Hive学习之路 (十八)Hive的Shell操作
一、Hive的命令行
1、Hive支持的一些命令
Command Description
quit Use quit or exit to leave the interactive shell.
set key=value Use this to set value of particular configuration variable. One thing to note here is that if you misspell the variable name, cli will not show an error.
set This will print a list of configuration variables that are overridden by user or hive.
set -v This will print all hadoop and hive configuration variables.
add FILE [file] [file]* Adds a file to the list of resources
add jar jarname
list FILE list all the files added to the distributed cache
list FILE [file]* Check if given resources are already added to distributed cache
! [cmd] Executes a shell command from the hive shell
dfs [dfs cmd] Executes a dfs command from the hive shell
[query] Executes a hive query and prints results to standard out
source FILE Used to execute a script file inside the CLI.
2、语法结构
hive [-hiveconf x=y]* [<-i filename>]* [<-f filename>|<-e query-string>] [-S]
说明:
1、-i 从文件初始化 HQL
2、-e 从命令行执行指定的 HQL
3、-f 执行 HQL 脚本
4、-v 输出执行的 HQL 语句到控制台
5、-p connect to Hive Server on port number
6、-hiveconf x=y(Use this to set hive/hadoop configuration variables)
7、-S:表示以不打印日志的形式执行命名操作
3、示例
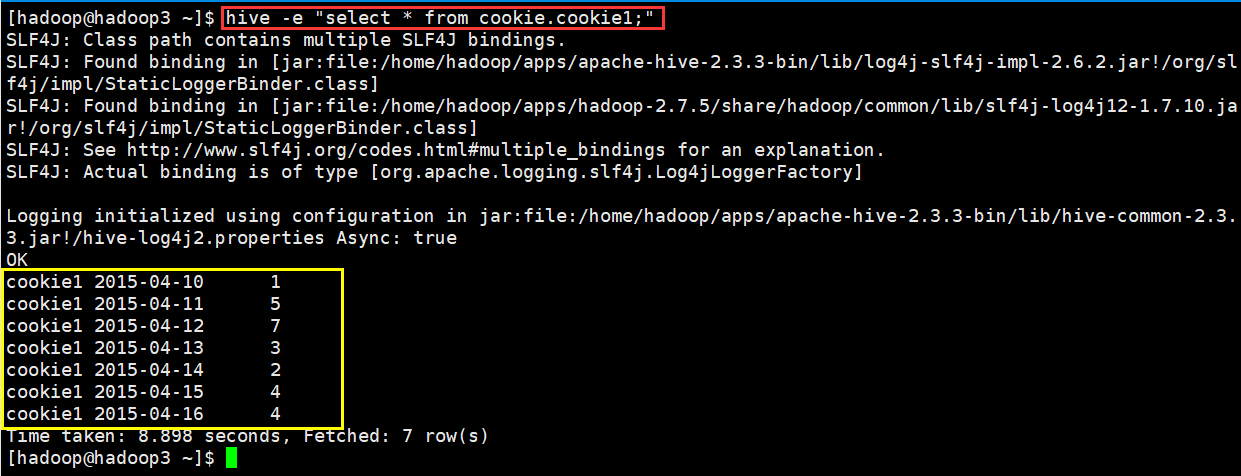
(1)运行一个查询
[hadoop@hadoop3 ~]$ hive -e "select * from cookie.cookie1;"
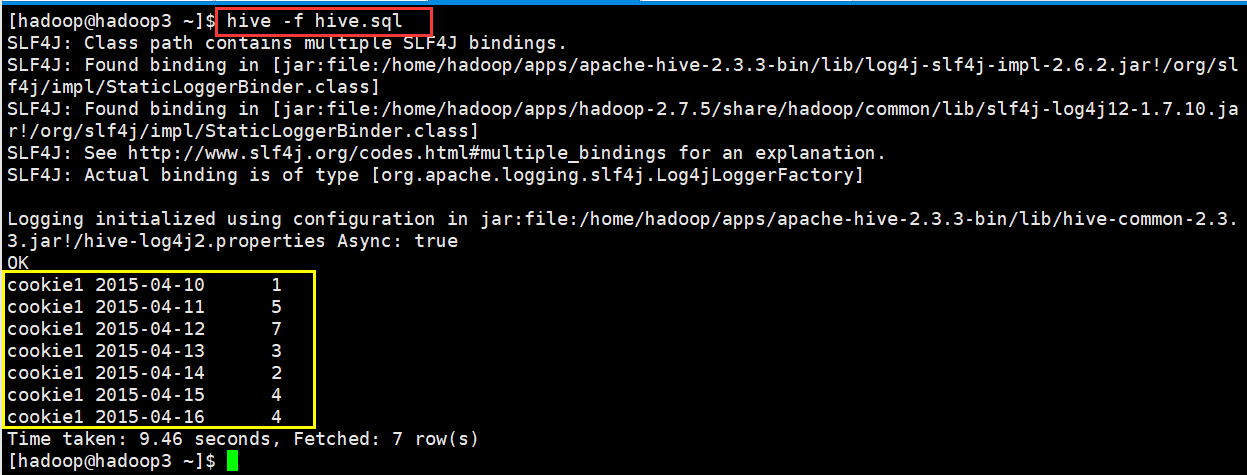
(2)运行一个文件
编写hive.sql文件

运行编写的文件
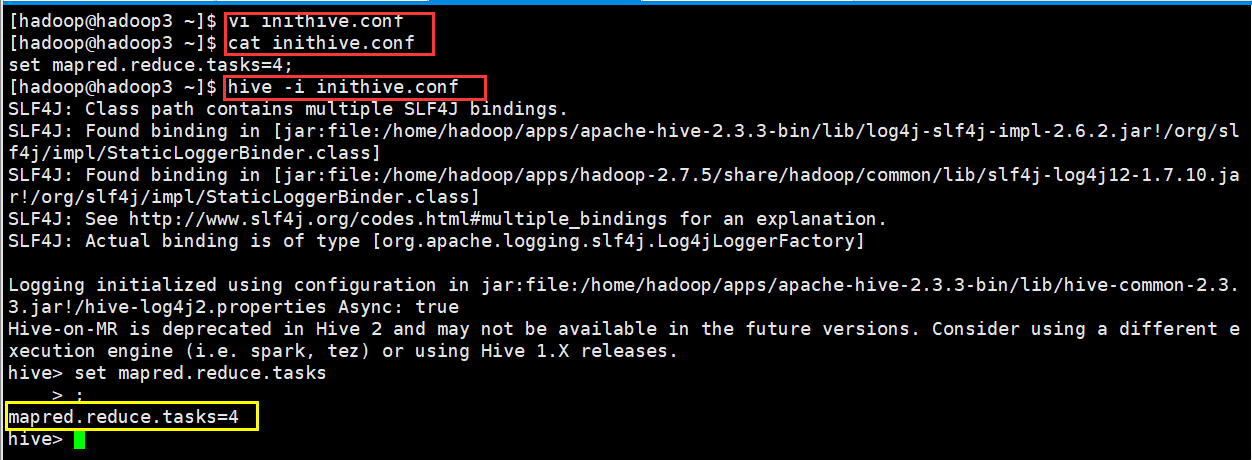
