Spark项目之电商用户行为分析大数据平台之(七)数据调研--基本数据结构介绍
一、user_visit_action(Hive表)
1.1 表的结构
date:日期,代表这个用户点击行为是在哪一天发生的
user_id:代表这个点击行为是哪一个用户执行的
session_id :唯一标识了某个用户的一个访问session
page_id :点击了某些商品/品类,也可能是搜索了某个关键词,然后进入了某个页面,页面的id
action_time :这个点击行为发生的时间点
search_keyword :如果用户执行的是一个搜索行为,比如说在网站/app中,搜索了某个关键词,然后会跳转到商品列表页面;搜索的关键词
click_category_id :可能是在网站首页,点击了某个品类(美食、电子设备、电脑)
click_product_id :可能是在网站首页,或者是在商品列表页,点击了某个商品(比如呷哺呷哺火锅XX路店3人套餐、iphone 6s)
order_category_ids :代表了可能将某些商品加入了购物车,然后一次性对购物车中的商品下了一个订单,这就代表了某次下单的行为中,有哪些
商品品类,可能有6个商品,但是就对应了2个品类,比如有3根火腿肠(食品品类),3个电池(日用品品类)
order_product_ids :某次下单,具体对哪些商品下的订单
pay_category_ids :代表的是,对某个订单,或者某几个订单,进行了一次支付的行为,对应了哪些品类
pay_product_ids:代表的,支付行为下,对应的哪些具体的商品
1.2 表的说明
user_visit_action表,其实就是放,比如说网站,或者是app,每天的点击流的数据。可以理解为,用户对网站/app每点击一下,就会代表在这个表里面的一条数据。
二、user_info(Hive表)
2.1 表的结构
user_id:其实就是每一个用户的唯一标识,通常是自增长的Long类型,BigInt类型
username:是每个用户的登录名
name:每个用户自己的昵称、或者是真实姓名
age:用户的年龄
professional:用户的职业
city:用户所在的城市
2.2 表的说明
user_info表,实际上,就是一张最普通的用户基础信息表;这张表里面,其实就是放置了网站/app所有的注册用户的信息。那么我们这里也是对用户信息表,进行了一定程度的简化。比如略去了手机号等这种数据。因为我们这个项目里不需要使用到某些数据。那么我们就保留一些最重要的数据,即可。
三、task(MySQL表)
3.1 表的结构
task_id:表的主键
task_name:任务名称
create_time:创建时间
start_time:开始运行的时间
finish_time:结束运行的时间
task_type:任务类型,就是说,在一套大数据平台中,肯定会有各种不同类型的统计分析任务,比如说用户访问session分析任务,页面单跳转化率统计任务;所以这个字段就标识了每个任务的类型
task_status:任务状态,任务对应的就是一次Spark作业的运行,这里就标识了,Spark作业是新建,还没运行,还是正在运行,还是已经运行完毕
task_param:最最重要,用来使用JSON的格式,来封装用户提交的任务对应的特殊的筛选参数
3.2 表的说明
task表,其实是用来保存平台的使用者,通过J2EE系统,提交的基于特定筛选参数的分析任务,的信息,就会通过J2EE系统保存到task表中来。之所以使用MySQL表,是因为J2EE系统是要实现快速的实时插入和查询的。
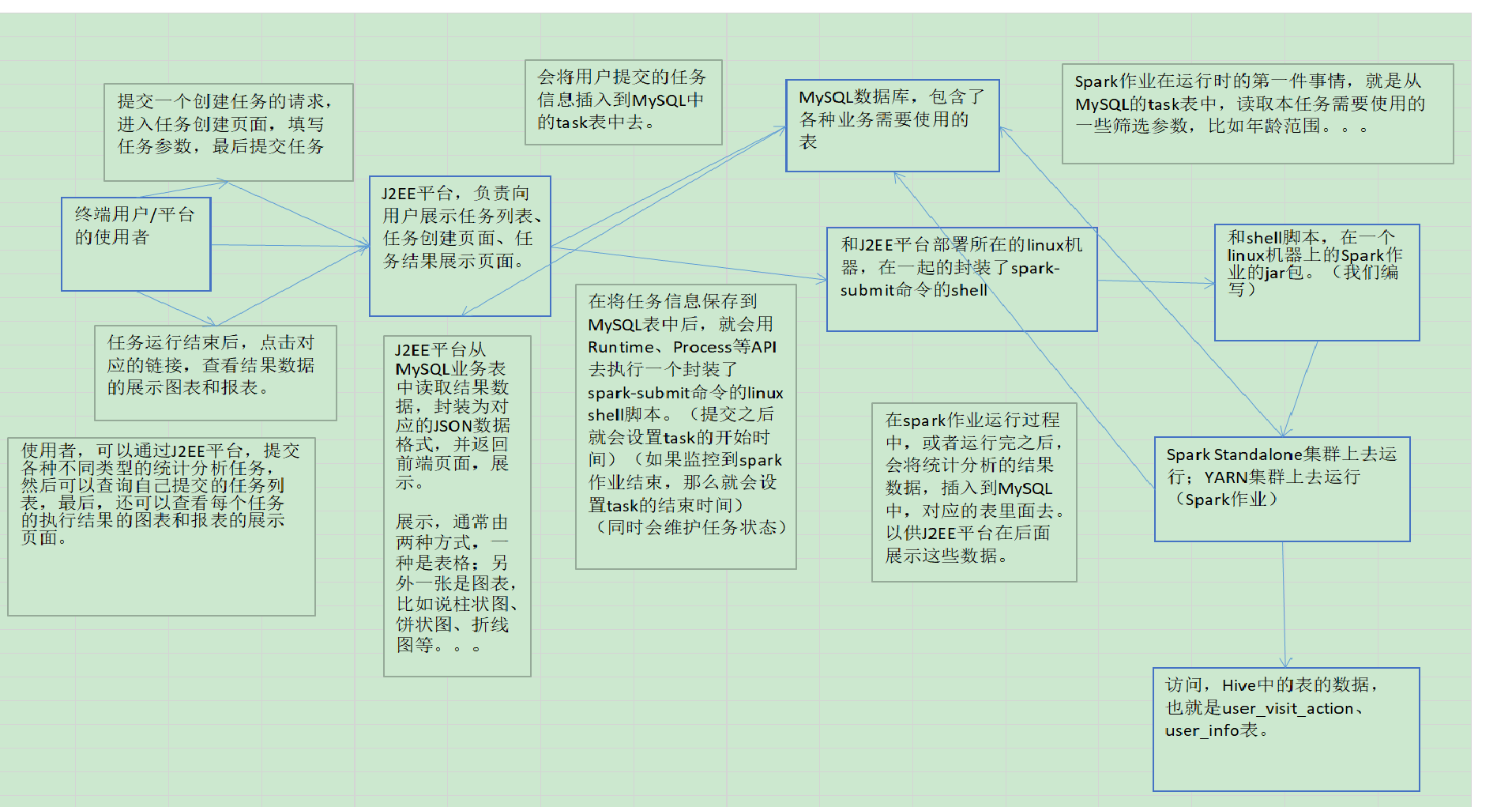
四、工作流程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号