
python机器学习之决策树
利用决策树预测房价


1 # -*- coding: utf-8 -*- 2 from __future__ import unicode_literals 3 # 数据提供模块 4 import sklearn.datasets as sd 5 # 小工具模块 6 import sklearn.utils as su 7 import sklearn.tree as st 8 import sklearn.ensemble as se 9 # 评价模型指标模块 10 import sklearn.metrics as sm 11 12 # 获取数据 13 hosing = sd.load_boston() 14 print(hosing.data.shape) 15 # 房价 16 print(hosing.target.shape) 17 # 特征 18 print(hosing.feature_names) 19 # hosing.feature_names======》['CRIM'(犯罪情况) 'ZN'(房子密度) 'INDUS'(商铺繁华程度) 20 # 'CHAS'(是否靠河) 'NOX'(一氧化氮浓度) 'RM'(房间数) 'AGE'(年代) 'DIS'(离市中心的距离) 21 # 'RAD'(公路密度) 'TAX'(房产税) 'PTRATIO'(师生比例)'B'(黑人比例) 'LSTAT'(地位低下人比例)] 22 #'洗牌',打乱数据顺序, 23 x, y = su.shuffle(hosing.data, hosing.target, random_state=7) 24 # 确定训练集大小80%; 25 train_size = int(len(x) * 0.8) 26 # 分别拿出训练集和测试集 27 train_x, test_x, train_y, test_y = \ 28 x[: train_size], x[train_size: ], \ 29 y[: train_size], y[train_size:] 30 # 建立决策树回归器,最大高度为4层 31 model = st.DecisionTreeRegressor(max_depth=4) 32 # 构建决策树 33 model.fit(train_x, train_y) 34 # 生成预测集 35 pred_test_y = model.predict(test_x) 36 # 评判预测匹配度 37 print(sm.r2_score(test_y, pred_test_y)) 38 39 # 建立正向激励回归器 40 model = se.AdaBoostRegressor(st.DecisionTreeRegressor( 41 max_depth=4), n_estimators=400, random_state=7) 42 model.fit(train_x, train_y) 43 pred_test_y = model.predict(test_x) 44 # 评判预测匹配度 45 print(sm.r2_score(test_y, pred_test_y)) 46 47 for test, pred_test in zip(test_y, pred_test_y): 48 print(test, '->', pred_test)

特征值的重要性排序
不同的算法,对特征的认识不一样,现在对比一下决策树和正向激励的特征顺序。
1 # 评价模型指标模块 2 import sklearn.metrics as sm 3 4 import numpy as np 5 import sklearn.datasets as sd 6 import sklearn.utils as su 7 import sklearn.tree as st 8 import sklearn.ensemble as se 9 import matplotlib.pyplot as mp 10 hosing = sd.load_boston() 11 feature_names = hosing.feature_names 12 x, y = su.shuffle(hosing.data, hosing.target, random_state=7) 13 train_size = int(len(x) * 0.8) 14 train_x, test_x, train_y, test_y = \ 15 x[:train_size], x[train_size:], \ 16 y[:train_size], y[train_size:] 17 model = st.DecisionTreeRegressor(max_depth=4) 18 model.fit(train_x, train_y) 19 # 决策树特征值 20 feature_importances_dt = model.feature_importances_ 21 print(feature_importances_dt) 22 model = se.AdaBoostRegressor(st.DecisionTreeRegressor( 23 max_depth=4), n_estimators=400, random_state=7) 24 model.fit(train_x, train_y) 25 # 正向激励特征值 26 feature_importances_ab = model.feature_importances_ 27 print(feature_importances_ab) 28 29 # 作图对比 30 mp.figure('Feature Importance', facecolor='lightgray') 31 # 决策树特征顺序 32 mp.subplot(211) 33 mp.title('Decision Tree', fontsize=16) 34 mp.ylabel('Importance', fontsize=12) 35 mp.tick_params(labelsize=10) 36 mp.grid(axis='y', linestyle=':') 37 # 逆向排序索引 38 sorted_indices = feature_importances_dt.argsort()[::-1] 39 pos = np.arange(sorted_indices.size) 40 41 mp.bar(pos, feature_importances_dt[sorted_indices], 42 facecolor='deepskyblue', edgecolor='steelblue') 43 mp.xticks(pos, feature_names[sorted_indices], rotation=30) 44 45 # 正向激励决策树 46 mp.subplot(212) 47 mp.title('AdaBoost Decision Tree', fontsize=16) 48 mp.xlabel('Feature', fontsize=12) 49 mp.ylabel('Importance', fontsize=12) 50 mp.tick_params(labelsize=10) 51 mp.grid(axis='y', linestyle=':') 52 sorted_indices = feature_importances_ab.argsort()[::-1] 53 pos = np.arange(sorted_indices.size) 54 mp.bar(pos, feature_importances_ab[sorted_indices], 55 facecolor='lightcoral', edgecolor='indianred') 56 mp.xticks(pos, feature_names[sorted_indices], rotation=30) 57 58 mp.tight_layout() 59 mp.show()