(3)运行参数文件
从配置文件启动 hive,并加载配置文件当中的配置参数
二、Hive的参数配置方式
1、Hive的参数配置大全
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
2、Hive的参数设置方式
开发 Hive 应用时,不可避免地需要设定 Hive 的参数。设定 Hive 的参数可以调优 HQL 代码 的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么设定的参数没有 起作用?这通常是错误的设定方式导致的
对于一般参数,有以下三种设定方式:
1、配置文件 (全局有效)
2、命令行参数(对 hive 启动实例有效)
3、参数声明 (对 hive 的连接 session 有效)
(1)配置文件
Hive 的配置文件包括:
A. 用户自定义配置文件:$HIVE_CONF_DIR/hive-site.xml
B. 默认配置文件:$HIVE_CONF_DIR/hive-default.xml
用户自定义配置会覆盖默认配置。
另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配 置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。
(2)命令行参数
启动 Hive(客户端或 Server 方式)时,可以在命令行添加-hiveconf param=value 来设定参数,例如:
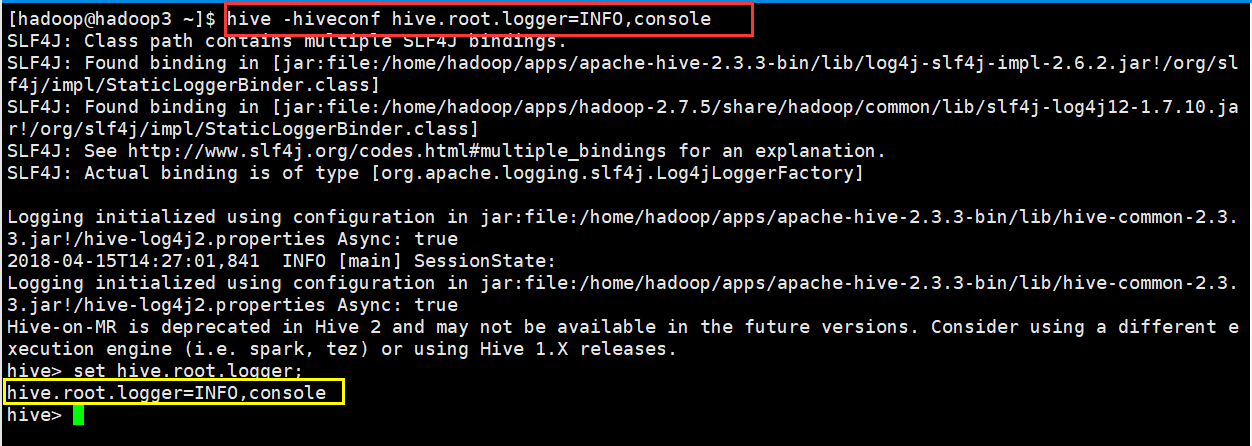
这一设定对本次启动的 session(对于 server 方式启动,则是所有请求的 session)有效。
(3)参数声明
可以在 HQL 中使用 SET 关键字设定参数,例如:
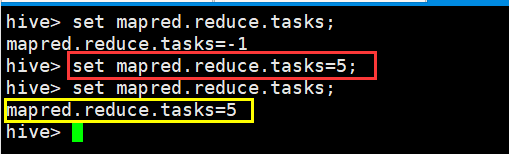
这一设定的作用域也是 session 级的。
set hive.exec.reducers.bytes.per.reducer= 每个 reduce task 的平均负载数据量 Hive 会估算总数据量,然后用该值除以上述参数值,就能得出需要运行的 reduceTask 数
set hive.exec.reducers.max= 设置 reduce task 数量的上限
set mapreduce.job.reduces= 指定固定的 reduce task 数量
但是,这个参数在必要时<业务逻辑决定只能用一个 reduce task> hive 会忽略,比如在设置 了 set mapreduce.job.reduces = 3,但是 HQL 语句当中使用了 order by 的话,那么就会忽略该参数的设置。
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置 文件设定。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为 那些参数的读取在 session 建立以前已经完成了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号