
[论文][表情识别]Relative Uncertainty Learning for Facial Expression Recognition
论文基本情况
发表时间及刊物/会议:2021 NeurIPS
发表单位:Beijing University of Posts and Telecommunications
问题背景
不确定性是用来描述模型对其推断结果的信任程度,我们希望模型给予错误的预测很高的不确定性,此时人们可以有针对性的进行干预,不确定性可以分为偶然不确定(数据不确定)和认识上的不确定(模型不确定)。其中,模型不确定的问题可以通过利用更多的训练数据消除,因此,本文主要聚焦于表情识别领域中由模糊图片和标签的不准确性(主观判断问题/噪声问题)导致的数据不确定问题。
论文创新点
通过 Relative Uncertainty Learning (RUL) 来解决模型预测结果不确定问题,此模型无需任何先验信息,相对不确定性是通过参照,比较之后得到的,
网络结构
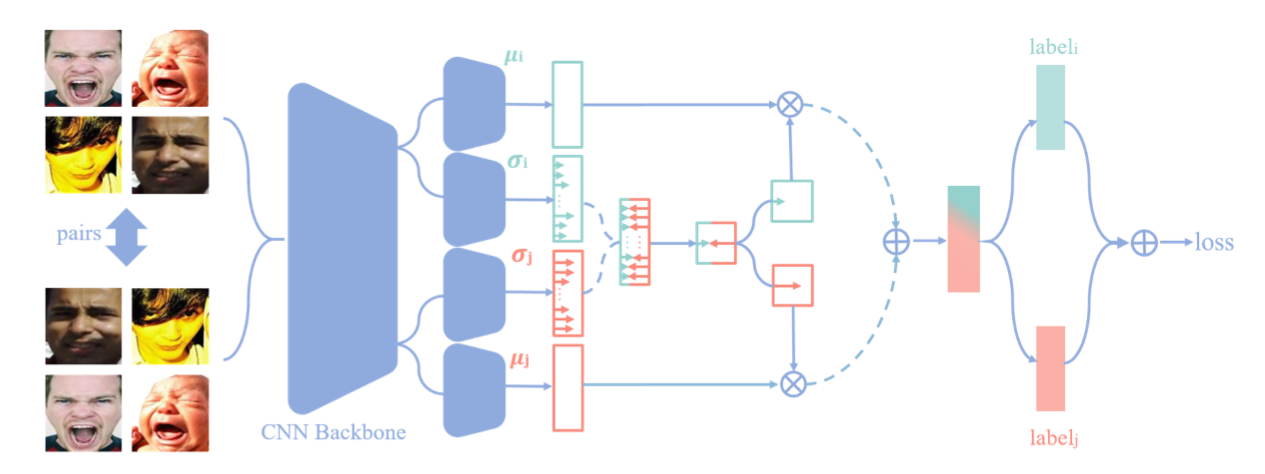
两个分支

通俗而言,即丢弃传统特征提取网络的最后一层,从倒数第二层开始,分两个分支,一个分支用于产生面部特征,另一个分支用于产生不确定向量,两个分支最后的输出维度一致,均为\(N \times D\),其中\(N\)和\(D\)分别表示batchsize大小和输出维度。
RUL模块
