MySql的MVCC机制(含源码)
 记录学习MVCC机制时的一些问题和整理
记录学习MVCC机制时的一些问题和整理
事务隔离级别遗留问题:
- 在读已提交的级别下,事务B可以读到事务A持有写锁的的记录,且读到的是未更新前的,为何写读没有冲突?
- 可重复读级别,事务B可以更新事务A已经获取读锁的记录,且更新后,事务A依然可以获取读锁,为何读-写-读没有冲突?
- 在可重复读级别,幻读没有产生
其中,前两个问题就是因为mvcc机制(读锁的一种优化机制),通过不加读锁,避免读写冲突,进而提高了性能。
而第三个问题,一部分原因是由MVCC机制保证的,还有一部分则是由锁来保证的;
在学习了解MVCC机制中遇到的问题:
- 为什么更新操作必须使用当前读?
- 只读事务突然更新的话,因为更新必须使用当前读,那是否需要重新生成事务id?
- 只读事务分配的事务id是什么东西?如何参与运作?
- readview的范围
- 知道了mvcc底层是undolog和readview后,怎么理解“版本”这个概念
- 在只读视图能查到其他事务已经删除并且提交的记录吗?
为什么要有MVCC机制?
- 在读已提交的级别下,由于是给读加锁来保证读已提交, 如果事务A持有写锁,为了保证读已提交,事务B必须等待事务A提交之后才可以读;其他的读事务也是这样的情况,效率太低
- 在可重复读级别,为了保证可重复读,如果事务A持有读锁,为了第二次读到的一样,其他所有写事务必须等待读完才可以,同样效率低
那么很自然的想到,无论读事务是先产生还是后产生,如果这个时候还存在写事务没有执行,或者需要执行;那么就应该让读事务读到目前最新的值,且写事务可以更新;只不过读事务在写事务提交更新后,依据隔离级别是否可见最新更新即可。这就是MVCC机制的核心能力,将读锁干掉。
MVCC机制核心组件
MVCC机制由版本链、undolog、readview三大核心构成
版本链
猜测很多人第一次看到MVCC的版本都是和我一样在各种各样的博客文章上,或者可能是在一些课程专栏或者《高性能mysql》这本书的mvcc部分看到的,那么在你的理解中,版本的底层是什么样子呢?
innodb引擎数据库中的每一条记录上,我们都可以认为上面有3个隐藏字段,分别是DB_ROW_ID(不在此次讨论范围),DB_TRX_ID和DB_ROLL_PTR,如下图一样
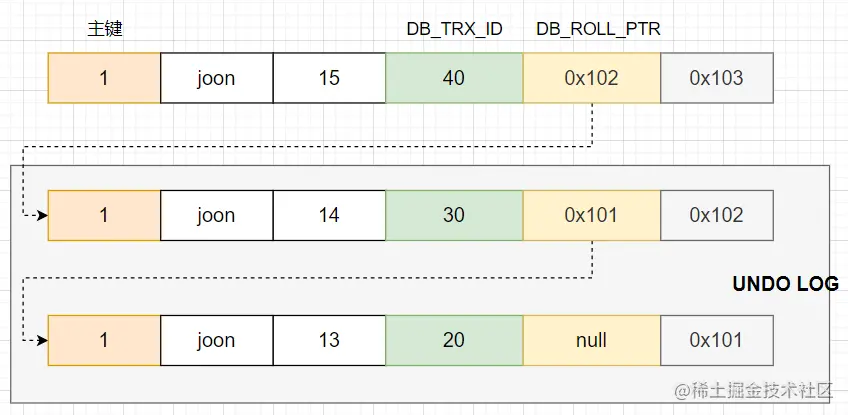
在我的理解中,
DB_TRX_ID就是插入或者更新时,当前事务的trx_id,由全局事务管理器分配的递增的一个id;
DB_ROLL_PTR存储的undolog中当前记录上一个版本的指针,先姑且记住这是一个指针。
当插入一条记录时
在这条记录的DB_TRX_ID填入当前事务的id,由于没有历史版本,所以DB_ROLL_PTR为空
当更新一条记录时
由于这个时候存在历史版本,所以需要将老版本的数据写到undolog里,然后构建指针
将DB_TRX_ID更新为当前事务的id,将DB_ROLL_PTR更新为刚才构建的指针,以及更新需要更新的字段。
当删除一条记录时(这个不太确定,主观猜测)
猜测是将老记录写到undolog,然后构建指针