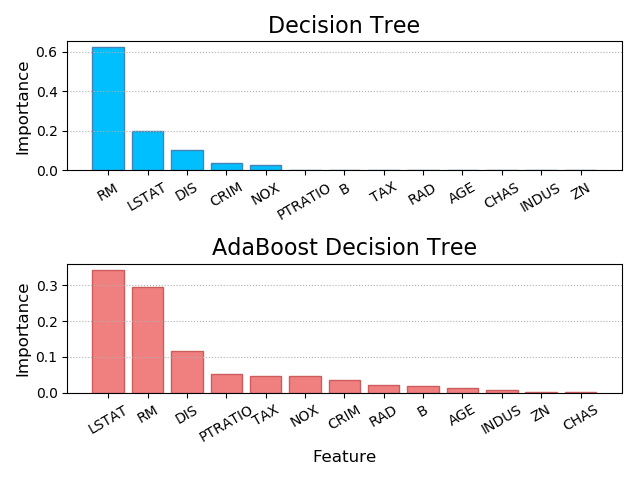
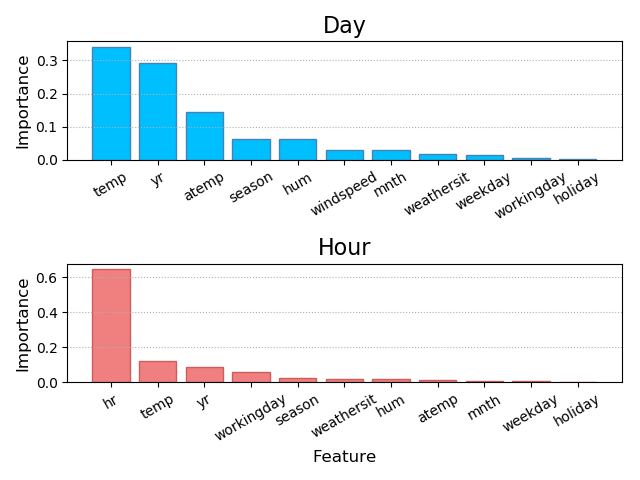
除了所选择的算法模型会对特征重要性的判断给出不同的排序以外,训练数据本身也会影响特征重要性的排列。
1 # -*- coding: utf-8 -*- 2 from __future__ import unicode_literals 3 import csv 4 import numpy as np 5 import sklearn.utils as su 6 import sklearn.ensemble as se 7 import sklearn.metrics as sm 8 import matplotlib.pyplot as mp 9 # 导入数据,单车以天为单位 10 with open('../ML/data/bike_day.csv', 'r') as f: 11 reader = csv.reader(f) 12 # x放特征,y放用户数 13 x, y = [], [] 14 for row in reader: 15 # 取前面的多个特征 16 x.append(row[2:13]) 17 # y装用户数 18 y.append(row[-1]) 19 # 取出特征名 20 feature_names_dy = np.array(x[0]) 21 # 取第一行后面的东西 22 x = np.array(x[1:], dtype=float) 23 y = np.array(y[1:], dtype=float) 24 x, y = su.shuffle(x, y, random_state=7) 25 # 取训练集90% 26 train_size = int(len(x) * 0.9) 27 train_x, test_x, train_y, test_y = \ 28 x[:train_size], x[train_size:], \ 29 y[:train_size], y[train_size:] 30 # 建立随机森林回归器 31 model = se.RandomForestRegressor( 32 max_depth=10, n_estimators=1000, min_samples_split=2) 33 model.fit(train_x, train_y) 34 feature_importances_dy = model.feature_importances_ 35 pred_test_y = model.predict(test_x) 36 print(sm.r2_score(test_y, pred_test_y)) 37 # 导入数据,单车以小时为单位 38 with open('../ML/data/bike_hour.csv', 'r') as f: 39 reader = csv.reader(f) 40 x, y = [], [] 41 for row in reader: 42 x.append(row[2:13]) 43 y.append(row[-1]) 44 feature_names_hr = np.array(x[0]) 45 x = np.array(x[1:], dtype=float) 46 y = np.array(y[1:], dtype=float) 47 x, y = su.shuffle(x, y, random_state=7) 48 train_size = int(len(x) * 0.9) 49 train_x, test_x, train_y, test_y = \ 50 x[:train_size], x[train_size:], \ 51 y[:train_size], y[train_size:] 52 model = se.RandomForestRegressor( 53 max_depth=10, n_estimators=1000, min_samples_split=2) 54 model.fit(train_x, train_y) 55 feature_importances_hr = model.feature_importances_ 56 pred_test_y = model.predict(test_x) 57 print(sm.r2_score(test_y, pred_test_y)) 58 mp.figure('Feature Importance', facecolor='lightgray') 59 mp.subplot(211) 60 mp.title('Day', fontsize=16) 61 mp.ylabel('Importance', fontsize=12) 62 mp.tick_params(labelsize=10) 63 mp.grid(axis='y', linestyle=':') 64 sorted_indices = feature_importances_dy.argsort()[::-1] 65 pos = np.arange(sorted_indices.size) 66 mp.bar(pos, feature_importances_dy[sorted_indices], 67 facecolor='deepskyblue', edgecolor='steelblue') 68 mp.xticks(pos, feature_names_dy[sorted_indices], rotation=30) 69 mp.subplot(212) 70 mp.title('Hour', fontsize=16) 71 mp.xlabel('Feature', fontsize=12) 72 mp.ylabel('Importance', fontsize=12) 73 mp.tick_params(labelsize=10) 74 mp.grid(axis='y', linestyle=':') 75 sorted_indices = feature_importances_hr.argsort()[::-1] 76 pos = np.arange(sorted_indices.size) 77 mp.bar(pos, feature_importances_hr[sorted_indices], 78 facecolor='lightcoral', edgecolor='indianred') 79 mp.xticks(pos, feature_names_hr[sorted_indices], rotation=30) 80 mp.tight_layout() 81 mp.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号