourceBatchOp可以批式读CSV格式文件,其必填的两个参数为:filePath和schemaStr。filePath为CSV格式文件所在的路径;schemaStr为数据各字段的名称和类型。关于Schema String更多的介绍可以参见Alink Schema String简介.
可以使用如下脚本,读取数据,并取前5条数据打印显示出来。
source_local = CsvSourceBatchOp()\ .setFilePath("/Users/yangxu/flinkml/data/iris/iris.data")\ .setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string") source_local.firstN(5).print()
数据打印显示如下:
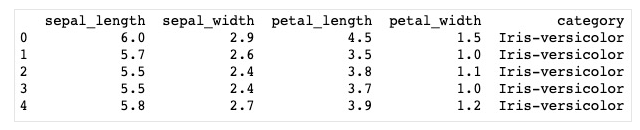
注意:CsvSourceBatchOp必填的参数filePath和schema进行赋值,filePath为本地文件存储路径"/Users/yangxu/flinkml/data/iris/iris.data",schema为iris数据集的列名和类型信息,共有5个字段:sepal_length, sepal_width, petal_length, petal_width, category;其数据类型分别为double, double, double, double, string
读取网络数据
相对于前面介绍的读取本地CSV数据,我们只需将数据存储路径参数filePath,赋值为http路径地址即可。脚本如下:
source_url = CsvSourceBatchOp()\ .setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data")\ .setSchemaStr("sepal_length double, sepal_width double, petal_length double, petal_width double, category string") source_url.firstN(5).print()
数据打印显示如下:

参数详细说明
Alink CsvSourceBatchOp提供了丰富的读取功能,具体内容可以参阅其参数说明文档:
https://github.com/alibaba/Alink/blob/master/docs/cn/csvsourcebatchop.md
更复杂的例子
对于葡萄酒品质数据集:http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv,我们将其下载达到本地,可以看到其文件内容。

第一行为数据列名的说明,第二行开始是数据,可以看到都是数值类型,各个数之间用分号“;”进行分隔。
我们可以通过设置参数ignoreFirstLine为True,略过第一行;并且可以设置字段分隔符参数fieldDelimiter为分号“;”。另外,由于列名不能包含空格,所以由文件第一列转化来的列名需要进行相应处理,这里我们将其写为驼峰形式;并加上数据类型,这里都是double类型,构成了数据集的SchemaStr。具体的脚本如下:
wine_url = CsvSourceBatchOp()\ .setFilePath("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv")\ .setSchemaStr("fixedAcidity double,volatileAcidity double,citricAcid double,residualSugar double,"+\ "chlorides double,freeSulfurDioxide double,totalSulfurDioxide double,density double,"+\ "pH double,sulphates double,alcohol double,quality double")\ .setFieldDelimiter(";")\ .setIgnoreFirstLine(True); wine_url.firstN(5).print()
数据打印显示如下:

可以看到由于每行的数据较多,在显示的时候进行了分段显示,每段数据可以由其最左方的行索引编号关联。
本文来自博客园,作者:秋华,转载请注明原文链接:https://www.cnblogs.com/qiu-hua/p/14878161.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号