新记录DB_TRX_ID更新为当前事务的id,将DB_ROLL_PTR更新为刚才构建的指针,但是没有需要更新的字段。
mysql不会立即删除,记录上有一个info_bits字段,会标记上删除标识(REC_INFO_DELETED_FLAG),后续由purge线程(不了解,姑且认为是个scheduleTask吧)删除
这样,当多次更新之后,新记录存储的永远都是最新操作的事务id,并通过指针指向了老版本,老版本还指向了更老的版本...等等,最终构成了一个版本链
Readview
理论:
在周志明老师的凤凰架构(或者极客时间的‘周志明的软件架构课’)中对mvcc简单介绍到
隔离级别是可重复读:总是读取 CREATE_VERSION 小于或等于当前事务 ID 的记录,在这个前提下,如果数据仍有多个版本,则取最新(事务 ID 最大)的。
隔离级别是读已提交:总是取最新的版本即可,即最近被 Commit 的那个版本的数据记录。
在mysql官网中是这么描述的
If the transaction isolation level is REPEATABLE READ (the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction. You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries.
With READ COMMITTED isolation level, each consistent read within a transaction sets and reads its own fresh snapshot.
翻译:
隔离级别是可重复读:在同一个事务中,一致性视图是在总是去第一次读取时生成的快照。
隔离级别是读已提交:事务中的每次读取都取自己新生成的快照。
相比之下,周老师形容的更贴近隔离级别的概念上,官方的描述则是底层的具体实现逻辑。
两者结合一下就是
可重复读:通过在每个事物只读取第一次select时生成的快照和undolog比较,根据一个可见性规则判断,是否可以读当前版本的记录,可以就返回,不行就继续比较再上一个版本,直到最老的版本;
读已提交:除了每次读取都会使用最新的快照,后面的都和可重复读的逻辑一样。
为什么我这里说的是可见性规则呢?
是因为周老师描述里“总是读取 CREATE_VERSION 小于或等于当前事务 ID 的记录”
很容易错误的理解为当前版本记录里的trx_id<=快照创建时的事务id(create_trx_id)就都可见,真正的判断逻辑并不只是一个create_trx_id就能搞定的。
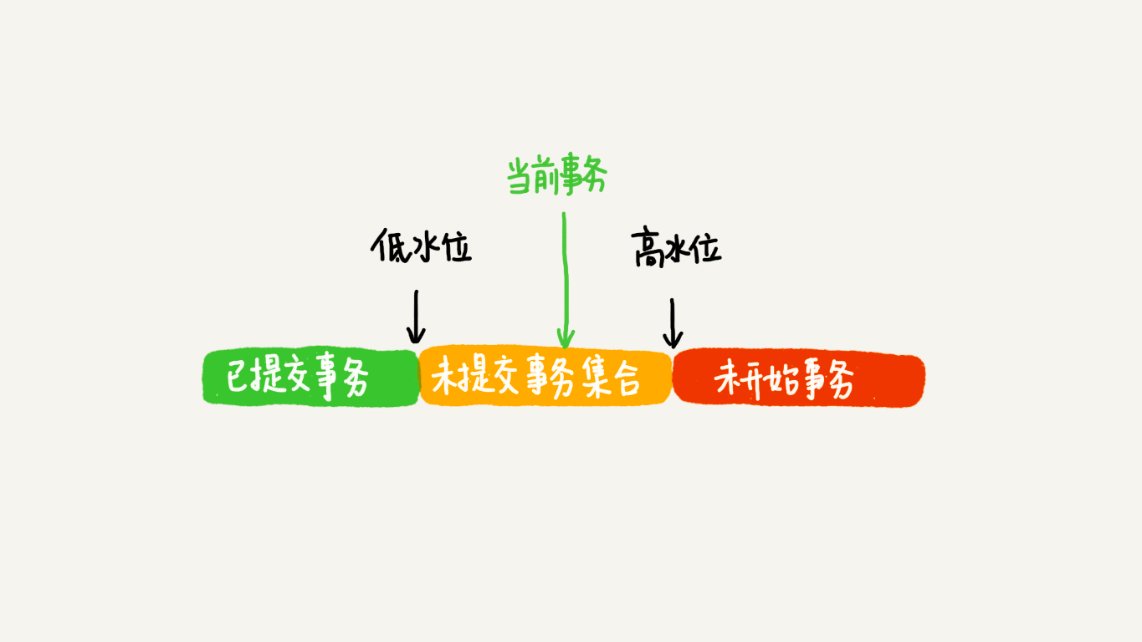
但这里先不展开讲,自己想一下为什么不行,下面的图可能会给你一点灵感,接下来我们先去读一下“可见性规则”的底层源码。
可见性规则底层实现
ReadView类
storage/innobase/include/read0types.h:47
//ReadView类
class ReadView {
...
private:
