
day5 ---- 数据类型及常用方法(字符串、列表)
2019-07-03 15:15 在上海的日子里 阅读(357) 评论(0) 收藏 举报目录
一、数字型(整型、浮点型)
二、字符串
三、列表
四、补充前提知识
学习思路:
#======================================基本使用====================================== #1、用途 #2、定义方式 #3、常用操作+内置的方法 #======================================该类型总结==================================== #存一个值or存多个值 #有序or无序 #可变or不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
前提知识:
可变类型:值变了,内存地址id 不变,这样的称为可变类型。
不可变类型:值变了,内存地址 id 也改变,称为不可变类型。
两句话(需要注意):1、id相等,值一定相等!
2、id不相等,值不一定相等!
一、数字型
整型:int
基本使用:
1、用途:记录整型数据可以存储的内容,如银行卡号,QQ号等等
2、定义:age = 18 # age = int(18)
3、内置方法:
十进制转其他进制
# 10进制转其他进制 # 10进制转二进制 print(bin(12)) # 0b1100 0b表示后面的数字是二进制数 # 10进制转八进制 print(oct(12)) # 0o14 0o表示后面的数字是八进制数 14 >>> 1*(8**1) + 4*(8**0)) # 10进制转16进制 print(hex(12)) # 0xc 0x表示后面的数字是十六进制数
其他进制转10进制
# 其他进制转十进制 print(int('1100',2)) # int可以传第二个参数,表示的是第一个参数到底是什么进制 然后转成十进制 print(int('14',8)) print(int('c',16))
类型总结:
1、只能存一个值
2、因为只有一个值,所以无所谓有序无序
3、不可变类型:因为值不同id也不同
浮点型:float
基本使用:
1、用途:存储使用小数记录的数据内容,如圆周率、身高、体重等等非整数型数据。
2、定义:salary = 3.1 # salary = float(3.1)
3、内置方法:可以将纯数字型字符串转为浮点型数据
res = float('1.11') >>> 1.11
二、字符串
基本使用:
1、用途:描述性
2、定义:单引号,双引号,三引号
3、内置方法:
字符串内置方法--优先需要掌握的
1、按索引取值(正向取,反向取):只能取值
s = 'hello big baby!' print(s[0]) h print(s[-1]) !
2、切片(顾头不顾尾,步长):从一个长的字符串中截取一小段形成一个新的字符串


# 左边的固定就是头,右边固定就是位 没有说按数字来分头尾 s = 'hello big baby!' print(s[0:5]) hello print(s[0:10:2]) hlobg
了解负数取值
s = 'hello big baby!' print(s[-1]) # -1 代表字符串的尾部 ! print(s[0:10:-1]) # 切片取值默认是从左到右的,所以从0开始想-1取值的话,结果为空 print(s[10:0:-1]) # 切片起始定位在下标为10的位置,-1代表反方向0的位置取步长 b gib olle print(s[-1:-10:-1]) # -1代表字符串尾部,-10代表向左取值,步长为-1 !ybab gib
3、长度len(),统计字符串中字符的个数
s1 = 'CQUPT' len(s1) 5
4、成员运算 in 和not in :判断一个子字符串是否在一个大的字符串中
print('egon' in 'egon is a big sb and he is the first handsome man in hongqiao') True print('jason' not in 'egon is the first handsome man!') True
5、去掉字符串左右两边的字符 strip ,不管两边的
注意:内置方法一律使用句点符 “.”
username = input(输入你的名字:").strip() # strip()方法可以去掉输入字符两边的空格等 if username == 'jason': print('欢迎登录!')
name1 = ' jason' name2 = 'jason' name1 == name2 # 返回False,两个变量不相等,name1中有空格 False name1 = ' jason'.strip() # 去掉两端的空格 name2 = 'jason' name1 == name2 True
去掉字符串中左右两端特定的字符,如
1 name = '&&&egon$$jason&&' 2 name.strip('&') 3 'egon$$jason'
去字符串左边字符 lstrip() ,去掉字符串右边字符 rstrip()
1 name = '&&&egon$$jason***' 2 name.lstrip('&') 3 'egon$$jason***' 4 name.rstrip('*') 5 '&&&egon$$jason'
6、切分 split :针对按照某种分隔符组织的字符串,可以用 split 将其切分成列表,然后取值。
1 data = 'egon|jason|sean and 小猴' 2 data.split('|') 3 ['egon', 'jason', 'sean and 小猴']
注意:1、按照什么分隔符来切分就会将该分隔符在字符串中取消
2、split切分出来的结果是一个列表
3、split 指定位置来切分
1 # split 指定位置切分 2 3 data.split('j') 4 ['egon|', 'ason|sean and 小猴']
补充:split()方法后面跟着两个参数,'特定字符' 和 ‘切割次数’
str1 = 'egon&jason&sean&tank&小猴' str1.split('&') ['egon', 'jason', 'sean', 'tank', '小猴'] str1.split('&',2) ['egon', 'jason', 'sean&tank&小猴']
7、循环
data = 'egon|jason|sean' for i in data: print(i)
需要掌握的
1、strip()、lstrip()、rstrip()
2、lower() upper() :将字符串全部转为小写或大写形式
1 name = ' jaSOn' 2 name.lower() 3 ' jason' 4 name.upper() 5 ' JASON'
3、startswith() 和 endswith() :判断字符串是以什么开头和以什么结尾!