1)考虑到不确定向量的数值差异,为方便比较,我们先将两张图片对应的不确定性向量按照如下公式归一化。
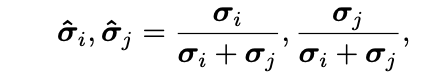
2)一张图片的不确定性向量维度为\(D\),我们将这\(D\)个数值取平均,由此估计一张图片的不确定性
3)将两张图片特征混合,采用图片的不确定性来对图片特征进行加权混合
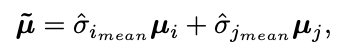
分类损失
当两张图片\(i,j\)送入网络中,对应标签分别为\(label_i,label_j\)
由上可知,不确定性大的图片获得的uncertainty value 更大,混合特征所占权重更大;不确定性小的图片获得的uncertainty value 更小,混合特征所占权重更小。
因此,将混合特征输入网络后,分别计算标签为\(label_i\)和\(label_j\)的损失,并将其相加作为总损失。
由此,在混合特征中,不确定性大的图片特征占比大,使得模型更容易从混合特征中识别出不确定性特征,不确定性小的图片特征占比小,但其特征性较强,模型同样可以识别出其特征。
思考:模型每次输入两张图片\(i,j\),将提取到的特征按照不确定权重加权后混合,再分别按照两张图片的真实标签计算损失,为了让损失减小,模型必须给更难分辨的图片对应的特征更大的权重,保证混合特征中相对更难分辨的图片特征更加明显,突出。而对于容易分辨,特征确定的图片而言,尽管混合特征中图片特证不明显,模型也能够正常分类,因此混合特征时权重较小。