/** trx id of creating transaction, set to TRX_ID_MAX for free
views. */
//创建快照的时候,快照对应的事务id,只有含有写操作的才会分配真正的事务id
trx_id_t m_creator_trx_id;
/** Set of RW transactions that was active when this snapshot
was taken */
//活跃的读写事务id列表,从trx_sys->rw_trx_ids抄过来的
ids_t m_ids;
/** The read should not see any transaction with trx id >= this
value. In other words, this is the "high water mark". */
//赋值是即将分配的下一个事务id,所以大于等于这个id的记录对当前事务来说都是不可见的
trx_id_t m_low_limit_id;
/** The read should see all trx ids which are strictly
smaller (<) than this value. In other words, this is the
low water mark". */
//m_ids不为空就是ids.get(0),为空则是m_low_limit_id,所以小于这个事务id的就代表着快照建立的时候
//已经不是活跃事务了,即已经提交了,所以一定可以看到这些事务的改动记录
trx_id_t m_up_limit_id;
....
}
初始化赋值的时候
//read0read.cc
//row_search_mvcc -> trx_assign_read_view -> MVCC::view_open ->
void ReadView::prepare(trx_id_t id) {
ut_ad(trx_sys_mutex_own());
m_creator_trx_id = id;
m_low_limit_no = trx_get_serialisation_min_trx_no();
m_low_limit_id = trx_sys_get_next_trx_id_or_no();
ut_a(m_low_limit_no <= m_low_limit_id);
if (!trx_sys->rw_trx_ids.empty()) {
copy_trx_ids(trx_sys->rw_trx_ids);
} else {
m_ids.clear();
}
/* The first active transaction has the smallest id. */
m_up_limit_id = !m_ids.empty() ? m_ids.front() : m_low_limit_id;
ut_a(m_up_limit_id <= m_low_limit_id);
ut_d(m_view_low_limit_no = m_low_limit_no);
m_closed = false;
}
判断某个版本的记录是否可见?
