
关于 序列化模块 json 的小问题和小理解!!!
2019-08-11 17:19 在上海的日子里 阅读(228) 评论(0) 收藏 举报问题引出1:
自定义 txt格式的文件data,数据内容过如下:
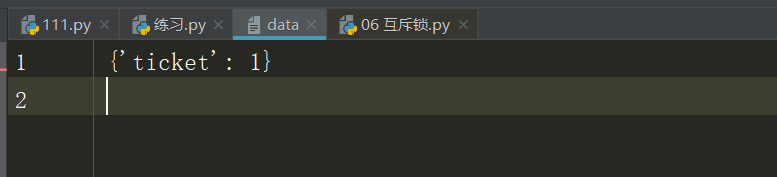
执行代码如下:
import json with open('data','r',encoding='utf-8') as f: data = f.read() print(type(data)) t_d = json.loads(data)
报错信息如下:

错误原因:
数据格式错误!写入数据的字典格式错误,字典内key value 值如果是字符串的话必须用 双引号才可以 被反序列化!
为什么数据内字典只有是双引号 “” 才可以被反序列化?
在解决上述问题之前我们再来了解一下 json 模块!
首先json模块里面有 dumps loads 和 dump load 4中内置方法,其中dump 、load 是关于文件操作的,意义与dumps loads 一样
dumps —— 是将其他数据类型的数据转化为json格式的字符串,也就是序列化json格式字符串
loads —— 是将json格式的字符串转化为其他数据类型的数据, 也就是将json格式字符串反序列化为原来的数据类型
代码演示如下:
d = {'ticket':1}
print(type(d)) # <class 'dict'>
# 将字典序列化成json格式字符串 注意:字典数据类型转化为json格式字符串后,key 值变成双引号
json_d1 = json.dumps(d)
print(type(json_d1)) # <class 'str'>
print(json_d1) # {"ticket": 1}
# 反序列化, 将json格式的字符串反序列化为原来的字典格式,key值单引号还原为原来的样子
json_d2 = json.loads(json_d1)
print(type(json_d2)) #<class 'dict'>
print(json_d2) # {'ticket': 1}
注意:
将字典进行序列化成json格式的字符串时, 原字典内的key值单引号变成了双引号!
所以凡是字典类型的数据被序列化时都会被变成双引号的样子!
至此回答上述问题:
在自定义数据时,字典数据类型格式的数据只有写成双引号才能被反序列化
问题引出2:
数据内容如下:

执行代码如下:
import json with open('data','r',encoding='utf-8') as f: data = f.read() print(type(data)) # <class 'str'> t_d = json.loads(data) # 为什么可以将文件内读取的内容直接进行反序列化 print(type(t_d)) # <class 'dict'> print(t_d.get('ticket')) # 1
关于“为什么可以将文件内容直接进行反序列化的操作”?
答:是因为我们自定义将字典数据写入文件的时候,就已经默认操作将该字典数据序列化成字符串格式了。特点:双引号
所以我们可以将其反序列化为字典格式,然后再进行字典数据类型的操作!!!!
提出该问题的深层原因是不了解为什么要使用 json?
为什么要使用序列化模块,原因如下:
只有字符串格式的数据才能写入文件,进而进行保存。但是我们希望被保存的数据在读出后能够还原成原来的数据类型,进而保持原有数据类型的功能!例如:字典
问题引出3:
数据内容:

json中loads 和load 有什么区别?
load 传入一个文件对象返回python数据类型,loads 传入json格式的字符串 返回python数据类型。
也可以理解为:
load 后面传入一个容器类型,可迭代对象,可以直接将里面的内容反序列化出来;
loads 后面要传入具体的json格式的字符串,然后将其反序列化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号