实验
表1 人工噪声下三个数据集上的实验,由实验可以看出,当噪声比例越高,本方法相比于其他方法效果越好,说明本方法的鲁棒性。
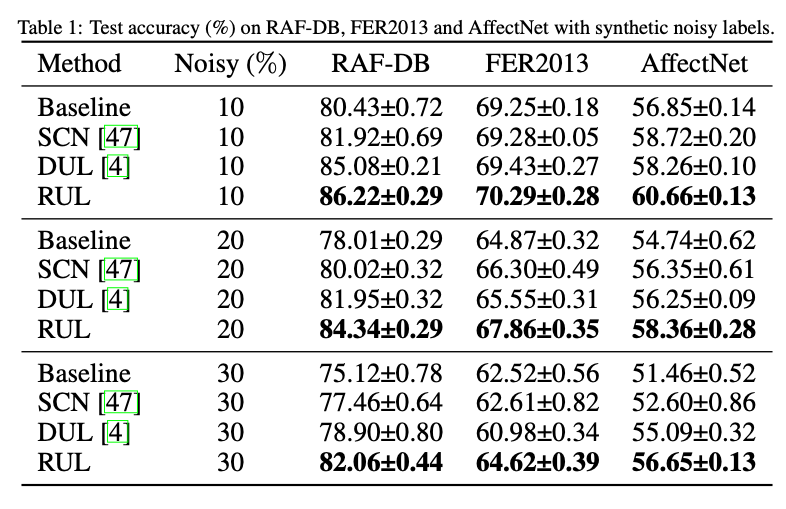
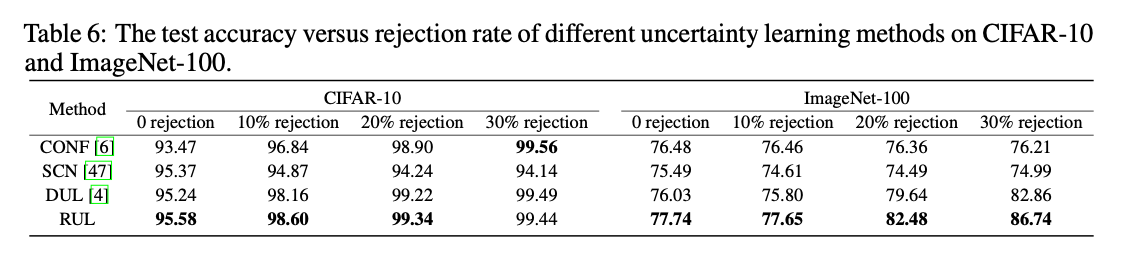
表2 Test accuracy (%) versus rejection rate结果,如果比例越高,效果越好,则证明这种估计不确定性的方法是有效的
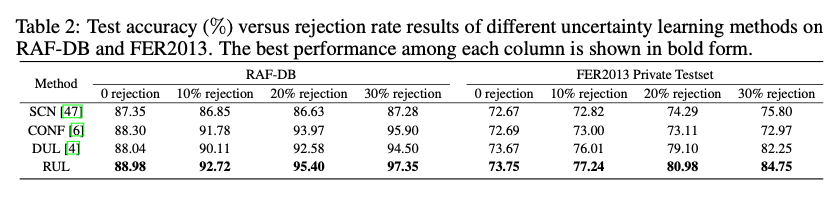
图3 使用t-SNE来可视化学习到的特征,相比之下,RUL的特征分布范围较小。因为RUL需要在混合特征中保留两张图片的最突出特征,因此范围较小。
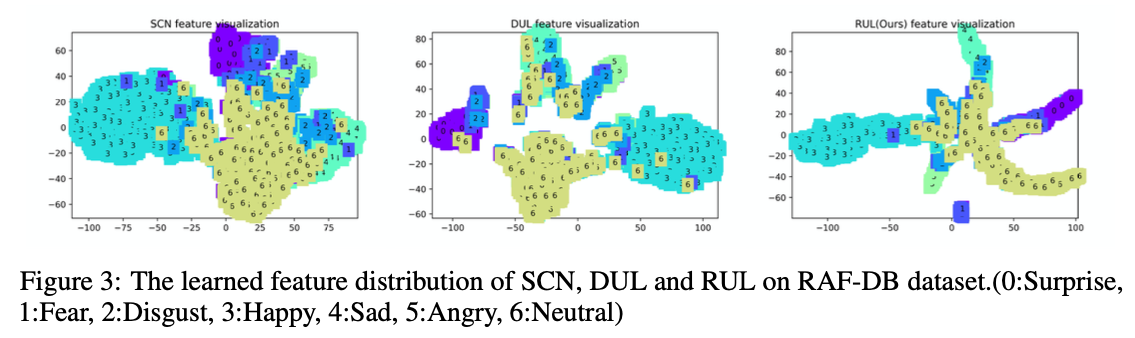
图4 不确定性数值展示

图5 不确定性数值和其他方法对比
由图可知,RUL学习到的不确定性相比其他方法数值较大,说明RUL可以降低神经网络强学习能力的负面影响。
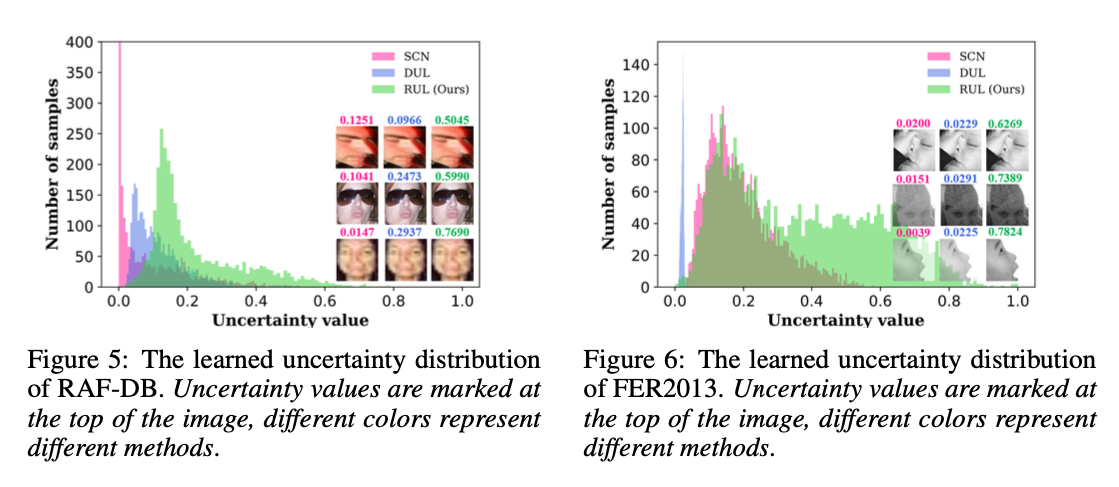
表3,4,5 和其他sota方法比较
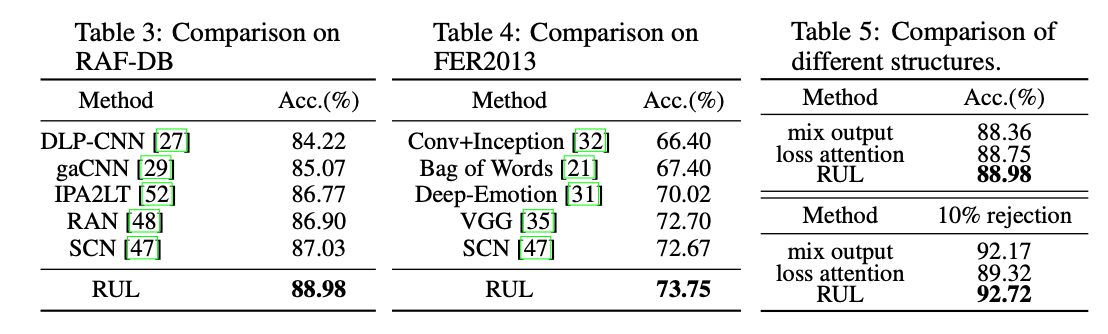
表 6 在自然场景图像分类任务上学习不确定性的表现

 浙公网安备 33010602011771号
浙公网安备 33010602011771号