//read0types.h
bool changes_visible(trx_id_t id,
const table_name_t &name) const {
ut_ad(id > 0);
//如果当前版本记录上的事务id(DB_TRX_ID)小于低水位或者等于当前事务,
//那么要么就是自己更改的,要么就是历史上已经提交了的,所以可以读到
if (id < m_up_limit_id || id == m_creator_trx_id) {
return (true);
}
check_trx_id_sanity(id, name);
//如果当前版本记录上的事务id(DB_TRX_ID)大于高水位,那么就是在当前快照生成后生成的事务,一律看不到
if (id >= m_low_limit_id) {
return (false);
//这一步我没有理解,
} else if (m_ids.empty()) {
return (true);
}
const ids_t::value_type *p = m_ids.data();
//二分查找,如果活跃的事务里面没有,那么就返回true
//这里我是这么理解的,[低水位,高水位]包含活水和死水,即活跃的事务和已经提交的事务
//假如存在事务1是活跃的,事物2是已提交的,事务3是活跃的,我们在事务4的时候开启快照,很明显我们只能读到事务2或者事务4的变更
//假如正在判断的是事务2,因为已经经过了上面的校验,
//所以我们知道当前版本记录的事务m_low_limit_id(高水位)>id>=m_up_limit_id(低水位),且不是当前事务;
//所以就需要判断事务只要不是活跃的,那么就一定是已经提交的事务,那么就可读
return (!std::binary_search(p, p + m_ids.size(), id));
}

在了解可见性规则之后我们知道,快照建立的时候会初始化几个属性,在查询的时候会通过changes_visible方法来判断是否可见,而调用这个方法的上层就是下面这两段逻辑,和我先前描述的类似,判断是否可以读当前版本的记录,可以就返回,不行就继续比较再上一个版本,直到最老的版本
//row0sel.cc#row_search_mvcc
if (srv_force_recovery < 5 &&
!lock_clust_rec_cons_read_sees(rec, index, offsets,
trx_get_read_view(trx))) {
rec_t *old_vers;
/* The following call returns 'offsets' associated with 'old_vers' */
err = row_sel_build_prev_vers_for_mysql(
trx->read_view, clust_index, prebuilt, rec, &offsets, &heap,
&old_vers, need_vrow ? &vrow : nullptr, &mtr,
prebuilt->get_lob_undo());
if (err != DB_SUCCESS) {
goto lock_wait_or_error;
}
if (old_vers == nullptr) {
/* The row did not exist yet in
the read view */
goto next_rec;
}
rec = old_vers;
prev_rec = rec;
ut_d(prev_rec_debug = row_search_debug_copy_rec_order_prefix(
pcur, index, prev_rec, &prev_rec_debug_n_fields,
&prev_rec_debug_buf, &prev_rec_debug_buf_size));
}
//lock0lock.cc#lock_clust_rec_cons_read_sees
bool lock_clust_rec_cons_read_sees(
const rec_t *rec, /*!< in: user record which should be read or
passed over by a read cursor */
dict_index_t *index, /*!< in: clustered index */
const ulint *offsets, /*!< in: rec_get_offsets(rec, index) */
ReadView *view) /*!< in: consistent read view */
{
ut_ad(index->is_clustered());
ut_ad(page_rec_is_user_rec(rec));
ut_ad(rec_offs_validate(rec, index, offsets));
/* Temp-tables are not shared across connections and multiple
transactions from different connections cannot simultaneously
operate on same temp-table and so read of temp-table is
always consistent read. */
if (srv_read_only_mode || index->table->is_temporary()) {
ut_ad(view == nullptr || index->table->is_temporary());
return (true);
}
/* NOTE that we call this function while holding the search
system latch. */
trx_id_t trx_id = row_get_rec_trx_id(rec, index, offsets);
return (view->changes_visible(trx_id, index->table->name));
}
事务的trx_id
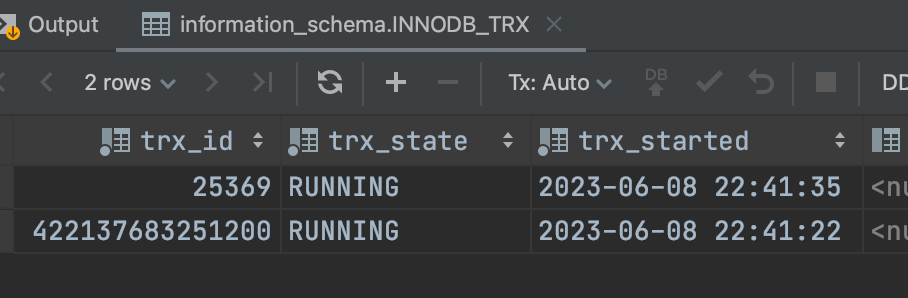
在我还没开始看mysql源码,只是跟着博客学习写用例测试的时候,我发现,开启事务进行了第一次查询之后,确实有生成事务id,但后面我更新了之后,原来的事务id变了;就像下面这个图一样,最开始只有查询的时候是比较长的这个id,但执行了一条update语句后,事务id变成了一个短的。
这个时候我就产生了很多疑问?同一个事务里,事务id怎么还能变呢?变的话changes_visible里面的比较怎么算?搜索了一下之后了解到,只读事务是不会生成事务id的,是假的!于是我又疑惑,那这个假id怎么参与changes_visible呢?也就是这个时候,我才下定决心去看源码,也借此理解了高低水位的设计,并认识到自己之前的理解是错误的。