1 data = 'shanghai is a cold city!' 2 data.startswith() #报错原因是 ()内必须输入一个元素来进行判断 3 Traceback (most recent call last): 4 File "<input>", line 1, in <module> 5 TypeError: startswith() takes at least 1 argument (0 given) 6 7 data.startswith('h') 8 False
4、format 的三种玩法(Python推荐用 format 做格式化输出,但是一般还是占位符 %s 使用的比较多)
a、第一种按位置占,原理和%s一样
1 str1 = "my name is {} my school is {}".format('jason','重邮') 2 print(str1) 3 my name is jason my school is 重邮
b、第二种是按索引占位 --- 该索引指的是format 括号里参数的索引
1 str1 = "my name is {2} my school is {2}".format('jason','重邮','信科') 2 print(str1) 3 my name is 信科 my school is 信科
c、指名道姓占位(关键字传参)
str1 = "my name is {name} my school is {school}".format(name='jason',school='重邮',room='信科') print(str1) my name is jason my school is 重邮
5、split() 、rsplit()
6、join() :将容器类型中的多个字符通过指定字符拼接成一个字符串
1 data = 'egon|jason|sean' 2 data.split("|") 3 ['egon', 'jason', 'sean'] 4 res =data.split("|") 5 res_1 = "$".join(res) # 使指定字符拼接 6 print(res_1) 7 egon$jason$sean
补充: 由以上程序结果可知,不同数据类型是无法拼接的,只能拼接字符串,因为程序结果就是字符串
7、replace() 替代方法
进行替代str = 'egon is a open boy!' str.replace('egon','jason') 'jason is a open boy!'
其中replace()还可以指定第几个元素进行替代 replace(self,old,new,count)
1 str1 = 'chongqing is beautiful city,and more and more cool girl want to eat chongqing huoguo!' 2 str1.replace('chongqing','shaghai',1) # 注意replace()里面的count 是从‘1’开始的, 3 'shaghai is beautiful city,and more and more cool girl want to eat chongqing huoguo!'
8、isdigit() :判断字符串中是否是纯数字
while True: age = input('>>>:') if age.isdigit(): age = int(age) if age > 28: print('阿姨好') else: print('你他妈的能不能好好输')
需要了解的内置方法
1、find() rfind() index() rindex() count
s = 'kevin is dsb o and kevin is sb' str = s.re print(s.find('dsb')) # 返回的是d字符所在的索引值 print(s.find('xxx')) # 找不到的时候不报错返回的是-1 print(s.find('i',0,3)) # 还可以通过索引来限制查找范围 print(s.index('o')) # 返回所传字符所在的索引值 print(s.index('i',0,3)) # 返回所传字符所在的索引值 print(s.count('n')) # 统计字符出现的次数
补充:find 和 index的区别
1、find 查找指定字符出现第一个字母的索引值,可以指定查找范围,如果找不到返回-1
2、index 查找指定字符出现第一个字母的索引值,可以指定查找范围,如果找不到就会报错!
str1 = 'egon&jason&sean&tank&小猴' str1.find('egon') 0 str1.find('egon',0,3) # 0~3没有索引到,返回-1 -1 str1.index('egon',0,4) # 可以看出这里的查询范围也是顾头不顾尾,0~4 0 str1.index('egon',0,3) # 报错! Traceback (most recent call last):
2、center() ljust() rjust() zfill()
s9 = 'jason' print(s9.center(12,'*')) print(s9.ljust(40,'$')) print(s9.rjust(40,'$')) print(s9.rjust(40,' ')) print(s9.zfill(40))
3、expandtables()
s10 = 'a\tbc' print(s10.expandtabs(100))
4、captalize() swapcase() title():将每个单词的首字母进行大写
s12 = 'hElLo WoRLD sH10' print(s12.capitalize()) # Hello world 文本收个单词的首字母大写 print(s12.swapcase()) # 大小写互换 print(s12.title()) # 每个单词的首字母大小
5、is系列--不太需要,用 isdigit() 即可
类型总结
1、只能存一个值
2、有序,(有序,但凡有索引的数据都是有序的)
3、不可变类型
三、列表 ---- 内部原理就是 for 循环
基本用法:
作用:容器
定义:[ ] 可以装多个任意类型的值,并用逗号分隔开
基本的内置方法:
str = 'abcf' list(str) ['a', 'b', 'c', 'f']
由上可以看出:list 内部原理就是for 循环,所以list内部必须放容器类型!