先上结论
只读事务不会分配真正的事务id,他的值是0;
只读事务参与change_visable的时候,create_trx_id也确实是0,是通过m_up_limit_id(低水位)来判断是否可见的,只有在变成读写事务是,create_trx_id才会起效并应用;
因为值是0,在通过下面sql查询的时候,那串id只是展示的时候特殊处理的
select * from information_schema.INNODB_TRX;
//trx0trx.cc#trx_start_low
//这里可以看到只有读写事务才真正分配了id
else {
trx->id = 0;
if (!trx_is_autocommit_non_locking(trx)) {
/* If this is a read-only transaction that is writing
to a temporary table then it needs a transaction id
to write to the temporary table. */
if (read_write) {
trx_sys_mutex_enter();
ut_ad(!srv_read_only_mode);
trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed);
trx->id = trx_sys_allocate_trx_id();
trx_sys->rw_trx_ids.push_back(trx->id);
trx_sys_mutex_exit();
trx_sys_rw_trx_add(trx);
} else {
trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed);
}
} else {
ut_ad(!read_write);
trx->state.store(TRX_STATE_ACTIVE, std::memory_order_relaxed);
}
}
//trx0trx.ic
//这里是在展示的时候对只读事务的id做了处理
@return transaction id */
static inline trx_id_t trx_get_id_for_print(const trx_t *trx) {
/* DATA_TRX_ID_LEN is the storage size in bytes. */
static const trx_id_t max_trx_id = (1ULL << (DATA_TRX_ID_LEN * CHAR_BIT)) - 1;
ut_ad(trx->id <= max_trx_id);
/* on some 32bit architectures casting trx_t* (4 bytes) directly to
trx_id_t (8 bytes unsigned) does sign extension and the resulting value
has highest 32 bits set to 1, so the number is unnecessarily huge.
Also there is no guarantee that we will obtain the same integer each time.
Casting to uintptr_t first, and then extending to 64 bits keeps the highest
bits clean. */
return (trx->id != 0
? trx->id
: trx_id_t{reinterpret_cast<uintptr_t>(trx)} | (max_trx_id + 1));
}
生成快照时机(不太确定)
可重复读:只生成一次,后面继续使用
ReadView *trx_assign_read_view(trx_t *trx) /*!< in/out: active transaction */
{
ut_ad(trx_can_be_handled_by_current_thread_or_is_hp_victim(trx));
ut_ad(trx->state.load(std::memory_order_relaxed) == TRX_STATE_ACTIVE);
if (srv_read_only_mode) {
ut_ad(trx->read_view == nullptr);
return (nullptr);
} else if (!MVCC::is_view_active(trx->read_view)) {
trx_sys->mvcc->view_open(trx->read_view, trx);
}
return (trx->read_view);
}
读已提交:好像是用完就关,所以每次再获取就得新开,但是这里的关有两个地方调,不太确定上层是不是sql执行完的方法
ha_innodb.cc#store_lock 和ha_innodb.cc#external_lock
if (lock_type != TL_IGNORE && trx->n_mysql_tables_in_use == 0) {
trx->isolation_level =
innobase_trx_map_isolation_level(thd_get_trx_isolation(thd));
if (trx->isolation_level <= TRX_ISO_READ_COMMITTED &&
MVCC::is_view_active(trx->read_view)) {
/* At low transaction isolation levels we let
each consistent read set its own snapshot */
mutex_enter(&trx_sys->mutex);
trx_sys->mvcc->view_close(trx->read_view, true);
mutex_exit(&trx_sys->mutex);
}
}
快照读和当前读
快照读:当前执行的sql如果不存在锁,那么默认读到的就是readview里的快照,这种情况称之为快照读;
当前读:如果当前执行的sql存在锁,比如使用了lock in share mode,for update,或者是insert、update、delete操作,对于这种需要锁的sql,必须读取最新的视图,这种行为称之为当前读;
我个人理解只有在RR级别才需要区分对待,RC级别都是当前读;而且我认为二者的区别就只有加锁和不加锁这一个点
回答文章最开始的一些问题:
- 为什么更新操作必须使用当前读?
更新操作后的如果不回滚那没有事,如果要回滚,应该回滚到最新一次的提交,所以undo log里必须是最新的视图 - 只读事务突然更新的话,因为更新必须使用当前读,那是否需要重新生成事务id?
不算做重新,是只有在触发锁操作时会分配真正的事务id,只读事务分配的id其实就是0 - 只读事务分配的事务id是什么东西?如何参与运作?
没有作为判断条件,作为判断条件的是up_limit记录的是最小活跃id,小于他的才能读,正规的事务id分配的在readview结构里其实是creator_trxid,用来判断当前是否能被当前事务看见 - readview的范围
有这个疑问还是因为最开始对change_visable掌握的不够清晰。
之前想的场景是在事务A里,如果存在两条不同记录甚至不同表的查询,而事务B在第事务A两条查询中间的时候对第二条查询的记录做了更改并提交,那应该查到的是新的还是旧的。
其实应该是旧的,因为就算是第二条查询,最新版本的改动的事务id会大于等于事务A的高水位,因此只能查询到更老的undolog里的记录 - 知道了mvcc底层是undolog和readview后,怎么理解“版本”这个概念
创建版本肯定就是字段里那个隐藏字段,删除版本应该是回滚指针 - 在只读视图能查到其他事务已经删除并且提交的记录吗?
经测试是可以的
怎么解决的幻读?
在只读事务下,如上文所说的事务1读不到事务2的更新是因为事务2的版本号要大于当前快照的高水位,那对于新增的记录来说,其版本号也是同样的道理,因此事务1读不到比当前快照里的高水位高的,也就避免了幻读这种情况。
但是在当前读下,由于必须读取最新的结果,所以版本号一定是当前事务可见的,那么这个时候mysql的表现是什么样子呢?又是为什么是这样子呢?通过下面的实例来认识一下
simple表的初始情况
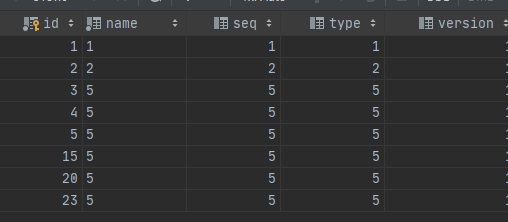
//console1
select * from simple;
select * from simple where id <10 lock in share mode ;
//console2
start transaction ;
insert into simple (id,name,seq,type) value (6,3,3,1);
这个时候理论上事务2应该可以顺利插入id为6的记录,毕竟我们虽然加了读锁;但是记录都不存在必然也锁不住;
但是我们会发现insert这条语句被阻塞了,在等待一会之后会报下面的错
Lock wait timeout exceeded; try restarting transaction
既然锁等待了,就必然存在一个锁,不过锁的部分我还需要再研究研究。
预计将在下一篇文章中介绍,敬请期待...
参考资料:
MySQL 8.0 MVCC 源码解析 - 掘金
https://dev.mysql.com/doc/refman/8.0/en/innodb-consistent-read.html
MySQL事务ID的分配时机_mysql事务id什么时候分配_哲学长的博客-CSDN博客
MYSQL innodb中的只读事物以及事物id的分配方式_ITPUB博客
Mysql如何实现隔离级别 - 可重复读和读提交 源码分析_mysql 可重复度源码_择维士的博客-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号