需要优先掌握的方法
1、按索引取值(正向取值,负向取值):既可存也可取。
2、切片(顾头不顾尾,步长)
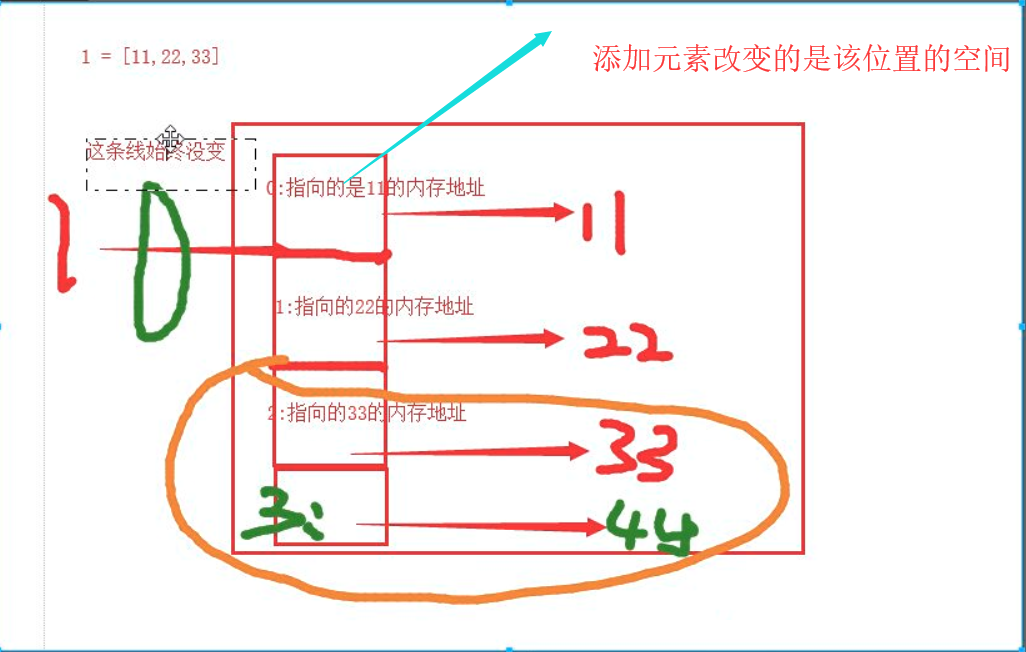
l = [1,2,3,4] print(l[0:4]) # 列表的切片 [1, 2, 3, 4] print(l[0:4:2]) # 列表按步长切片 [99, 3] print(l[0::]) # 第一个:默认到最后 第二个:默认步长为1 [1, 2, 3, 4] print(l[5::-2]) # 5大于列表索引下标无意义,6也行,只要大于最大索引值即可,反向取值,步长-2 [4, 2] print(l[6::-1]) [4, 3, 2, 1] l[0]=99 # 列表中的元素是可变的,由此退出列表是可变类型。 l [99, 2, 3, 4]
3、列表元素添加*****
a、尾部添加 append()
1 list_1 = [1,2,3,4] 2 list_1.append(99) 3 list_1 4 [1, 2, 3, 4, 99]
b、指定位置添加 insert()
list_1 = [1,2,3,4] list_1.insert(2,99) # 注意:我们添加的元素是在索引值的前面 list_1 [1, 2, 99, 3, 4]
c、添加容器,如添加列表等 用 extend()方法
list_1 = [1,2,3,4] list_2 = [33,44,77] list_1.extend(list_2) list_1 [1, 2, 3, 4, 33, 44, 77]
由上述代码可以看出,extend()方法的原理就是将list_2的元素for 循环列出来,在append 添加进list_2中
4、列表删除元素
a、del() 适用于所有的操作,直接将元素删除 del (列表名[索引值])
b、 pop() 尾部弹出元素 *****
list_1 = [1,2,3,4] list_1.pop() 4
# pop()指定位置删除元素 list_1 = [1,2,3,4] list_1.pop(2) 3
c、remove() 删除指定的元素
list_1 = [1,2,3,4] list_1.remove(3) list_1 [1, 2, 4]
5、长度计算 len()
6、成员运算 in 和 not in
7、循环 for i in list:
类型总结:
1、可以存多个值
2、有序
3、可变类型:原因!!! list 内部原理如图所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号